Parallellprogrammering og Sortering INF nov. 2015
|
|
|
- Ida Våge
- 7 år siden
- Visninger:
Transkript
1 Parallellprogrammering og Sortering INF nov Kode til H-radix (om igjen) Effekten av caching på kjøretider Problemer med parallellisering på Multicore CPU (MPU). Parallell sortering 2 algoritmer: - QuickSort (gradvis parallell) - LeftRadix (full parallell) Testresultater Arne Maus, PSE, Ifi
2 Innledende kode for å radix-sortere på to siffer: static void radix2(int [] a) { // 2 digit radixsort: a[ ] int max = 0, numbit = 2; for (int i = 0 ; i < a.length; i++) if (a[i] > max) max = a[i]; // determine number of bits in max while (max >= 1<<numBit) numbit++; int bit1 = numbit/2, bit2 = numbit-bit1; } int[] b = new int [a.length]; radixsort( a,b, bit1, 0); radixsort( b,a, bit2, bit1); 2
3 Ett element i fra[]: bit 31 0 static void radixsort (int [] a, int [] b, int masklen, int shift){ int acumval = 0, j; int mask = (1<<maskLen) -1; int [] count = new int [mask+1]; masklen shift // a)count=the frequency of each radix value in a for (int i = 0; i <a.length; i++) count[(a[i]>> shift) & mask]++; mask = masklen 1 ere // b) Add up in 'count' - accumulated values for (int i = 0; i <= mask; i++) { j = count[i]; count[i] = acumval; acumval += j; } // c) move numbers in sorted order a to b for (int i = 0; i < a.length; i++) b[count[(a[i]>>shift) & mask]++] = a[i]; } /* end radixsort */ 3
4 Tidsforbruket til RR HøyreRadix 1. Først går vi gjennom a[] for å finne max = O(n) 2. Legg merke til at ant[] har lengde rmax = 1023 en konstant 3. Følgende operasjoner gjøres (log max)/(log rmax) ganger: 1. Tell opp i ant[] hvor mange det er av hver siffer-verdi = O(n) 2. Juster pekere i ant[] = O(log rmax ) 3. Flytte alle n data (fra: fra[] til: til[]) = O(n) 4. Dvs totalt O(n log max), og siden max ofte er en funksjon av n, blir dette ofte O(n logn) men koeffisienten er meget liten 5. Radix er vel dobbelt så rask som Quicksort i praksis, men krever dobbelt så stor plass 6. Hovegrunnen til at Radix er så rask at den aksesserer hvert element langt færre ganger enn Quicksort (når n = 1 mill, gjør Quicksort ca. 20 les/skriv per element, Radix gjør ca. 7) 4
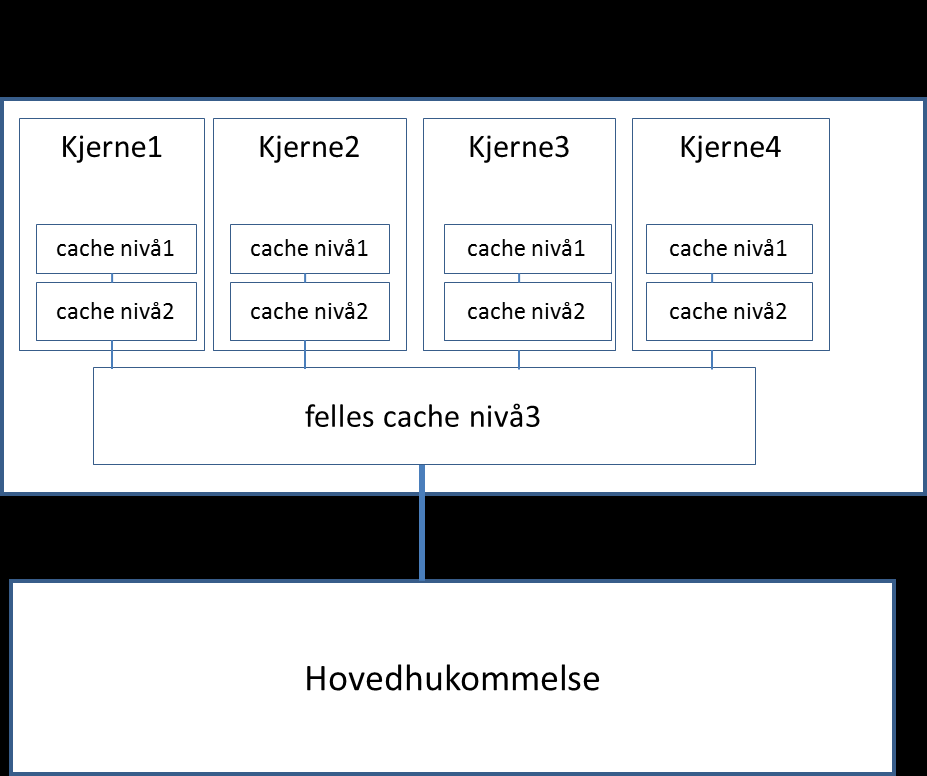
5 Hva er caching (hurtiglagre)? Nivå 1 (32 Kb) og nivå 2 (256 Kb), én per kjerne felles nivå 3 cache, 8 MB, én for alle kjernene Når vi ikke finner data i nærmeste cache, overføres en cachelinje = 64 Byte fra saktere til raskere hukommelse. Kjerne Kjerne2 CPU med 2 kjerner Lokalnett Disk 5

6 6
7 Sammenligning av algoritmer Tree-sort Quick-sort effektivisert med Innstikksortering for subdeler < 40 Radix Minst signifikant siffer først, 2 pass (hvis nødvendig) 10 bit fast siffer 7
8 Noen tider millisekunder (2005) n Tree - sort ,5 12,97 0,9540 0,0657 0,0046 Radix - sort ,98 0,2030 0,0250 0,0036 Quick - sort ,4 6,88 0,5010 0,0375 0,0020 millisek Absolutte sorteringstider n Tree - sort Bøtte - sort Radix - sort PSort Quick - sort 8
9 Random /sequential test (AMD Opteron), Radix 1, 2 and 3 compared withquicksort and Flashsort Opteron Ghz - Uniform(0:n-1) distr. radix1 slowed down by a factor 7 Relative performance to Quicksort(=1) Java Arrays.sort (Quick) :RRadix - 1pass :RRadix - 2pass :RRadix - 3pass FlashSort - 1pass n (log scale) radix2, slowdown started radix3, no slowdown 9
, that performs almost 3 (2) times as many instructions as radix1, is 4-5 times as fast as radix1 for large n. i.e. radix1 experiences a slowdown of factor 7-10 because of cache-misses 1.")
10 Conclusions The effects of cache-misses are real and show up in ordinary user algorithms when doing random access in large arrays. We have demonstrated that radix3 (and radix2), that performs almost 3 (2) times as many instructions as radix1, is 4-5 times as fast as radix1 for large n. i.e. radix1 experiences a slowdown of factor 7-10 because of cache-misses 1. The number of instructions executed is no longer a good measure for the performance of an algorithm. 2. Algorithms should be rewritten such that random access in large data structures is removed. 10
11 1) Parallelle algoritmer - hvorfor Litt fra INF2440 : Praktisk parallellprogrammering: Vi vil ha raskere algoritmer, også sortering! Vi har nå flere prosessorkjerner, burde alle programmer bruke disse. N.B. Amdahls lov : Tenk deg at algoritmen din har en del på p% (eks. 20%) av kjøretiden som må kjøres sekvensielt og resten kan gjøres i parallell. 11
12 Amdahls lov : Med p% sekvensiell kode er det raskeste du kan forbedre din algoritmen din er 100/p ganger (eks. 100/20 =5). Uansett hvordan du parallelliserer og uansett hvor mange maskiner du har, fordi den parallelle koden kan aldri gå raskere enn på 0,000.. sekunder Den sekvensielle delen vil derfor alltid gi deg en begrensning, og må gjøres minst mulig. Med k prosessorer er mulig Speedup (= ganger raskere), S: Sekvensiell tid 100 S =, S 3.33 med p = 20, k = Parallell tid 100 p p + k 8 Dette er ikke nødvendigvis sannheten. Gustafson (med sin lov) hevder at den sekvensielle %-andelen synker når problemet blir større. Amdahl er ikke fast sier Gustafson. 12
13 To typer av maskiner Felles hukommelse Alle kjernene leser/skriver i felles hukommelse i én maskin (= en vanlig maskin, smarttelefon eller laptop) Begrenset hukommelse 8-64 GB Rask (2-64 kjerner) Noe vanskelig programmering Distribuert hukommelse Som Abel-klyngen med ca 600 PC-er med til sammen kjerner som er koblet sammen med raske switcher (1-3 µsek: hukommelse til hukommelse) ca 100 ganger så langsomt som Felles hukommelse Kan løse større problemer Verdens største har vel kjerner (i Kina) Ganske vanskelig programmering 13


 I år (2015): 62 100")
14 MPU Multicore CPU Intel selger nå Xeon Phi med 62core CPU AMD 4Core Tilgjengelig i 2010 : 2-16 core CPU (Intel og AMD) I år (2015): core CPU 14

15 Intel Xeon Phi 62 prosessorer på en brikke (2014) 15
16 II) Flere problemer med parallellitet med tråder i Java 1. Operasjoner blandes (oppdateringer går tapt). 2. Oppdaterte verdier til felles data er ikke alltid synlig fra alle tråder (oppdateringer er ikke synlige når du trenger dem). 3. Synlighet har ofte med cache å gjøre. 4. The Java memory model (= hva skjer egentlig når du kjører et Java-program). 16
17 Løsningen Vi må finne på skuddsikre måter å programmere parallelle programmer De er kanskje ikke helt tidsoptimale Men de er lettere å bruke!! Det er vanskelig nok likevel. Bare oversiktelige, enkle måter å programmere parallelt er mulig i praksis 17
18 II) Parallelle algoritmer operasjoner blandes,; eksempel: i++ programmet Samtidig oppdatering i++; er 3 operasjoner: a) les i, b) legg til 1, c) skriv i tilbake Anta i =2, og to tråder gjør i++ Vi kan få svaret 3 eller 4 (skulle fått 4!) Dette skjer i praksis! Les i Legg til 1 Skriv i tilbake tråd Les i Legg til 1 Skriv i tilbake tråd tiden 18
19 Test på i++ parallellisert Setter i gang n tråder (på en 2 kjerner CPU) som alle prøver å øke med 1 en felles variabel int i; ganger uten synkronisering; for (int j =0; j< ; j++) { i++; } Vi fikk følgende feil - antall og %, (manglende verdier).merk: Resultatene varierer også mye mellom hver kjøring : Antall tråder n Svar 1.gang 2. gang Tap 1.gang 2. gang 0 % 0% 0% 20,4% 35,5% 14,6% 15,3% 17,7% 14,9% 17,5% 19
20 2) Optimalisering i Java, omordning av instruksjoner, For å få raskere kode, byttes det ofte om på den kompilerte koden: eks.: y = 17; x = 5; z = x + 3; Selv om vi ser at x er 5, behøver ikke y å være lik 17, fordi vi ikke trenger noen verdi på y enda. Hvis programmet går raskere, utsettes tilordningen av 17 til y (til den trenges i en beregning med y eller i en utskrift). Det eneste vi garanteres av kompilatoren er at den kjører et program som gir samme resultat som om vi utførte setningene slik de står i Java-koden en etter en, ovenfra og nedover. Altså: Bak kullissene utføres koden i en uforutsigbar rekkefølge for at koden for én tråd skal gå raskest. 20
21 - Lesing: Når vi ikke finner data i nærmeste cache, overføres en cachelinje = 64 Byte fra saktere til raskere hukommelse. - Kanskje må vi da lese eller skrive data helt ned i hukommelsen -CPUen leser/skriver bare til cache level 1. 3) Caching kan gi problemer, Nivå 1 (32 Kb) og nivå 2 (256 Kb), én per kjerne hva er det? CPU med 2 kjerner felles nivå 3 cache, 8 MB, én for alle kjernene Lokalnett - Både data og instruksjoner caches (vi ser bare på data her) Disk 21
22 Hva er caching (hurtiglagre)? Nivå 1 (32 Kb) og nivå 2 (256 Kb), én per kjerne felles nivå 3 cache, 8 MB, én for alle kjernene Når vi ikke finner data i nærmeste cache, overføres en cachelinje = 64 Byte fra saktere til raskere hukommelse CPU med 2 kjerner Lokalnett Disk 22

