Inferens i fordelinger
|
|
|
- Kristina Bakken
- 6 år siden
- Visninger:
Transkript
1 Inferens i fordelinger Modifiserer antagelsen om at standardavviket i populasjonen σ er kjent Mer kompleks systematisk del ( her forventningen i populasjonen). Skal se på en situasjon der populasjonsfordelingen kan beskrives med to fordelinger. Derfor både: ett utvalg og to utvalg
2 Inferens om forventningsverdien til populasjonen Fortsatt primært interessert i forventningen μ, men populasjonsfordelingen beskrives nå med to ukjente parametre μ og σ. Fortsatt enkelt tilfeldig utvalg, ETU, SRS, av størrelse n. Estimerer μ med x og det teoretiske standardavviket σ med det empiriske standardavviket s x = (X i X) 2 /(n 1)
3 Antar her i tillegg at populasjonsfordelingen er N(μ,σ). Standardavviket til gjennomsnittet i utvalget, σ x = σ/ n,estimeres med med s x / n. Denne estimatoren kalles kalles standardfeilen til gjennomsnittet og betegnes med SE x. Mer generelt: Når standardavviket til en observator estimeres fra data, kalles estimatet standardfeilen til observatoren. Standardfeilen til gjennomsnittet av observasjonene i utvalget er altså s x / n.
4 Når σ kjent er det standardiserte gjennomsnittet Z= x μ σ/ n standard normalfordelt, dvs. N(0,1) Når σ er ukjent, må en i stedet bruke s x / n for å standardisere. Da er fordelingen til den standardiserte variabelen ikke lenger normal vil fordelingen til den standardiserte variabelen avhenge av antallet observasjoner i utvalget, altså en fordeling for hver n.
5 t-fordeling: Anta at observasjonene X 1, X n er et enkelt tilfeldig utvalg fra en populasjon der populasjonsfordelingen er N(μ, σ). t-observatoren for ett utvalg t= x μ s/ n er t-fordelt med n-1 frihetsgrader.
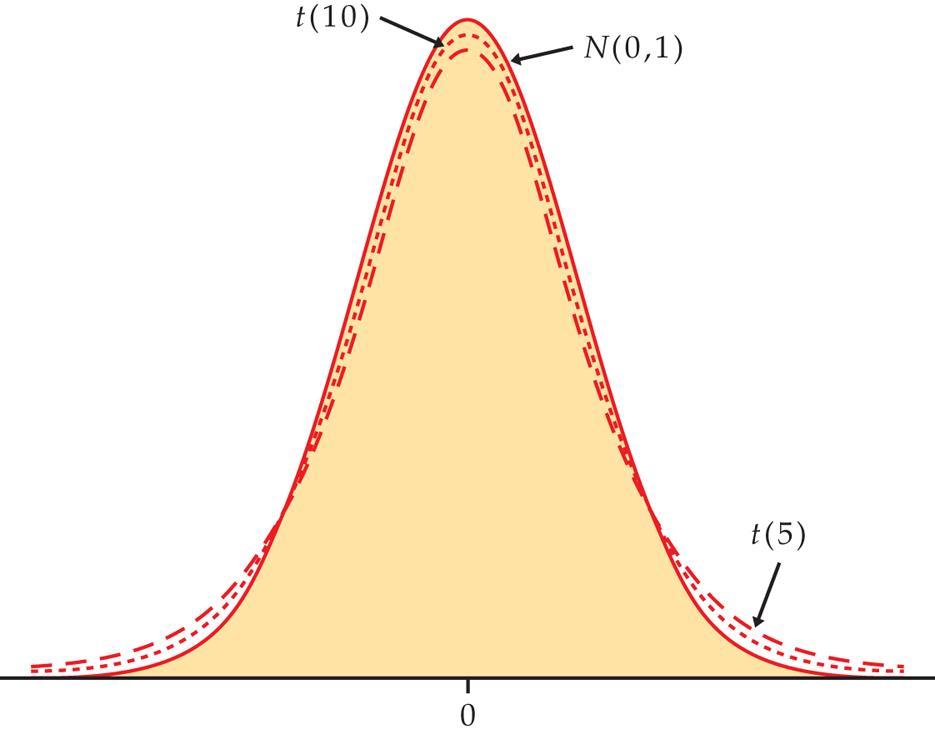
6 Legg merke til følgende: En fordeling for hver utvalgsstørrelse n. Det kommer av at (X i X ) 2 /(n-1) = [ (X 1 X ) 2 + +(X n X ) 2 ]/(n-1) har en fordeling som avhenger av n. n-1 frihetsgrader: En restriksjon siden (X i X) =0 Betegner t-fordelingen med k frihetsgrader med t(k). t-fordeling symmetrisk og har en klokkeformet tethetskurve. Den har tyngre haler enn N(0,1) p.g.a. usikkerheten knyttet til estimatoren s x for σ.