23 Effekten av caching i 2007 hvor lang tid tar det å lese/skrive i de ulike cachene & hukommelsen? 23
24 Hvordan virker cache inn på parallelle beregninger En tråd på én CPU kan oppdatere en variabel i, men leser/skriver nye verdier av i bare til f.eks level 1 eller 2 cache (det kommer ingen oppdaterte verdier i hukommelsen). Andre tråder som vil lese i får da lest gamle verdier ikke de nye verdiene. Selv om en tråd på core 1 skriver verdier av beregninger ned i hukommelsen, tar det ca. 250 cycler, og der er god nok tid til at en annen tråd på en annen core k leser gamle verdier lenge etter at nye verdier har blitt beregnet og skrevet. 24
25 Effekten av caching hvor stor? CPU: Intel Core Duo E GHz - år 2007 Fem nivåer av hukommelse CPU Intel i GHz år 2015 Tidsforbruk (antall cycler) for les/skriv Register på CPU 1 Level 1 cache 3 Level 2 cache 15 Level 3 cache 46 Hovedhukommelsen ca. 250 latency.exe: 3 cache levels detected Level 1 size = 32Kb latency = 3 cycles Level 2 size = 256Kb latency = 9 cycles Level 3 size = 8192Kb latency = 36 cycles main mem., size= 8 Gb, latency = 152 cycles 25
26 Så mange problemer Trådene kan flette beregninger. Kompilatoren bytter om på instruksjonene. Cachen gjør at ulike tråder kan lese gamle verdier av variable lenge etter at de er oppdatert i en annen tråd. + At det tar lang tid, ca. 3 millisekunder å starte noen få tråder (på den tida kan man sortere ca tall) Er det mulig å lage riktige og raskere parallell sortering? 26
27 Synkronisering + faste regler kan løse problemene. 1. Vi må sperre ut alle tråder unntatt én fra å skrive på noen av de felles variable samtidig. Og da må ingen andre tråder samtidig lese disse felles variablene. 2. Vi må sørge for at alle verdier blir synlige for de tråder som trenger å lese dem (de må være skrevet og nådd fram til der andre tråder kan lese dem hukommelsen, når de skal leses). Løsning: A. Har lært: synkroniserte metoder (litt langsom og passer ikke alltid til problemet): synchronized void addi() { i ++; } B. Det er mulig selv å sørge for at 1) og 2) ovenfor overholdes. Bruk semaforer eller barrier-synkronisering - kan løse 2) ovenfor Sørg selv ved hvordan du programmerer at 1) overfor gjelder mellom hver synkronisering. 27
28 Synkroniseringsvariable generelt Tråder som skal synkroniseres, gjør et kall på samme synkroniseringsvariabel (barrier eller semafor). Da skjer: Alle instruksjoner over synkroniserings-kallet i koden vil bli ferdig utført før synkroniseringskallet ingen utsatte operasjoner. Alle verdier på felles variable som er endret av trådene vil være tilgjengelig og synlig i felles hukommelse når kallet blir utført. Dvs. innholdet i alle cachene som har blitt endret, blir skrevet ned i hovedhukommelsen som et resultat av kall på en synkroniseringsvariabel. 28
29 Semaforer & Barrier synkronisering Hovedfunksjonen til synkroniserings-variable er å : Stoppe tråder som ikke kan fortsette Starte igjen stoppede tråder når en-eller- annen bra tilstand har oppstått. Semaphore og CyclicBarrier er klasser i Java API:. import java.util.concurrent.*; 29
30 Barrier: n tråder kaller på en felles barriere-variabel og de n-1 første må vente. Først når alle trådene har kalt variabelen, forstsetter de Kallet: barrier.await(); Nyttes når alle har har utført en del-beregning. Så må alle stoppes og først startes når alle er ferdige med delberegningen. (de må komme i takt ) Når alle da startes, kan de lese hva alle de andre har beregnet før synkroniseringen. barrier = new CyclicBarrier(numThreads); Cyclic betyr at etter første vente-situasjonen, kan en slik barriere nyttes omigjen for en ny venting med alle trådene. 30
31 Semafor I prinsippet to operasjoner : acquire(); Ta én tillatelse Er det 0 eller færre tillatelser i semaforen, må man vente til man får en (levert tilbake av en annen tråd). release(); Gi tilbake en tillatelse. Hvis antall tillatelser nå blir 1, vekkes en evt. ventende tråd opp, og antallet ledige tillatelser blir 0, ellers økes antall tillatelse med 1. Initieres med negativt, 0 eller positivt antall tillatelser. -k+1 gir at en tråd kan vente på venter på at k andre tråder sier release(). completed = new Semaphore(-numThreads+1); 31
32 Felles : main-tråden Main-tråden må starte parallell-beregningene, Så legge seg og vente. Så vekkes opp når alle parallell-trådene er ferdig. main legger seg og venter på en semafor som alle trådene sier release(); på. Hvis den har initielt: - antalltråder + 1 tillatelser, vil main-tråden slippe løs når alle er ferdige. Finne antall kjerner i maskinen: Runtime r = Runtime.getRuntime(); int numcore = r.availableprocessors(); 32
33 Parallell Quicksort 1. Bestem først hvor mange tråder vi vil ha (= 2 k -1) 1,3,7,..2 k -1 tråder. 2. main-tråden starter én tråd som gjør vanlig, sekvensiell oppdeling av a[] i to deler som vanlig Quicksort. 3. Main legger seg så og venter på en semafor. 4. Start så en tråd for å sortere for hver av disse to delene. 5. Disse starter så hver sine to tråder, osv. inntil vi har startet det antall tråder vi har bestemt oss for. 6. Deretter vil hver tråd på vanlig, rekursiv, sekvensiell måte sortere hver sin del og si release() på main s ventesemafor når de er ferdige. Treets høyde h = 3 har elementer main-tråden = start tråd 33
34 Litt drøfting, parallell Quicksort Hver tråd skriver bare i de delene den eier selv, og ingen andre tråder leser heller disse. Siden main synkroniseres via en semafor med alle trådene den starter, vet vi at den kan se alle de sorterte elementene i a[] når den vekkes opp. Vi har i altså oppfylt 1) og 2) kravet og vel så det. Litt langsom fordi første oppdelingen ikke er parallell, neste oppdeling kan kjøre bare 2-parallell, så 4-parallell osv. - jfr. Amdahls lov. 34
35 Parallell LRadix Sekvensiell LRadix(ALR): 1. Finn max i a[] 2. Tell opp hvor mange av hver verdi: 0..2 numbit -1 av det siffer vi sorterer på. 3. Disse antallene summereres i arrayene point og border 4. Finn første uflyttede element i perm-sykler til alle tall er flyttet. 5. Rekursivt kall for hver verdi av det sifferet vi har sortert på, for neste siffer. Parallell LRadix (PLR) 1. Bestem avtall tråder (numthreads) 2. Del opp arrayen i numthreads like deler. 1. main starter numthreads tråder. 2. Hver tråd i bestemme max i sin del og lagrer den i felles array maxval[i]. 3. Barriere-vent alle tråder. 4. Hver tråd leser hele maxval[] og finner globalt max. 5. Alle tråder sorterer med ARL sin del, og tråd i henger sin border[] array inn i felles array allborders[i][]. 6. Barriere-vent alle tråder. 7. Tråd i eier nå hver sin n/numthreads - del av verdiene. Kopierer de delene av a[] hvor de er etter hva som står i alle allborders[][] over i lokal array b[] i hver tråd. 8. Alle trådene sorter sin b[] med ALR på de resterende sifrene rekursivt på hver av verdiene den eier. 9. Barriere-vent alle tråder. 10. Alle tråder kopier tilbake lokal b[] til den delen av a[] hvor de skal stå. 11. Alle tråder kaller release(); på main-trådens ventesemafor. 35
36 a[ ]: tråd 0 tråd 1 tråd 2 tråd 3 maxval 1,2 Finn & skriv: maxval[0] Finn & skriv: maxval[1] Finn & skriv: maxval[2] Finn & skriv: maxval[3] Finn samme max: les: maxval[0..3] les: maxval[0..3] les: maxval[0..3] les: maxval[0..3] barrier sync. allborders 3-5 Sorter hver sin del: Returner border[ ]: Sorter på første siffer sin del av a[] returner border[] kopier til lokal b[] sin del av sifferverdiene i a[]: sorter lokal b[] med ALR. kopier b[] til riktig sted i a[] Sorter på første siffer sin del av a[] returner border[] kopier til lokal b[] sin del av sifferverdiene i a[]: sorter lokal b[] med ALR. kopier b[] til riktig sted i a[] Sorter på første siffer sin del av a[] returner border[] kopier til lokal b[] sin del av sifferverdiene i a[]: sorter lokal b[] med ALR. kopier b[] til riktig sted i a[] Sorter på første siffer sin del av a[] returner border[] kopier til lokal b[] sin del av sifferverdiene i a[]: sorter lokal b[] med ALR. kopier b[] til riktig sted i a[] barrier sync. barrier sync. Semafor sync. 36
37 Barriere vent try { barrier.await(); } catch (InterruptedException ex) { return; } catch (BrokenBarrierException ex) { return; } 37
![Å starte numthreads tråder - besvergelser class ParaSort{ int [] maxval; int [] a ; int [][] allborders final CyclicBarrier barrier; final Semaphore completed; // konstruktør public ParaSort(int []a,](/docs-images/61/46168123/images/38-1.png "int numthreads) { // Her kjører bare main-tråden this.")