7 Definerer t* analogt med z*: t* er den verdien som gjør at tetthetskurven til t(k) har areal C mellom -t* og t* Tabell D angir kritiske verdier, p=p(t>t*)= (1-C)/2 siden 2p+C=1. t* tabullert både som funksjon av p og C. Ser at når utvalgsstørrelsen øker nærmer de kritiske verdiene seg de tilsvarende fra N(0,1).
8 Fra tabell D bak i læreboka: For p=0.025, C=0.95: frihetsgrader kritisk verdi
9
10 Husk at vi antar at populasjonsfordelingen er N(μ,σ), der både μ og σ er ukjente. Siden σ ikke lenger er kjent, kan den ikke brukes til å standardisere. I stedet estimeres σ med s x. Observatoren blir i dette tilfelle t = x μ s/ n som vi har sett er t-fordelt med n-1 frihetsgrader. Siden dette er en fordeling som er tabulert på ``samme måte'' som normalfordelingen, kan vi bruke t-observatoren til å konstruere konfidensintervall og hypotesetester som tidligere for z- observatoren. Den eneste forskjellen er at P-verdier og kritiske verdier baseres på t-fordelingen
11 Her er detaljene for konfidensintervall: Anta observasjonene er et enkelt tilfeldig utvalg av størrelse n fra en populasjon med ukjent forventning μ. Et konfidensintervall med konfidenskoeffesient C har grenser x ± t* s/ n der t* er verdien som gjør at tetthetskurven til t(n-1)-fordelingen har areal C mellom -t* og t*. Intervallet er eksakt når populasjonsfordelingen er normal og tilnærmet eksakt for store verdier av n. Tolkningen er den samme som for konfidensintervallene vi har sett tidligere.
12 Eksempel: Videoer på mobil Et enkelt tilfeldig utvalg, SRS, amerikanske studenter gir følgende n=8 verdier for bruk av mobiltelefoner til å se på videoer (timer per måned) Gjennomsnitt x =( )/8= 6.75 Empirisk standardavvik s= (7 6.75)2 + (5 6.75) = 3.88 Standardfeilen er SE x = s x / n = 3.88/ 8 = Med C= 0.95 er t*=2.365, ( 7 frihetsgrader) og konfidensintervallet x ± t* s/ n= 6.75± / 8 = 6.75 ± 3.25
13 Konfidensintervallet blir (4.2, 10.1). Men det er viktig å sjekke forutsetningene. Enkelt tilfeldig utvalg av amerikanske studenter. Populasjonsfordelingen normal. Her er normalfordelingsplott nyttige Også for testing er resultatene en direkte modifikasjon av det vi kjenner fra tilfellet med kjent standardavvik σ.
14 Et utvalgs t-test Data består av et enkelt tilfeldig utvalg (ETU, SRS) der fordelingen i populasjonen har forventning μ og standardavvik σ. Nullhypotsen er H 0 : μ=μ 0 Testen baseres t-observatoren for et utvalg t= x μ 0 s/ n Under nullhypotesen er den tilsvarende tilfeldige variabelen,, t-fordelt med n-1 frhetsgrader, dvs. t(n-1) fordelt.
15 Derfor er P-verdiene: Hvis alternativet er ensidig, H a : μ > μ 0, P(T t). Hvis alternativet er ensidig, H a : μ < μ 0, P(T t). Hvis alternativet er tosidig, H a : μ μ 0, 2P(T t ). Disse verdiene gjelder eksakt hvis populasjonsfordelingen er normal, og gjelder ellers som en tilnærmelse når n er stor.
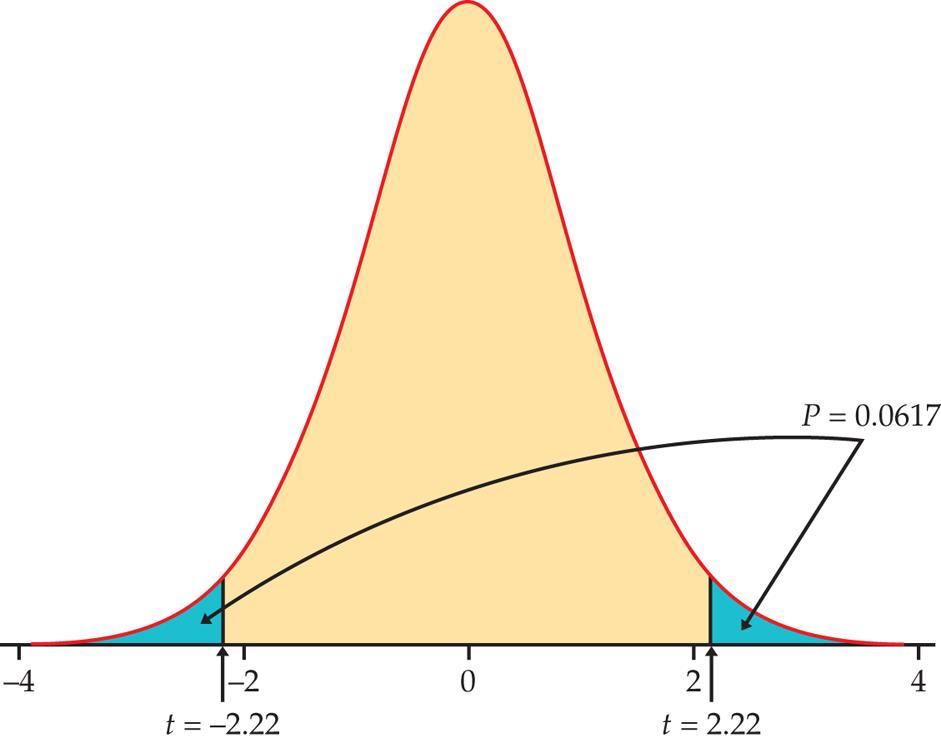
16 Eksempel: Videoer på mobil Gjennomsnittet i USA er 3.7 timer per måned. Hvoran er forventningen blant amerikanske studenter i forhold til det? H 0 : μ = 3.7 H a : μ 3.7 Her er n=8, x =6.75, s= Det gir testobservatoren t= x μ = s/ n 3.88/ = Antallet frihetsgrader er n-1=7. Fra tabell D er P(T 1.895)= 0.05 og P(T 2.365)= 0.025, slik at P-verdien 2 P(T 2.22) ligger mellom 2x0.05=0.1 og 2x0.025=0.05. Fra en statistikkpakke får man 2 P(T 1.40) = Derfor: Ingen forkastning med nivå 0.05.
17
18 Men det kan også forsvares med en ensidig test i dette tilfellet, altså H 0 : μ = 3.7 H a : μ > 3.7 Verdien på testobservatoren er den samme t=2.22. P-verdien er 0.025<P(T 2.22)= < Så i dette tilfellet vil vi forkaste nullhypotesen med nivå 0.05.
19
20 Eksempel: Aksjer, månedlig avkastning n= 39, x = H 0 : μ = 0.95 H a : μ ± 0.95 (S&P gjennomsnitt)
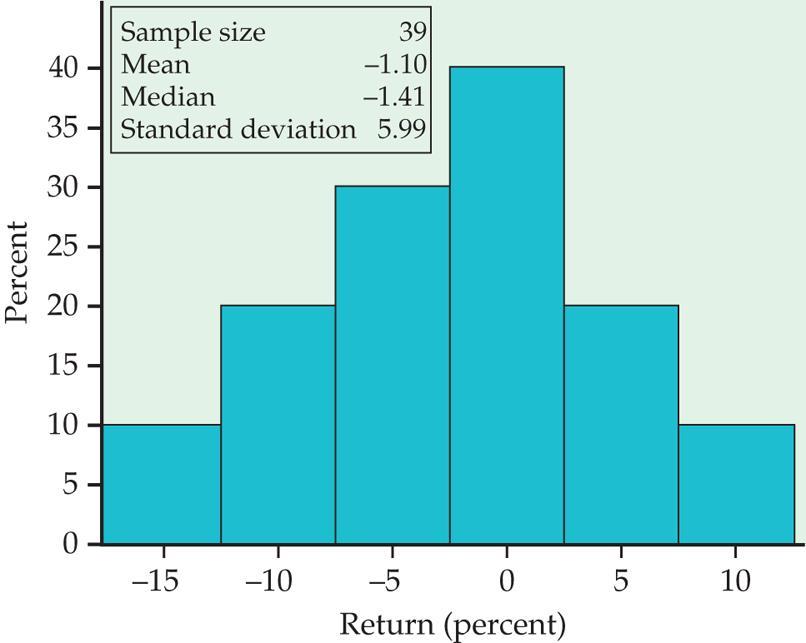
21 Først sjekkes normalitetsforutsetningen

22 Her er x = -1.1, t=-2.14, df (f.gr.) =38, P=0.039, så med nivå 0.05 ser det ut for at avkastningen er dårligere enn S&P indeks.