38 Å starte numthreads tråder - besvergelser class ParaSort{ int [] maxval; int [] a ; int [][] allborders final CyclicBarrier barrier; final Semaphore completed; // konstruktør public ParaSort(int []a, int numthreads) { // Her kjører bare main-tråden this.a = a; // arrayen som skal sorteres barrier = new CyclicBarrier(numThreads); completed = new Semaphore(-numThreads+1); maxval = new int [numthreads]; // main start numthreads tråder for (int i = 0; i < numthreads; ++i) new Thread(new Worker (numthreads,i)). start(); waituntildone(); } } class Worker implements Runnable { int minindex; Worker(int numthreads, int i) { minindex =i; } public void run() { // her kjører numthreads tråder <hele PLR sorteringa med 3x barrier.await(); og avsluttet med : completed.release();> } // end run } // end indre klasse Worker } // end klasse void waituntildone(){ // kalles bare av main-tråden en gang. try {completed.acquire(); } catch (InterruptedException ex) { return; } } // end waituntildone 38
39 % relativt til Arrays.sort parallelle og 3 sekvensielle sorteringsalgoritmer (Dell Intel Core i7-4 core, 2,67GHz) tider i % relativt til sekvensiell Quicksort Arrays,sort QuickParallel ArlSequential ARlParallel FletteSort ParaFlette n 39
40 3 sekvensielle - 2 parallelle sortingingsalgoritmer AMD Opteron core (4 core hyperthread) Exec. time relative to Arrays.sort = sekvensielle - 2 parallelle sortingingsalgoritmer Arrays,sort OJDquickSort QuickParallel ArlSequential ARlParallel n - length of array 40
41 Relative to Arrays.sort =100 ( log scale) Relative execution times on a 32(64) core server: Intel Xenon L7555 1,87GHz, Dell PowerEdge M910 (lower is better) Arrays,sort Quick Parallel Arl Sequential PARL n (log scale) 41
42 Analyse (I) Vi ser at parallell ALR (PLR) er: ca x raskere enn Arrays.sort på en 64 core maskin (n: 1-50 mill ) ca. 5x raskere enn Arrays.sort generelt, (n> 1 mill) ca. 2-4x raskere enn parallell Quicksort ca. 2x raskere enn sekv. ALR med 4 core ca.4x raskere enn sekv. ARL med 4/8 core Parallell Quicksort er: 2x raskere enn OJ Dahls Quicksort uansett antall core Hvorfor ikke bedre speedup? 42
43 Hvorfor ikke 4x, 8x og 64x raskere? Vi gjør en ekstra kopiering av det vi skal sortere i PLR (til lokale b[] og tilbake) En beregning er ikke raskere enn sin langsomste del Sortering gjør få operasjoner i CPUen, men leser ofte i hukommelsen. Vi vet ikke hvor rask hukommelsenforbindelsen er på de to CPUene: Kanskje er den en flaskehals? AMD har/hadde raskere hukommelse-kanal enn Intel. Kanskje derfor skalerer AMD bedre enn Intel. 43
44 Konklusjoner Parallell sortering skalerer bra, og særlig: PLR som ikke har noen sekvensiell del og er relativt sett 2x så rask med 2x antall core. Parallell Quick har ikke samme speedup, og på grunn av sin sekvensielle del, vil neppe bli særlig raskere med 50 eller 100 core. Parallell programmering er ikke så vanskelig. Programmeringsmønstre som: En skriver og ingen andre leser; så synkroniser ; så kan andre tråder lese; Er helt avgjørende for å få riktig kode. MER: INF2440 våren
7) Radix-sortering sekvensielt kode og effekten av cache
 Radix-sortering sekvensielt kode og effekten av cache") ) Radix-sortering sekvensielt kode og effekten av cache Dels er denne gjennomgangen av vanlig Radix-sortering viktig for å forstå en senere parallell versjon. Dels viser den effekten vi akkurat så tilfeldig
) Radix-sortering sekvensielt kode og effekten av cache Dels er denne gjennomgangen av vanlig Radix-sortering viktig for å forstå en senere parallell versjon. Dels viser den effekten vi akkurat så tilfeldig
INF NOV PARALLELL SORTERING. Arne Maus, PSE, Ifi
 INF2220-2. NOV. 2017 PARALLELL SORTERING Arne Maus, PSE, Ifi 2 Dagens forelesning Hva er et parallelt program med tråder (i Java) Typer av parallelle programmer her vil vi ha raskere programmer Hva er
INF2220-2. NOV. 2017 PARALLELL SORTERING Arne Maus, PSE, Ifi 2 Dagens forelesning Hva er et parallelt program med tråder (i Java) Typer av parallelle programmer her vil vi ha raskere programmer Hva er
UNIVERSITETET I OSLO
 UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i: INF2440 Effektiv parallellprogrammering Eksamensdag: 2. juni 2015 Tidspunkter: 09.00 13.00 Oppgavesettet er på: 3 sider + 2 sider
UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i: INF2440 Effektiv parallellprogrammering Eksamensdag: 2. juni 2015 Tidspunkter: 09.00 13.00 Oppgavesettet er på: 3 sider + 2 sider
INF2440, Uke 3, våren2015 Regler for parallelle programmer, mer om cache og Radix-algoritmen. Arne Maus OMS, Inst. for informatikk
 INF2440, Uke 3, våren2015 Regler for parallelle programmer, mer om cache og Radix-algoritmen Arne Maus OMS, Inst. for informatikk 1 Hva har vi sett på i Uke2 I) Tre måter å avslutte tråder vi har startet.
INF2440, Uke 3, våren2015 Regler for parallelle programmer, mer om cache og Radix-algoritmen Arne Maus OMS, Inst. for informatikk 1 Hva har vi sett på i Uke2 I) Tre måter å avslutte tråder vi har startet.
INF2440 Uke 4, våren2014 Avsluttende om matrisemultiplikasjon og The Java Memory Model + bedre forklaring Radix. Arne Maus OMS, Inst.
 INF Uke, våren Avsluttende om matrisemultiplikasjon og The Java Memory Model + bedre forklaring Radix Arne Maus OMS, Inst. for informatikk Hva så vi på i uke. Presisering av hva som er pensum. Samtidig
INF Uke, våren Avsluttende om matrisemultiplikasjon og The Java Memory Model + bedre forklaring Radix Arne Maus OMS, Inst. for informatikk Hva så vi på i uke. Presisering av hva som er pensum. Samtidig
INF2440, Uke 3, våren2014 Regler for parallelle programmer, mer om cache og Radix-algoritmen. Arne Maus OMS, Inst. for informatikk
 INF2440, Uke 3, våren2014 Regler for parallelle programmer, mer om cache og Radix-algoritmen Arne Maus OMS, Inst. for informatikk 1 Hva har vi sett på i Uke2 I) Tre måter å avslutte tråder vi har startet.
INF2440, Uke 3, våren2014 Regler for parallelle programmer, mer om cache og Radix-algoritmen Arne Maus OMS, Inst. for informatikk 1 Hva har vi sett på i Uke2 I) Tre måter å avslutte tråder vi har startet.
INF2440 Uke 4, v2017 Om å samle parallelle svar, matrisemultiplikasjon og The Java Memory Model + evt bedre forklaring Radix
 INF Uke, v7 Om å samle parallelle svar, matrisemultiplikasjon og The Java Memory Model + evt bedre forklaring Radix Arne Maus PSE, Inst. for informatikk Hva så vi på i uke. Presisering av hva som er pensum.
INF Uke, v7 Om å samle parallelle svar, matrisemultiplikasjon og The Java Memory Model + evt bedre forklaring Radix Arne Maus PSE, Inst. for informatikk Hva så vi på i uke. Presisering av hva som er pensum.
INF2440 Uke 4, v2015 Om å samle parallelle svar, matrisemultiplikasjon og The Java Memory Model + evt bedre forklaring Radix
 INF Uke, v Om å samle parallelle svar, matrisemultiplikasjon og The Java Memory Model + evt bedre forklaring Radix Arne Maus PSE, Inst. for informatikk Hva så vi på i uke. Presisering av hva som er pensum.
INF Uke, v Om å samle parallelle svar, matrisemultiplikasjon og The Java Memory Model + evt bedre forklaring Radix Arne Maus PSE, Inst. for informatikk Hva så vi på i uke. Presisering av hva som er pensum.
INF2440 Uke 6, våren2014 Mer om oppdeling av et problem for parallellisering, mye om primtall + thread-safe. Arne Maus OMS, Inst.
 INF2440 Uke 6, våren2014 Mer om oppdeling av et problem for parallellisering, mye om primtall + thread-safe Arne Maus OMS, Inst. for informatikk 1 Oppsummering Uke1 Vi har gjennomgått hvorfor vi får flere-kjerne
INF2440 Uke 6, våren2014 Mer om oppdeling av et problem for parallellisering, mye om primtall + thread-safe Arne Maus OMS, Inst. for informatikk 1 Oppsummering Uke1 Vi har gjennomgått hvorfor vi får flere-kjerne
INF2440 Uke 12, v2014. Arne Maus OMS, Inst. for informatikk
 INF2440 Uke 12, v2014 Arne Maus OMS, Inst. for informatikk 1 Fra hjemmesida til INF2440: To trykkfeil rettet i Oblig3 Rediger 1) Stegene i algoritmene ble i koden referert som a,b,c,c - skal selvsagt være:
INF2440 Uke 12, v2014 Arne Maus OMS, Inst. for informatikk 1 Fra hjemmesida til INF2440: To trykkfeil rettet i Oblig3 Rediger 1) Stegene i algoritmene ble i koden referert som a,b,c,c - skal selvsagt være:
UNIVERSITETET I OSLO
 UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Prøveeksamen i : INF2440 Praktisk parallell programmering Prøveeksamensdag : 26. mai 2014 Tidspunkter: 11.00 Utdeling av prøveeksamen 15:15
UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Prøveeksamen i : INF2440 Praktisk parallell programmering Prøveeksamensdag : 26. mai 2014 Tidspunkter: 11.00 Utdeling av prøveeksamen 15:15
UNIVERSITETET I OSLO
 UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i: INF2440 Effektiv parallellprogrammering Eksamensdag: 2. juni 2015 Tidspunkter: 09.00 13.00 Oppgavesettet er på: 3 sider + 2 sider
UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i: INF2440 Effektiv parallellprogrammering Eksamensdag: 2. juni 2015 Tidspunkter: 09.00 13.00 Oppgavesettet er på: 3 sider + 2 sider
INF2440 Prøveeksamen, løsningsforslag, 20 mai Arne Maus PSE, Inst. for informatikk
 INF2440 Prøveeksamen, løsningsforslag, 20 mai 2015 Arne Maus PSE, Inst. for informatikk 1 Prøveeksamen Er en modell av hva du får til eksamen: - like mange (+-1) oppgaver som eksamen og nesten samme type
INF2440 Prøveeksamen, løsningsforslag, 20 mai 2015 Arne Maus PSE, Inst. for informatikk 1 Prøveeksamen Er en modell av hva du får til eksamen: - like mange (+-1) oppgaver som eksamen og nesten samme type
INF2220 høsten 2017, 12. okt.
 INF høsten 7,. okt. Sortering (kap. 7.) sekvensiell sortering I Arne Maus, Gruppen for Programmering og Software Engineering (PSE) Inst. for informatikk, Univ i Oslo Essensen av INF Lære et sett av gode
INF høsten 7,. okt. Sortering (kap. 7.) sekvensiell sortering I Arne Maus, Gruppen for Programmering og Software Engineering (PSE) Inst. for informatikk, Univ i Oslo Essensen av INF Lære et sett av gode
I et Java-program må programmøren lage og starte hver tråd som programmet bruker. Er dette korrekt? Velg ett alternativ
 INF2440-V18 Information INF2440 Vår 2018 eksamen Dato og tid: 11. juni 2018 09:00. Varighet: 4 timer Hjelpemidler: Alt skriftlig materiale er tillatt. Ingen elektroniske hjelpemidler er tillatt. Powerpoint
INF2440-V18 Information INF2440 Vår 2018 eksamen Dato og tid: 11. juni 2018 09:00. Varighet: 4 timer Hjelpemidler: Alt skriftlig materiale er tillatt. Ingen elektroniske hjelpemidler er tillatt. Powerpoint
Prøveeksamen INF2440 v Arne Maus PSE, Inst. for informatikk
 Prøveeksamen INF2440 v 2016 Arne Maus PSE, Inst. for informatikk 1 Oppgave 1 (10 poeng) Forklar hva som skjer ved en synkronisering: a) Når to tråder synkroniserer på samme synkroniseringsobjekt (f.eks
Prøveeksamen INF2440 v 2016 Arne Maus PSE, Inst. for informatikk 1 Oppgave 1 (10 poeng) Forklar hva som skjer ved en synkronisering: a) Når to tråder synkroniserer på samme synkroniseringsobjekt (f.eks
INF3030, Uke 3, våren 2019 Regler for parallelle programmer, mer om cache og Matrise-multiplikasjon. Arne Maus / Eric Jul PSE, Inst.
 INF3030, Uke 3, våren 2019 Regler for parallelle programmer, mer om cache og Matrise-multiplikasjon Arne Maus / Eric Jul PSE, Inst. for informatikk 1 Hva har vi sett på i Uke2 Én stygg feil vi kan gjøre:
INF3030, Uke 3, våren 2019 Regler for parallelle programmer, mer om cache og Matrise-multiplikasjon Arne Maus / Eric Jul PSE, Inst. for informatikk 1 Hva har vi sett på i Uke2 Én stygg feil vi kan gjøre:
INF2440 Uke 11, v2014 om parallell debugging og Goldbachs problem, om Oblig 3. Arne Maus OMS, Inst. for informatikk
 INF2440 Uke 11, v2014 om parallell debugging og Goldbachs problem, om Oblig 3 Arne Maus OMS, Inst. for informatikk 1 Fra hjemmesida til INF2440: Plan for resten av semesteret: Forelesninger: 28.mars (i
INF2440 Uke 11, v2014 om parallell debugging og Goldbachs problem, om Oblig 3 Arne Maus OMS, Inst. for informatikk 1 Fra hjemmesida til INF2440: Plan for resten av semesteret: Forelesninger: 28.mars (i
INF2440 Eksamen 2016 løsningsforslag. Arne Maus, PSE ifi, UiO
 INF2440 Eksamen 2016 løsningsforslag Arne Maus, PSE ifi, UiO 1 Oppgave 1 (10 poeng) a) Beskriv meget kortfattet de to viktigste egenskapene ved tråder i et Java-program. 1. En tråd er sekvensielt programdel
INF2440 Eksamen 2016 løsningsforslag Arne Maus, PSE ifi, UiO 1 Oppgave 1 (10 poeng) a) Beskriv meget kortfattet de to viktigste egenskapene ved tråder i et Java-program. 1. En tråd er sekvensielt programdel
Kap 19. Mer om parallelle programmer i Java og Kvikksort
 Arne Maus, 5.april 2011: Kap 19. Mer om parallelle programmer i Java og Kvikksort Parallell programmering er vanskelig, og det er derfor utviklet flere synkroniseringsmåter og biblioteker for mer strukturert
Arne Maus, 5.april 2011: Kap 19. Mer om parallelle programmer i Java og Kvikksort Parallell programmering er vanskelig, og det er derfor utviklet flere synkroniseringsmåter og biblioteker for mer strukturert
INF2440 Uke 5, våren2015 Om oppdeling av et problem for parallellisering, mye om primtall + thread-safe. Arne Maus PSE, Inst.
 INF2440 Uke 5, våren2015 Om oppdeling av et problem for parallellisering, mye om primtall + thread-safe Arne Maus PSE, Inst. for informatikk 1 Oppsummering Uke1 Vi har gjennomgått hvorfor vi får flere-kjerne
INF2440 Uke 5, våren2015 Om oppdeling av et problem for parallellisering, mye om primtall + thread-safe Arne Maus PSE, Inst. for informatikk 1 Oppsummering Uke1 Vi har gjennomgått hvorfor vi får flere-kjerne
INF2220 høsten 2017, 19. okt.
 INF2220 høsten 2017, 19. okt. Sortering (kap. 7.) sekvensiell sortering II Arne Maus, Gruppen for Programmering og Software Engineering (PSE) Inst. for informatikk, Univ i Oslo 1 Hva lærte vi for en uke
INF2220 høsten 2017, 19. okt. Sortering (kap. 7.) sekvensiell sortering II Arne Maus, Gruppen for Programmering og Software Engineering (PSE) Inst. for informatikk, Univ i Oslo 1 Hva lærte vi for en uke
UNIVERSITETET I OSLO
 UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Prøveeksamen i: INF2440 Effektiv parallellprogrammering Prøveeksamensdag: 1. juni 2016 Tidspunkter: 09.00 16.00 Oppgavesettet er på: 4 sider
UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Prøveeksamen i: INF2440 Effektiv parallellprogrammering Prøveeksamensdag: 1. juni 2016 Tidspunkter: 09.00 16.00 Oppgavesettet er på: 4 sider
INF2440 Uke 8, v2016 : Om Oblig 3 - radixsortering, Ulike Threadpools, JIT-kompilering. Arne Maus PSE, Inst. for informatikk
 INF Uke 8, v : Om Oblig - radixsortering, Ulike Threadpools, JIT-kompilering Arne Maus PSE, Inst. for informatikk Om inf våren Gruppetimer denne uka, men ikke neste uke eller. påskedag (8. mars) Ukeoppgaver
INF Uke 8, v : Om Oblig - radixsortering, Ulike Threadpools, JIT-kompilering Arne Maus PSE, Inst. for informatikk Om inf våren Gruppetimer denne uka, men ikke neste uke eller. påskedag (8. mars) Ukeoppgaver
INF2220 høsten 2015, 5. nov.
 INF høsten,. nov. Sortering del I (kap. 7.) Arne Maus, Gruppen for Programmering og Software Engineering (PSE) Inst. for informatikk, Univ i Oslo Essensen av kurset Lære et sett av gode (og noen få dårlige)
INF høsten,. nov. Sortering del I (kap. 7.) Arne Maus, Gruppen for Programmering og Software Engineering (PSE) Inst. for informatikk, Univ i Oslo Essensen av kurset Lære et sett av gode (og noen få dårlige)
UNIVERSITETET I OSLO
 UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i: INF2440 Effektiv parallellprogrammering Eksamensdag: 7. juni 2016 Tidspunkter: 09.00 13.00 Oppgavesettet er på: 3 sider + 1 side
UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i: INF2440 Effektiv parallellprogrammering Eksamensdag: 7. juni 2016 Tidspunkter: 09.00 13.00 Oppgavesettet er på: 3 sider + 1 side
INF2440 Uke 9, v2017 : Om Oblig 3 - radixsortering, Ulike Threadpools, JIT-kompilering. Arne Maus PSE, Inst. for informatikk
 INF Uke 9, v7 : Om Oblig - radixsortering, Ulike Threadpools, JIT-kompilering Arne Maus PSE, Inst. for informatikk Om inf våren 7 Ingen undervisning (forelesning eller gruppetimer i påsken (. 7. april).
INF Uke 9, v7 : Om Oblig - radixsortering, Ulike Threadpools, JIT-kompilering Arne Maus PSE, Inst. for informatikk Om inf våren 7 Ingen undervisning (forelesning eller gruppetimer i påsken (. 7. april).
INF2440 Uke 10, v2018 : Arne Maus PSE, Inst. for informatikk
 INF2440 Uke 10, v2018 : Arne Maus PSE, Inst. for informatikk 1 Hva så på i uke 9: Et sitat om tidsforbruk ved faktorisering Om en feil i Java ved tidtaking (tid == 0??) Hvordan parallellisere rekursive
INF2440 Uke 10, v2018 : Arne Maus PSE, Inst. for informatikk 1 Hva så på i uke 9: Et sitat om tidsforbruk ved faktorisering Om en feil i Java ved tidtaking (tid == 0??) Hvordan parallellisere rekursive
INF2220 høsten 2016, 9. nov.