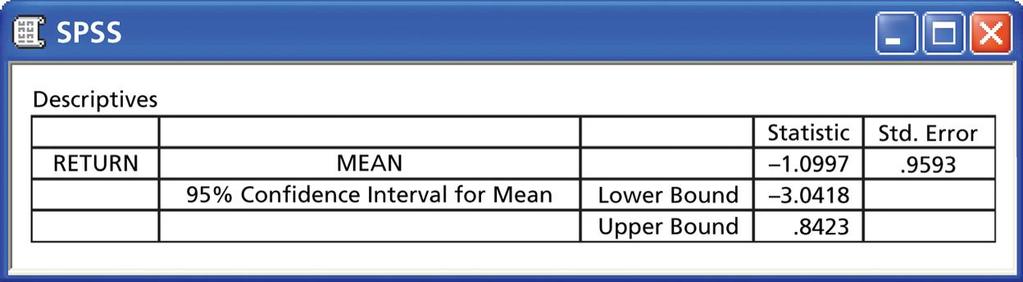
23 Utskrifter fra Minitab og SPSS.
24 Her er beregningene for et konfidensintervall fra Minitab, SPSS og Excel.

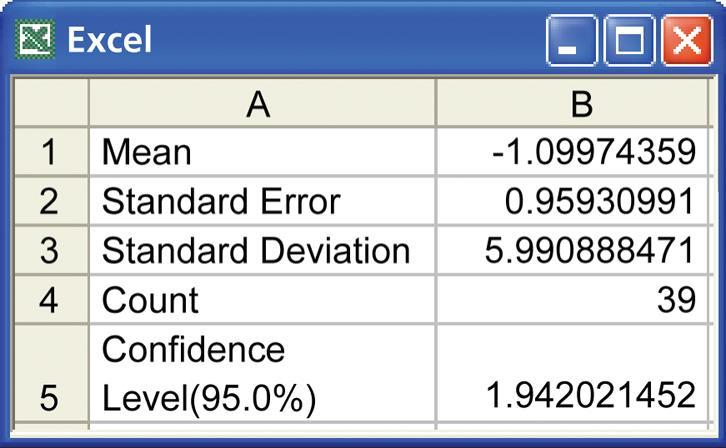
25
26 Fra diskusjonen om forsøksplanlegging var en av hovedkonklusjonene at bruk av kontrollgrupper var viktig. Vi skal nå se at en-utvalgstesten vi har sett på, også kan anvendes i denne sammenhengen. I parplanen ble enhetene delt inn i par som er så like som mulig etter kriterier man kan kontrollere. Deretter sammenlignes en behandling innen parene. Spesielt kan parene være målinger fra samme enhet på to ulike tidspunkt før og etter en intervensjon.
27 Eksempel: Demens og voldelig adferd For n=15 demenspasienter ble antall voldsepisoder klassifisert etter månefasen, nær fullmåne eller ikke, de forekom i. Deretter ble de 15 differansene analysert.

28 Stilk-blad plottet for differansene ser slik ut. Som man ser kan antagelsen om normalfordelte observasjoner diskuteres.
29 Vi bruker enutvalgsmetodene på differansene.månefase ikke månefase. Da svarer «ingen effekt» til H 0 : μ=0 H a : μ 0 Basert på differansene er x = og s=1.460 slik at t= x 0 s/ = n 1.460/ = Fordelingen under H 0 er t(14). Med en tosidig test blir P-verdien derfor mindre enn =0.0010, der er minste kritiske verdi fra tabell D i læreboka. Eksakt verdi er 5.5E-5.