 INF høsten, 9. nov. Sortering del I (kap. 7.) Arne Maus, Gruppen for Programmering og Software Engineering (PSE) Inst. for informatikk, Univ i Oslo Essensen av kurset Lære et sett av gode (og noen få dårlige)
INF høsten, 9. nov. Sortering del I (kap. 7.) Arne Maus, Gruppen for Programmering og Software Engineering (PSE) Inst. for informatikk, Univ i Oslo Essensen av kurset Lære et sett av gode (og noen få dårlige)
UNIVERSITETET I OSLO
 UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i : INF2440 Praktisk parallell programmering Eksamensdag : 2. juni 2014 Tidspunkter: 14.30 Oppgavesettet er på : 4 sider Vedlegg
UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i : INF2440 Praktisk parallell programmering Eksamensdag : 2. juni 2014 Tidspunkter: 14.30 Oppgavesettet er på : 4 sider Vedlegg
INF2440 Effektiv parallellprogrammering Uke 1, våren Arne Maus PSE, Inst. for informatikk
 INF2440 Effektiv parallellprogrammering Uke 1, våren 2017 Arne Maus PSE, Inst. for informatikk 1 Hva vi skal lære om i dette kurset: Lage parallelle programmer (algoritmer) som er: Riktige Parallelle programmer
INF2440 Effektiv parallellprogrammering Uke 1, våren 2017 Arne Maus PSE, Inst. for informatikk 1 Hva vi skal lære om i dette kurset: Lage parallelle programmer (algoritmer) som er: Riktige Parallelle programmer
INF1010 Tråder II 6. april 2016
 INF1010 Tråder II 6. april 2016 Stein Gjessing Universitetet i Oslo 1 Tråder i Java tråden minrunp class MinRun implements Runable { MinRun(... ) {... } public void run( ) {...... } } //end
INF1010 Tråder II 6. april 2016 Stein Gjessing Universitetet i Oslo 1 Tråder i Java tråden minrunp class MinRun implements Runable { MinRun(... ) {... } public void run( ) {...... } } //end
MER OM PARALLELLE PROGRAMMER I JAVA OG KVIKKSORT
 {Arne Maus, 23. mai 2011 Kapittel 19 MER OM PARALLELLE PROGRAMMER I JAVA OG KVIKKSORT Parallell programmering er vanskelig, og det er derfor utviklet flere synkroniseringsmåter og biblioteker for mer strukturert
{Arne Maus, 23. mai 2011 Kapittel 19 MER OM PARALLELLE PROGRAMMER I JAVA OG KVIKKSORT Parallell programmering er vanskelig, og det er derfor utviklet flere synkroniseringsmåter og biblioteker for mer strukturert
INF2220 høsten okt. og 12. okt.
 INF2220 høsten 2009 5. okt. og 12. okt. Noe om matematiske bevis (kap. 1) Sortering del I og II (kap. 7.) Arne Maus, Gruppen for objektorientering, modellering og språk (OMS) Inst. for informatikk, Univ
INF2220 høsten 2009 5. okt. og 12. okt. Noe om matematiske bevis (kap. 1) Sortering del I og II (kap. 7.) Arne Maus, Gruppen for objektorientering, modellering og språk (OMS) Inst. for informatikk, Univ
INF2440 Effektiv parallellprogrammering Uke 1, våren Arne Maus PSE, Inst. for informatikk
 INF2440 Effektiv parallellprogrammering Uke 1, våren 2016 Arne Maus PSE, Inst. for informatikk 1 Hva vi skal lære om i dette kurset: Lage parallelle programmer (algoritmer) som er: Riktige Parallelle programmer
INF2440 Effektiv parallellprogrammering Uke 1, våren 2016 Arne Maus PSE, Inst. for informatikk 1 Hva vi skal lære om i dette kurset: Lage parallelle programmer (algoritmer) som er: Riktige Parallelle programmer
Tråder Repetisjon. 9. og 13. mai Tråder
 Tråder Repetisjon 9. og 13. mai Tråder Hva er tråder? 2 Hva er tråder? I utgangspunktet uavhengige aktiviteter som konkurrerer om å få bruke prosessoren. 2 Hvorfor tråder? 3 Hvorfor tråder? Flere oppgaver
Tråder Repetisjon 9. og 13. mai Tråder Hva er tråder? 2 Hva er tråder? I utgangspunktet uavhengige aktiviteter som konkurrerer om å få bruke prosessoren. 2 Hvorfor tråder? 3 Hvorfor tråder? Flere oppgaver
INF2440 Uke 7, våren2017. Arne Maus PSE, Inst. for informatikk
 INF2440 Uke 7, våren2017 Arne Maus PSE, Inst. for informatikk 1 Hva så vi på i uke 6 1. Hva er raskest: Modell2 eller Modell3 kode? 2. Avslutning om matrisemultiplikasjon 1. Radvis (ikke kolonnevis) beregning
INF2440 Uke 7, våren2017 Arne Maus PSE, Inst. for informatikk 1 Hva så vi på i uke 6 1. Hva er raskest: Modell2 eller Modell3 kode? 2. Avslutning om matrisemultiplikasjon 1. Radvis (ikke kolonnevis) beregning
Java PRP brukermanual
 Java PRP brukermanual 1.1 Introduksjon 1.1.1 Hva er Java PRP Java PRP (Parallel Recursive Procedure) gir oss muligheten til automatisk parallellisering av programmer, som baserer seg på noen rekursive
Java PRP brukermanual 1.1 Introduksjon 1.1.1 Hva er Java PRP Java PRP (Parallel Recursive Procedure) gir oss muligheten til automatisk parallellisering av programmer, som baserer seg på noen rekursive
Arne Maus OMS, Inst. for informatikk
 INF2440 Uke 5, våren2014 Sluttkommentarer om Matrisemultiplikasjon, Modellkode for parallelle systemer, Vranglås + evt. Oppdeling av et problem for parallellisering Arne Maus OMS, Inst. for informatikk
INF2440 Uke 5, våren2014 Sluttkommentarer om Matrisemultiplikasjon, Modellkode for parallelle systemer, Vranglås + evt. Oppdeling av et problem for parallellisering Arne Maus OMS, Inst. for informatikk
INF2440 Uke 11, v2015 om parallell debugging og Goldbachs problem, om Oblig 2,3 og 4. Arne Maus PSE, Inst. for informatikk
 INF2440 Uke 11, v2015 om parallell debugging og Goldbachs problem, om Oblig 2,3 og 4 Arne Maus PSE, Inst. for informatikk 1 Fra hjemmesida til INF2440: Plan for resten av semesteret: Forelesninger: 8.
INF2440 Uke 11, v2015 om parallell debugging og Goldbachs problem, om Oblig 2,3 og 4 Arne Maus PSE, Inst. for informatikk 1 Fra hjemmesida til INF2440: Plan for resten av semesteret: Forelesninger: 8.
INF2440 Uke 14, v2015. Arne Maus PSE, Inst. for informatikk
 INF2440 Uke 14, v2015 Arne Maus PSE, Inst. for informatikk 1 Resten av INF2440 v2015 Denne forelesningen uke14 Mer om hvordan parallellisere ulike problemer 6.mai forelesning uke15 Oppsummering av pensum,
INF2440 Uke 14, v2015 Arne Maus PSE, Inst. for informatikk 1 Resten av INF2440 v2015 Denne forelesningen uke14 Mer om hvordan parallellisere ulike problemer 6.mai forelesning uke15 Oppsummering av pensum,
Tråder Repetisjon. 9. og 13. mai Tråder
 Tråder Repetisjon 9. og 13. mai Tråder Hva er tråder? 2 Hva er tråder? I utgangspunktet uavhengige aktiviteter som konkurrerer om å få bruke prosessoren. 2 Hvorfor tråder? 3 Hvorfor tråder? Flere oppgaver
Tråder Repetisjon 9. og 13. mai Tråder Hva er tråder? 2 Hva er tråder? I utgangspunktet uavhengige aktiviteter som konkurrerer om å få bruke prosessoren. 2 Hvorfor tråder? 3 Hvorfor tråder? Flere oppgaver
INF2440 Uke 10, v2014 : Arne Maus OMS, Inst. for informatikk
 INF2440 Uke 10, v2014 : Arne Maus OMS, Inst. for informatikk 1 Hva så vi på i uke 9 Et sitat om tidsforbruk ved faktorisering En presisering av Oblig2. Om en feil i Java ved tidtaking (tid == 0??) Hvor
INF2440 Uke 10, v2014 : Arne Maus OMS, Inst. for informatikk 1 Hva så vi på i uke 9 Et sitat om tidsforbruk ved faktorisering En presisering av Oblig2. Om en feil i Java ved tidtaking (tid == 0??) Hvor
INF2440 Uke 7, våren2015. Arne Maus PSE, Inst. for informatikk
 INF2440 Uke 7, våren2015 Arne Maus PSE, Inst. for informatikk 1 Hva så vi på i Uke (4,5 og) 6 1. Kommentarer til svar på ukeoppgaven om matrisemultiplikasjon 1. Hvorfor disse gode resultatene (speedup
INF2440 Uke 7, våren2015 Arne Maus PSE, Inst. for informatikk 1 Hva så vi på i Uke (4,5 og) 6 1. Kommentarer til svar på ukeoppgaven om matrisemultiplikasjon 1. Hvorfor disse gode resultatene (speedup
Fig1. Den konvekse innhyllinga av 100 tilfeldige punkter i planet (de samme som nyttes i oppgaven.)
") Oblig3 i INF2440 våren 2015-ver3. Den konvekse innhyllinga til en punktmengde - et rekursivt geometrisk problem. Innleveringsfrist fredag 27. mars kl. 23.59 En punktmengde P i planet består av n forskjellige
Oblig3 i INF2440 våren 2015-ver3. Den konvekse innhyllinga til en punktmengde - et rekursivt geometrisk problem. Innleveringsfrist fredag 27. mars kl. 23.59 En punktmengde P i planet består av n forskjellige
Løsningsforslag for Obligatorisk Oppgave 2. Algoritmer og Datastrukturer ITF20006
 Løsningsforslag for Obligatorisk Oppgave 2 Algoritmer og Datastrukturer ITF20006 Lars Vidar Magnusson Frist 28.02.14 Den andre obligatoriske oppgaven tar for seg forelesning 5, 6, og 7 som dreier seg om
Løsningsforslag for Obligatorisk Oppgave 2 Algoritmer og Datastrukturer ITF20006 Lars Vidar Magnusson Frist 28.02.14 Den andre obligatoriske oppgaven tar for seg forelesning 5, 6, og 7 som dreier seg om
INF2440 Uke 13, v2015. Arne Maus PSE, Inst. for informatikk
 INF2440 Uke 13, v2015 Arne Maus PSE, Inst. for informatikk 1 Hva så vi på i Uke 12 I) Om «siffere» i Om Oblig 4 II) Om optimalisering av Oblig2 nye tall med Java8 III) Java8 Forbedringer Feilen med tidtaking
INF2440 Uke 13, v2015 Arne Maus PSE, Inst. for informatikk 1 Hva så vi på i Uke 12 I) Om «siffere» i Om Oblig 4 II) Om optimalisering av Oblig2 nye tall med Java8 III) Java8 Forbedringer Feilen med tidtaking
INF2440 Uke 10, v2017 : Arne Maus PSE, Inst. for informatikk
 INF2440 Uke 10, v2017 : Arne Maus PSE, Inst. for informatikk 1 Hva skal vi se på i uke 9: 1. Om oblig3 generell Radix-sortering (MultiRadix) Dette er en variant av Radix-sortering som automatisk prøver
INF2440 Uke 10, v2017 : Arne Maus PSE, Inst. for informatikk 1 Hva skal vi se på i uke 9: 1. Om oblig3 generell Radix-sortering (MultiRadix) Dette er en variant av Radix-sortering som automatisk prøver
Innhold. Forord Det første programmet Variabler, tilordninger og uttrykk Innlesing og utskrift...49
 Innhold Forord...5 1 Det første programmet...15 1.1 Å kommunisere med en datamaskin 16 1.2 Programmeringsspråk 17 1.3 Et program som skriver på skjermen 18 1.4 Kompilering og kjøring 19 1.5 Kommentarer
Innhold Forord...5 1 Det første programmet...15 1.1 Å kommunisere med en datamaskin 16 1.2 Programmeringsspråk 17 1.3 Et program som skriver på skjermen 18 1.4 Kompilering og kjøring 19 1.5 Kommentarer
Først litt praktisk info. Sorteringsmetoder. Nordisk mesterskap i programmering (NCPC) Agenda
 Agenda") Først litt praktisk info Sorteringsmetoder Gruppeøvinger har startet http://selje.idi.ntnu.no:1234/tdt4120/gru ppeoving.php De som ikke har fått gruppe må velge en av de 4 gruppende og sende mail til algdat@idi.ntnu.no
Først litt praktisk info Sorteringsmetoder Gruppeøvinger har startet http://selje.idi.ntnu.no:1234/tdt4120/gru ppeoving.php De som ikke har fått gruppe må velge en av de 4 gruppende og sende mail til algdat@idi.ntnu.no
Hvor raskt klarer vi å sortere?
 Sortering Sorteringsproblemet Gitt en array med n elementer som kan sammenlignes med hverandre: Finn en ordning (eller permutasjon) av elementene slik at de står i stigende (evt. avtagende) rekkefølge
Sortering Sorteringsproblemet Gitt en array med n elementer som kan sammenlignes med hverandre: Finn en ordning (eller permutasjon) av elementene slik at de står i stigende (evt. avtagende) rekkefølge
INF2440 Uke 10, v2016 : Arne Maus PSE, Inst. for informatikk
 INF2440 Uke 10, v2016 : Arne Maus PSE, Inst. for informatikk 1 Hva så vi på i uke 9 Et sitat om tidsforbruk ved faktorisering Om en feil i Java 7 ved tidtaking Hvordan parallellisere rekursive algoritmer
INF2440 Uke 10, v2016 : Arne Maus PSE, Inst. for informatikk 1 Hva så vi på i uke 9 Et sitat om tidsforbruk ved faktorisering Om en feil i Java 7 ved tidtaking Hvordan parallellisere rekursive algoritmer
INF2440 Uke 8, v2015 : Om Oblig 3, Ulike Threadpools, JIT-kompilering. Arne Maus PSE, Inst. for informatikk
 INF2440 Uke 8, v2015 : Om Oblig 3, Ulike Threadpools, JIT-kompilering Arne Maus PSE, Inst. for informatikk 1 Hva har vi sett på i uke 7 1. Mer om matrisemultiplikasjon 1. Radvis (ikke kolonnevis) beregning
INF2440 Uke 8, v2015 : Om Oblig 3, Ulike Threadpools, JIT-kompilering Arne Maus PSE, Inst. for informatikk 1 Hva har vi sett på i uke 7 1. Mer om matrisemultiplikasjon 1. Radvis (ikke kolonnevis) beregning
Logaritmiske sorteringsalgoritmer
 Logaritmiske sorteringsalgoritmer Logaritmisk sortering Rekursive og splitt og hersk metoder: Deler verdiene i arrayen i to (helst) omtrent like store deler i henhold til et eller annet delingskriterium
Logaritmiske sorteringsalgoritmer Logaritmisk sortering Rekursive og splitt og hersk metoder: Deler verdiene i arrayen i to (helst) omtrent like store deler i henhold til et eller annet delingskriterium
Algoritmer - definisjon
 Algoritmeanalyse Algoritmer - definisjon En algoritme er en beskrivelse av hvordan man løser et veldefinert problem med en presist formulert sekvens av et endelig antall enkle, utvetydige og tidsbegrensede
Algoritmeanalyse Algoritmer - definisjon En algoritme er en beskrivelse av hvordan man løser et veldefinert problem med en presist formulert sekvens av et endelig antall enkle, utvetydige og tidsbegrensede
Sorteringsproblemet. Gitt en array A med n elementer som kan sammenlignes med hverandre:
 Sortering Sorteringsproblemet Gitt en array A med n elementer som kan sammenlignes med hverandre: Finn en ordning (eller permutasjon) av elementene i A slik at de står i stigende (evt. avtagende) rekkefølge
Sortering Sorteringsproblemet Gitt en array A med n elementer som kan sammenlignes med hverandre: Finn en ordning (eller permutasjon) av elementene i A slik at de står i stigende (evt. avtagende) rekkefølge
Sortering med tråder - Quicksort
 Sortering med tråder - Quicksort Skisser til to programmer INF1010 våren 2016 Stein Gjessing Institutt for informatikk Universitetet i Oslo Sortering som tema, slikt som valg av sorteringsmetode, hastigheten
Sortering med tråder - Quicksort Skisser til to programmer INF1010 våren 2016 Stein Gjessing Institutt for informatikk Universitetet i Oslo Sortering som tema, slikt som valg av sorteringsmetode, hastigheten
IN1010 våren Repetisjon av tråder. 15. mai 2018
 IN1010 våren 2018 Repetisjon av tråder 15. mai 2018 Stein Gjessing,, Universitetet i Oslo 1 Tråder Datamaskinarkitektur prosessor registre cache 1 cache 2 prosessor registre cache 1 Disk System-bus Minne
IN1010 våren 2018 Repetisjon av tråder 15. mai 2018 Stein Gjessing,, Universitetet i Oslo 1 Tråder Datamaskinarkitektur prosessor registre cache 1 cache 2 prosessor registre cache 1 Disk System-bus Minne
Heap* En heap er et komplett binært tre: En heap er også et monotont binært tre:
 Heap Heap* En heap er et komplett binært tre: Alle nivåene i treet, unntatt (muligens) det nederste, er alltid helt fylt opp med noder Alle noder på nederste nivå ligger til venstre En heap er også et
Heap Heap* En heap er et komplett binært tre: Alle nivåene i treet, unntatt (muligens) det nederste, er alltid helt fylt opp med noder Alle noder på nederste nivå ligger til venstre En heap er også et
Hvordan en prosessor arbeider, del 1
 Hvordan en prosessor arbeider, del 1 Læringsmål Kompilator, interpret og maskinkode CPU, registre Enkle instruksjoner: de fire regnearter Mer informasjon om temaet Internett Lokalnett (LAN) Mitt program
Hvordan en prosessor arbeider, del 1 Læringsmål Kompilator, interpret og maskinkode CPU, registre Enkle instruksjoner: de fire regnearter Mer informasjon om temaet Internett Lokalnett (LAN) Mitt program
IN1010. Fra Python til Java. En introduksjon til programmeringsspråkenes verden Dag Langmyhr
 IN1010 Fra Python til Java En introduksjon til programmeringsspråkenes verden dag@ifi.uio.no Oversikt Introduksjon Python Java Noe er likt Noe bare ser anderledes ut Noe er helt forskjellig Et par eksempler
IN1010 Fra Python til Java En introduksjon til programmeringsspråkenes verden dag@ifi.uio.no Oversikt Introduksjon Python Java Noe er likt Noe bare ser anderledes ut Noe er helt forskjellig Et par eksempler
INF2440 Effektiv parallellprogrammering Uke 2 -, våren2015 - tidtaking. Arne Maus PSE, Inst. for informatikk
 INF2440 Effektiv parallellprogrammering Uke 2 -, våren2015 - tidtaking Arne Maus PSE, Inst. for informatikk 1 Oppsummering Uke1 Vi har gjennomgått hvorfor vi får flere-kjerne CPUer Tråder er måten som
INF2440 Effektiv parallellprogrammering Uke 2 -, våren2015 - tidtaking Arne Maus PSE, Inst. for informatikk 1 Oppsummering Uke1 Vi har gjennomgått hvorfor vi får flere-kjerne CPUer Tråder er måten som
Pensumoversikt - kodegenerering. Kap. 8 del 1 kodegenerering INF5110 v2006. Hvordan er instruksjonene i en virkelig CPU? Arne Maus, Ifi UiO
 Pensumoversikt - kodegenerering Kap. 8 del 1 kodegenerering INF5110 v2006 Arne Maus, Ifi UiO 8.1 Bruk av mellomkode 8.2 Basale teknikker for kodegenerering 8.3 Kode for referanser til datastrukturer (ikke
Pensumoversikt - kodegenerering Kap. 8 del 1 kodegenerering INF5110 v2006 Arne Maus, Ifi UiO 8.1 Bruk av mellomkode 8.2 Basale teknikker for kodegenerering 8.3 Kode for referanser til datastrukturer (ikke
Sortering i Lineær Tid
 Sortering i Lineær Tid Lars Vidar Magnusson 5.2.2014 Kapittel 8 Counting Sort Radix Sort Bucket Sort Sammenligningsbasert Sortering Sorteringsalgoritmene vi har sett på så langt har alle vært sammenligningsbaserte
Sortering i Lineær Tid Lars Vidar Magnusson 5.2.2014 Kapittel 8 Counting Sort Radix Sort Bucket Sort Sammenligningsbasert Sortering Sorteringsalgoritmene vi har sett på så langt har alle vært sammenligningsbaserte
INF2440 Uke 11, v2017 om Goldbachs problem og Oblig 2,3. Arne Maus PSE, Inst. for informatikk
 INF2440 Uke 11, v2017 om Goldbachs problem og Oblig 2,3 Arne Maus PSE, Inst. for informatikk 1 Fra hjemmesida til INF2440: Plan for resten av semesteret: Forelesninger: 29. Mars (i dag), 5.april, 19.april,
INF2440 Uke 11, v2017 om Goldbachs problem og Oblig 2,3 Arne Maus PSE, Inst. for informatikk 1 Fra hjemmesida til INF2440: Plan for resten av semesteret: Forelesninger: 29. Mars (i dag), 5.april, 19.april,
2 Om statiske variable/konstanter og statiske metoder.
 Litt om datastrukturer i Java Av Stein Gjessing, Institutt for informatikk, Universitetet i Oslo 1 Innledning Dette notatet beskriver noe av det som foregår i primærlageret når et Javaprogram utføres.