30 P(T 2.145)= hvis T er t(14) fordelt. Et 95% Konfidensintervall har derfor grenser x ± t* s/ n = 2.43± s 1.460/ 15 = 2.43 ± Intervallet inneholder ikke null, så det er en annen måte at verifisere at hypotesen forkastes med nivå Merk: Ikke randomisering i denne studien Bare pasienter med voldelig adferd Data tyder ikke på normalfordeling, jfr. stilk-blad plottet.
31 Metodene bygger på forutsetning om at populasjonsfordelingen N(μ,σ). Hvor store avvik kan tolereres? Metoder for statistisk inferens (slutninger) kalles robuste hvis sannsynlighetsberegningene som trengs i liten grad påvirkes av brudd på de forutsetningene de er utledet under. t-tester og konfidensintervall er ganske robuste mot avvik fra normalitet, bortsettfra ``outliere'' og sterk skjevhet. Særlig er ``outliere'' problematisk, siden x og s påvirkes. Det er derfor viktig å undersøke om dette forekommer, spesielt når utvalget er lite. Bruk normalfordelingsplott, histogrammer, stilk og blad plott og boksplott.
32 Tommelfinger regler: n < 15: Bruk t-metoder når data ser normale ut. Pass på hvis klare brudd normalitet eller data inneholder ``outliere''. I så fall, bruk noe annet. n 15: Her kan t-teste/t k.i. brukes bortsett fra der det er tydelig skjevhet eller ``outliere''. n 40 : Da kan selv klare brudd tolereres.
33 Sammenligning av to utvalg Ønsker å sammenligne responsen i to grupper. Hver gruppe er et utvalg fra en populasjon. I utgangspunktet er det altså to populasjoner. Responsene i en av gruppene er uavhengig av responsene i den andre. De to gruppene kan dannes ved et randomisert forsøk eller ved at tilfeldige utvalg trekkes fra hver av populasjonene.
34 Notasjon: Populasjon variabel forventning st. avvik 1 x 1 μ 1 σ 1 2 x 2 μ 2 σ 2 Vi er interessert i å sammenligne forventningen i de to gruppene, dvs μ 1 - μ 2 Det gjør vi ved enten å lage konfidensintervall for μ 1 - μ 2 eller ved å teste H 0 : μ 1 = μ 2.
35 Testen og konfidensintervallet baseres på data fra de to utvalgene Populasjon utvalgsstørrelese gj.snt. utvalg st. avvik utvalg 1 n 1 x 1 s 1 2 n 2 x 2 s 2 Størrelsen μ 1 - μ 2 estimerer man med x1 - x 2. Her er μ x 1 x 2 = μ 1 - μ 2, og σ 2 x 1 x 2 = σ2 1/ n 1 + σ 2 2/ n 2.
36 For den nokså urealistiske situasjonen at σ 1 og σ 2 er kjente ville man basert seg på den standariserte variabelen z= ( x 1 x 2 ) ( μ 1 μ 2 ) σ 2 1/ n 1 + σ 2 2/ n 2. Under forutsetning at x1 er gjennomsnitt i et enkelt tilfeldig utvalg fra en N(μ 1, σ 1 ) populasjon, og at x 2 er gjennomsnitt i et annet uavhengig enkelt tilfeldig utvalg fra en N(μ 2, σ 2 ) populasjon, er z standard N(0,1) fordelt.
37 Eksempel: Figuren nedenfor illustrerer inferens basert på fordelingen for høyde av tiårige jenter og gutter i USA som er tilnærmet N(56.4, 2.7) og N(55.7, 3.8) ( i tommer) fordelt. Antar vi disse standardavvikene kan man beregne sannsynligheten for at forskjellen i to tilfeldige utvalg er større enn null.
38 Det vanlige er altså at standadavvikene må estimeres. Vi bruker samme fremgangsmåte som i ett utvalgssituasjonen. Når standardavviket i de to populasjonene ikke er kjent, estimeres de ved de empiriske standardavvikene i de to to utvalgene. Dette gir t-observatoren for to utvalg t= ( x 1 x 2 ) ( μ 1 μ 2 ) s 2 1/ n 1 + s 2 2/ n 2. N.B. Denne fordelingen avhenger av n 1 og n 2 og σ 1 og σ 2, så fordelingen er ikke t-fordelt. Dette gjelder selv om de to utvalgene er enkle tilfeldige utvalg fra uavhengige N(μ 1, σ 1 ) og N(μ 2, σ 2 ) populasjoner.