Litt om datastrukturer i Java Av Stein Gjessing, Institutt for informatikk, Universitetet i Oslo 1 Innledning Dette notatet beskriver noe av det som foregår i primærlageret når et Javaprogram utføres.
Innhold. 2 Kompilatorer. 3 Datamaskiner og tallsystemer. 4 Oppsummering. 1 Skjerm (monitor) 2 Hovedkort (motherboard) 3 Prosessor (CPU)
 2 Hovedkort (motherboard) 3 Prosessor (CPU)") 2 Innhold 1 Datamaskiner Prosessoren Primærminnet (RAM) Sekundærminne, cache og lagerhierarki Datamaskiner Matlab Parallell Jørn Amundsen Institutt for Datateknikk og Informasjonsvitenskap 2010-08-31 2
2 Innhold 1 Datamaskiner Prosessoren Primærminnet (RAM) Sekundærminne, cache og lagerhierarki Datamaskiner Matlab Parallell Jørn Amundsen Institutt for Datateknikk og Informasjonsvitenskap 2010-08-31 2
INF2440 Uke 5, våren2017. Arne Maus PSE, Inst. for informatikk
 INF2440 Uke 5, våren2017 Arne Maus PSE, Inst. for informatikk 1 Hva så vi på i Uke4 1. Kommentarer til svar på ukeoppgaven om matrisemultiplikasjon 1. Hvorfor disse gode resultatene (speedup > 40) 2. Hvordan
INF2440 Uke 5, våren2017 Arne Maus PSE, Inst. for informatikk 1 Hva så vi på i Uke4 1. Kommentarer til svar på ukeoppgaven om matrisemultiplikasjon 1. Hvorfor disse gode resultatene (speedup > 40) 2. Hvordan
INF2440 Uke 5, våren2016. Arne Maus PSE, Inst. for informatikk
 INF2440 Uke 5, våren2016 Arne Maus PSE, Inst. for informatikk 1 Hva så vi på i Uke4 1. Kommentarer til svar på ukeoppgaven om matrisemultiplikasjon 1. Hvorfor disse gode resultatene (speedup > 40) 2. Hvordan
INF2440 Uke 5, våren2016 Arne Maus PSE, Inst. for informatikk 1 Hva så vi på i Uke4 1. Kommentarer til svar på ukeoppgaven om matrisemultiplikasjon 1. Hvorfor disse gode resultatene (speedup > 40) 2. Hvordan
INF2440 Uke 9, v2014 : Arne Maus OMS, Inst. for informatikk
 INF2440 Uke 9, v2014 : Arne Maus OMS, Inst. for informatikk 1 Hva har vi sett på i uke 8: 1. En effektiv Threadpool? Executors.newFixedThreadPool 2. Mer om effektivitet og JIT-kompilering! 3. Om et problem
INF2440 Uke 9, v2014 : Arne Maus OMS, Inst. for informatikk 1 Hva har vi sett på i uke 8: 1. En effektiv Threadpool? Executors.newFixedThreadPool 2. Mer om effektivitet og JIT-kompilering! 3. Om et problem
P1 P2 P3 P1 P2 P3 P1 P2. OS gjør Contex Switch fra P1 til P2
 i, intensive i og Når OS switcher fra prosess P1 til prosess P2 utføres en såkalt Contex (kontekst svitsj). 10 30 50 70 P1 P2 P3 P1 P2 P3 P1 P2 OS gjør Contex fra P1 til P2 tid/ms bruk Figure: Prosessene
i, intensive i og Når OS switcher fra prosess P1 til prosess P2 utføres en såkalt Contex (kontekst svitsj). 10 30 50 70 P1 P2 P3 P1 P2 P3 P1 P2 OS gjør Contex fra P1 til P2 tid/ms bruk Figure: Prosessene
Fra Python til Java, del 2
 Fra Python til Java, del 2 Hvordan kjøre Java? På Ifis maskiner På egen maskin Et eksempel Array-er For-setninger Lesing og skriving Metoder Biblioteket Hva trenger vi egentlig? Å kjøre Java For å kunne
Fra Python til Java, del 2 Hvordan kjøre Java? På Ifis maskiner På egen maskin Et eksempel Array-er For-setninger Lesing og skriving Metoder Biblioteket Hva trenger vi egentlig? Å kjøre Java For å kunne
UNIVERSITETET I OSLO
 UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i INF1010 Objektorientert programmering Dato: 9. juni 2016 Tid for eksamen: 09.00 15.00 (6 timer) Oppgavesettet er på 7 sider. Vedlegg:
UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i INF1010 Objektorientert programmering Dato: 9. juni 2016 Tid for eksamen: 09.00 15.00 (6 timer) Oppgavesettet er på 7 sider. Vedlegg:
INF2220: Time 12 - Sortering
 INF0: Time 1 - Sortering Mathias Lohne mathialo Noen algoritmer Vi skal nå se på noen konkrete sorteringsalgoritmer. Gjennomgående i alle eksempler vil vi sortere tall etter tallverdi, men som diskutert
INF0: Time 1 - Sortering Mathias Lohne mathialo Noen algoritmer Vi skal nå se på noen konkrete sorteringsalgoritmer. Gjennomgående i alle eksempler vil vi sortere tall etter tallverdi, men som diskutert
INF2440 Uke 15, v2014 oppsummering. Arne Maus OMS, Inst. for informatikk
 INF2440 Uke 15, v2014 oppsummering Arne Maus OMS, Inst. for informatikk 1 Hva så vi på i Uke14 I) Sjekke Goldbachs hypotese for n > 4*10 18. Jeg skisserte en meget dårlig (ineffektiv) algoritme for dere.
INF2440 Uke 15, v2014 oppsummering Arne Maus OMS, Inst. for informatikk 1 Hva så vi på i Uke14 I) Sjekke Goldbachs hypotese for n > 4*10 18. Jeg skisserte en meget dårlig (ineffektiv) algoritme for dere.
INF 1000 høsten 2011 Uke september
 INF 1000 høsten 2011 Uke 2 30. september Grunnkurs i Objektorientert Programmering Institutt for Informatikk Universitetet i Oslo Siri Moe Jensen og Arne Maus 1 INF1000 undervisningen Forelesningene: Første
INF 1000 høsten 2011 Uke 2 30. september Grunnkurs i Objektorientert Programmering Institutt for Informatikk Universitetet i Oslo Siri Moe Jensen og Arne Maus 1 INF1000 undervisningen Forelesningene: Første
INF2440 Uke 10, v2015 : Arne Maus PSE, Inst. for informatikk
 INF2440 Uke 10, v2015 : Arne Maus PSE, Inst. for informatikk 1 Hva så vi på i uke 9 Et sitat om tidsforbruk ved faktorisering Om en feil i Java 7 ved tidtaking Hvordan parallellisere rekursive algoritmer
INF2440 Uke 10, v2015 : Arne Maus PSE, Inst. for informatikk 1 Hva så vi på i uke 9 Et sitat om tidsforbruk ved faktorisering Om en feil i Java 7 ved tidtaking Hvordan parallellisere rekursive algoritmer
INF1000 undervisningen INF 1000 høsten 2011 Uke september
 INF1000 undervisningen INF 1000 høsten 2011 Uke 2 30. september Grunnkurs i Objektorientert Programmering Institutt for Informatikk Universitetet i Oslo Siri Moe Jensen og Arne Maus Forelesningene: Første
INF1000 undervisningen INF 1000 høsten 2011 Uke 2 30. september Grunnkurs i Objektorientert Programmering Institutt for Informatikk Universitetet i Oslo Siri Moe Jensen og Arne Maus Forelesningene: Første
4/5 store parallelle maskiner /4 felles hukommelse in 147, våren 1999 parallelle datamaskiner 1. når tema pensum.
 Parallellitet når tema pensum 27/4 felles hukommelse 9.2 9.3 4/5 store parallelle maskiner 9.4 9.6 in 147, våren 1999 parallelle datamaskiner 1 Tema for denne forelesningen: kraftigere enn én prosessor
Parallellitet når tema pensum 27/4 felles hukommelse 9.2 9.3 4/5 store parallelle maskiner 9.4 9.6 in 147, våren 1999 parallelle datamaskiner 1 Tema for denne forelesningen: kraftigere enn én prosessor
Python: Rekursjon (og programmering av algoritmer) Python-bok: Kapittel 12 + teoribok om Algoritmer
 Python-bok: Kapittel 12 + teoribok om Algoritmer") Python: Rekursjon (og programmering av algoritmer) Python-bok: Kapittel 12 + teoribok om Algoritmer TDT4110 IT Grunnkurs Professor Guttorm Sindre Læringsmål og pensum Mål Forstå, og kunne bruke, algoritmer
Python: Rekursjon (og programmering av algoritmer) Python-bok: Kapittel 12 + teoribok om Algoritmer TDT4110 IT Grunnkurs Professor Guttorm Sindre Læringsmål og pensum Mål Forstå, og kunne bruke, algoritmer
Innhold. Introduksjon til parallelle datamaskiner. Ulike typer parallelle arkitekturer. Prinsipper for synkronisering av felles hukommelse
 Innhold Introduksjon til parallelle datamaskiner. Ulike typer parallelle arkitekturer Prinsipper for synkronisering av felles hukommelse Multiprosessorer koblet sammen av én buss 02.05 2001 Parallelle
Innhold Introduksjon til parallelle datamaskiner. Ulike typer parallelle arkitekturer Prinsipper for synkronisering av felles hukommelse Multiprosessorer koblet sammen av én buss 02.05 2001 Parallelle
La oss begynne med en repetisjon av hva som skjer når du kjører Javaprogrammet
 K A P I T T E L 18 Tråder N år et program kjøres, utføres programsetningene i en bestemt rekkefølge. En tråd er det samme som denne programflyten, og i dette kapitlet skal vi se på hvordan vi starter og
K A P I T T E L 18 Tråder N år et program kjøres, utføres programsetningene i en bestemt rekkefølge. En tråd er det samme som denne programflyten, og i dette kapitlet skal vi se på hvordan vi starter og
Singletasking OS. Device minne Skjerm minne. Brukerprogram. Brukerdata/heap. Stack. Basis for flerprosess-systemer.
 -OS i i L1 og L2 og og Basis for flerprosess-systemer. Adresser.. 2 1 0 OS Device minne Skjerm minne Brukerprogram Brukerdata/heap Stack Stack: brukes bl. a. til å lagre adressen som skal returneres til
-OS i i L1 og L2 og og Basis for flerprosess-systemer. Adresser.. 2 1 0 OS Device minne Skjerm minne Brukerprogram Brukerdata/heap Stack Stack: brukes bl. a. til å lagre adressen som skal returneres til
INF1010, 22. mai Prøveeksamen (Eksamen 12. juni 2012) Stein Gjessing Inst. for Informatikk Universitetet i Oslo
 Stein Gjessing Inst. for Informatikk Universitetet i Oslo") INF, 22. mai 23 Prøveeksamen 23 (Eksamen 2. juni 22) Stein Gjessing Inst. for Informatikk Universitetet i Oslo Oppgave a Tegn klassehierarkiet for de 9 produkttypene som er beskrevet over. Inkluder også
INF, 22. mai 23 Prøveeksamen 23 (Eksamen 2. juni 22) Stein Gjessing Inst. for Informatikk Universitetet i Oslo Oppgave a Tegn klassehierarkiet for de 9 produkttypene som er beskrevet over. Inkluder også
Array&ArrayList Lagring Liste Klasseparametre Arrayliste Testing Lenkelister
 Dagens tema Lister og generiske klasser, del I Array-er og ArrayList (Big Java 6.1 & 6.8) Ulike lagringsformer (Collection) i Java (Big Java 15.1) Klasser med typeparametre («generiske klasser») (Big Java
Dagens tema Lister og generiske klasser, del I Array-er og ArrayList (Big Java 6.1 & 6.8) Ulike lagringsformer (Collection) i Java (Big Java 15.1) Klasser med typeparametre («generiske klasser») (Big Java
INF1010 Tråder J. Marit Nybakken Motivasjon. Å lage en tråd
 J INF1010 Tråder J Marit Nybakken marnybak@ifi.uio.no Motivasjon Til nå har vi kun skrevet programmer der programmet bare var på ett sted i koden til enhver tid (bortsett fra når vi har drevet med GUI,
J INF1010 Tråder J Marit Nybakken marnybak@ifi.uio.no Motivasjon Til nå har vi kun skrevet programmer der programmet bare var på ett sted i koden til enhver tid (bortsett fra når vi har drevet med GUI,
UNIVERSITETET I OSLO
 Eksamen i UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamensdag: 14. desember 2015 Tid for eksamen: 14.30 18.30 Oppgavesettet er på 6 sider. Vedlegg: Tillatte hjelpemidler: INF2220
Eksamen i UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamensdag: 14. desember 2015 Tid for eksamen: 14.30 18.30 Oppgavesettet er på 6 sider. Vedlegg: Tillatte hjelpemidler: INF2220
Kap. 8 del 1 kodegenerering INF5110 Vår2007
 Kap. 8 del 1 kodegenerering INF5110 Vår2007 Stein Krogdahl, Ifi UiO Forelesninger framover: Tirsdag 8. mai: Vanlig forelesning Torsdag 10. mai: Ikke forelesning Tirsdag 15. mai: Vanlig forelesning (siste?)
Kap. 8 del 1 kodegenerering INF5110 Vår2007 Stein Krogdahl, Ifi UiO Forelesninger framover: Tirsdag 8. mai: Vanlig forelesning Torsdag 10. mai: Ikke forelesning Tirsdag 15. mai: Vanlig forelesning (siste?)
EKSAMEN. Dato: 28. mai 2018 Eksamenstid: 09:00 13:00
 EKSAMEN Emnekode: ITF20006 Emne: Algoritmer og datastrukturer Dato: 28. mai 2018 Eksamenstid: 09:00 13:00 Hjelpemidler: Alle trykte og skrevne Faglærer: Jan Høiberg Om eksamensoppgavene: Oppgavesettet
EKSAMEN Emnekode: ITF20006 Emne: Algoritmer og datastrukturer Dato: 28. mai 2018 Eksamenstid: 09:00 13:00 Hjelpemidler: Alle trykte og skrevne Faglærer: Jan Høiberg Om eksamensoppgavene: Oppgavesettet
INF1010 notat: Binærsøking og quicksort
 INF1010 notat: Binærsøking og quicksort Ragnhild Kobro Runde Februar 2004 I dette notatet skal vi ta for oss ytterligere to eksempler der rekursjon har en naturlig anvendelse, nemlig binærsøking og quicksort.
INF1010 notat: Binærsøking og quicksort Ragnhild Kobro Runde Februar 2004 I dette notatet skal vi ta for oss ytterligere to eksempler der rekursjon har en naturlig anvendelse, nemlig binærsøking og quicksort.
INF2440 Uke 8, v2017. Arne Maus PSE, Inst. for informatikk
 INF2440 Uke 8, v2017 Arne Maus PSE, Inst. for informatikk 1 Hva har vi sett på i uke 7: 1. Svar på et oblig2-spørsmål 2. Hvilken orden O() har Eratosthenes Sil? 3. Hvordan parallellisere Oblig2 - alternativer
INF2440 Uke 8, v2017 Arne Maus PSE, Inst. for informatikk 1 Hva har vi sett på i uke 7: 1. Svar på et oblig2-spørsmål 2. Hvilken orden O() har Eratosthenes Sil? 3. Hvordan parallellisere Oblig2 - alternativer
Algoritmer - definisjon
 Algoritmeanalyse Algoritmer - definisjon En algoritme* er en beskrivelse av hvordan man løser et veldefinert problem med en presist formulert sekvens av et endelig antall enkle, utvetydige og tidsbegrensede
Algoritmeanalyse Algoritmer - definisjon En algoritme* er en beskrivelse av hvordan man løser et veldefinert problem med en presist formulert sekvens av et endelig antall enkle, utvetydige og tidsbegrensede
UNIVERSITETET I OSLO
 UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i: INF1010 Objektorientert programmering Dato: 9. juni 2016 Tid for eksamen: 09.00 15.00 (6 timer) Oppgavesettet er på 7 sider.
UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i: INF1010 Objektorientert programmering Dato: 9. juni 2016 Tid for eksamen: 09.00 15.00 (6 timer) Oppgavesettet er på 7 sider.
1,r H øgs kolen i Østfol d
 1,r H øgs kolen i Østfol d EKSAMEN Emnekode: ITF22506 Emne: Operativsystemer Dato: 2. juni 2010 Eksamenstid: kl. 9.00 til kl. 13.00 Hjelpemidler: Faglærer: 1. Læreboken "A Practical Guide to Red Hat Linux"
1,r H øgs kolen i Østfol d EKSAMEN Emnekode: ITF22506 Emne: Operativsystemer Dato: 2. juni 2010 Eksamenstid: kl. 9.00 til kl. 13.00 Hjelpemidler: Faglærer: 1. Læreboken "A Practical Guide to Red Hat Linux"
IN1010. Fra Python til Java. En introduksjon til programmeringsspråkenes verden Dag Langmyhr
 IN1010 Fra Python til Java En introduksjon til programmeringsspråkenes verden dag@ifi.uio.no Oversikt Introduksjon Python Java Noe er likt Noe bare ser anderledes ut Noe er helt forskjellig Et par eksempler
IN1010 Fra Python til Java En introduksjon til programmeringsspråkenes verden dag@ifi.uio.no Oversikt Introduksjon Python Java Noe er likt Noe bare ser anderledes ut Noe er helt forskjellig Et par eksempler
UNIVERSITETET I OSLO
 UNIVERSITETET I OSLO BOKMÅL Det matematisk-naturvitenskapelige fakultet Eksamen i : Eksamensdag : Torsdag 2. desember 2004 Tid for eksamen : 09.00 12.00 Oppgavesettet er på : Vedlegg : Tillatte hjelpemidler
UNIVERSITETET I OSLO BOKMÅL Det matematisk-naturvitenskapelige fakultet Eksamen i : Eksamensdag : Torsdag 2. desember 2004 Tid for eksamen : 09.00 12.00 Oppgavesettet er på : Vedlegg : Tillatte hjelpemidler
Fra Python til Java. En introduksjon til programmeringsspråkenes verden. Dag Langmyhr
 Fra Python til Java En introduksjon til programmeringsspråkenes verden dag@ifi.uio.no Oversikt Introduksjon Python Java Noe er likt Noe bare ser anderledes ut Noe er helt forskjellig Et eksempel Klasser
Fra Python til Java En introduksjon til programmeringsspråkenes verden dag@ifi.uio.no Oversikt Introduksjon Python Java Noe er likt Noe bare ser anderledes ut Noe er helt forskjellig Et eksempel Klasser
UNIVERSITETET I OSLO
 UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i: INF 2220 Algoritmer og datastrukturer Eksamensdag: 8. desember 2016 Tid for eksamen: 09:00 13:00 (4 timer) Oppgavesettet er på:
UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i: INF 2220 Algoritmer og datastrukturer Eksamensdag: 8. desember 2016 Tid for eksamen: 09:00 13:00 (4 timer) Oppgavesettet er på:
Array&ArrayList Lagring Liste Klasseparametre Arrayliste Testing Lenkelister Videre
 Dagens tema Lister og generiske klasser, del I Array-er og ArrayList (Big Java 6.1 & 6.8) Ulike lagringsformer (Collection) i Java (Big Java 15.1) Klasser med typeparametre («generiske klasser») (Big Java
Dagens tema Lister og generiske klasser, del I Array-er og ArrayList (Big Java 6.1 & 6.8) Ulike lagringsformer (Collection) i Java (Big Java 15.1) Klasser med typeparametre («generiske klasser») (Big Java
OPPGAVE 1 OBLIGATORISKE OPPGAVER (OBLIG 1) (1) Uten å selv implementere og kjøre koden under, hva skriver koden ut til konsollen?
 (1) Uten å selv implementere og kjøre koden under, hva skriver koden ut til konsollen?") OPPGAVESETT 4 PROSEDYRER Oppgavesett 4 i Programmering: prosedyrer. I dette oppgavesettet blir du introdusert til programmering av prosedyrer i Java. Prosedyrer er også kjent som funksjoner eller subrutiner.
OPPGAVESETT 4 PROSEDYRER Oppgavesett 4 i Programmering: prosedyrer. I dette oppgavesettet blir du introdusert til programmering av prosedyrer i Java. Prosedyrer er også kjent som funksjoner eller subrutiner.