39 Selv om t-observatoren for to utvalg, t, ikke er eksakt t-fordelt, kan fordelingen tilnærmes svært godt med en t(k) fordeling, der k kan beregnes. Fra denne tilnærmede fordelingen kan en finne de nødvendige kritiske verdiene og P-verdiene som trengs. Observatoren kan modifiseres slik at den er t-fordelt i spesialtilfellet σ 1 = σ 2.
40 To måter å beregne k på Beregn k fra data. Dette gjøres i de fleste statistikkpakker inkludert MINITAB. La k være den minste verdien av n 1-1 og n 2-1, dvs. k= min (n 1-1,n 2-1).
41 To utvalgs konfidensintervall: Under forutsetning at x1 er gjennomsnitt i et enkelt tilfeldig utvalg fra en N(μ 1, σ 1 ) populasjon, og at x 2 er gjennomsnitt i et annet uavhengig enkelt tilfeldig utvalg fra en N(μ 2, σ 2 ) populasjon vil et konfidensintervall med konfidenskoeffesient minst lik C for μ 1 - μ 2 ha grenser x1 - x 2 ± t* s 1 2 /n 1 + s 2 2 /n 2 Her er t* den verdien som gjør at arealet under tetthetskurven til en t(k) fordeling er C mellom -t* og t*. Antallet frihetsgrader k er enten beregnet i en statistikkpakke eller som k= min (n 1-1,n 2-1).
42 Eksempel: Lesevansker, sammenligning med kontrollgruppe Fra de to gruppene Gruppe n x s Behandling Kontroll

43
44 Et 95% konfidensintervall har grenser x1 - x 2 ± t* s 1 2 /n 1 + s 2 2 /n 2 =( ) ± t* / /23 = 9.96 ± 4.31 t* Fra en statistikkpakke er antallet frihetsgrader k=37.9 og t*= Det gir tilnærmelsen 9.96 ± = 9.96 ± 8.72 Med antallet frihetsgrader lik k = min ( 21-1, 23-1) = 20 blir t*=2.086 fra tabell D, og det tilnærmede k.i. blir 9.96 ± = 9.96 ± 8.99 Den konservative varianten gir det lengste k.i
45 To utvalgs tester: Anta at x1 er gjennomsnitt i et enkelt tilfeldig utvalg fra en N(μ 1, σ 1 ) populasjon, og at x 2 er gjennomsnitt i et annet uavhengig enkelt tilfeldig utvalg fra en N(μ 2, σ 2 ) populasjon. For å tests H 0 : μ 1 = μ 2 beregnes observatoren for to utvalg ( x 1 x 2 ) t=. s 2 1/ n 1 + s 2 2/ n 2 P-verdiene beregnes fra en t(k) fordeling, der antallet frihetsgrader, k, enten er beregnet i en statistikkpakke eller k= min (n 1-1,n 2-1).
46 Eksempel: Lærevansker Tester H 0 : μ 1 = μ 2 mot H a : μ 1 > μ 2 Beregner to utvalgs t observatoren ( x 1 x 2 ) t= = s 2 1/ n 1 + s 2 2/ n / /23 = 2.31 P-verdi: P( T 2.31). Fra statistikkpakke: P-verdi og 37.9 frihetsgrader. Med k= min (n 1-1,n 2-1). = 20 frihetsgrader er P-verdien mellom 0.01 og Konklusjon: Lav P-verdi viser at data lite forenelig med H 0 : μ 1 = μ 2, slik at det ser ut til at er en reel forbedring.
47 Opplegget av undersøkelsen ikke ideel: Umulig med randomisering, slik at effekt av bakenforliggende variable ikke kan utelukkes, for eksempel forskjell mellom klassene og lærerens ferdigheter. Botemiddel: Mye pretesting av klassene før forsøket startet for å avdekke forskjeller. Dessuten samme lærer.
48 Metodene for to utvalg er mer robuste enn metodene i et utvalg. Hvis utvalgene er like store, n 1 = n 2, kan sannsynligheter basert på t-fordelinger være ganske nøyaktige fra n 1 = n 2 =5. Forutsetningen for dette er at de to populasjonsfordelingene har nokså lik form. Tilnærmelsene best for n 1 = n 2, så det er lurt å tilstrebe at de to utvalgene blir like store hvis det er mulig.
49 Reglene fra ett uttvalg gjelder med n=n 1 + n 2 n 1 + n 2 < 15: Bruk t-metoder når data ser normale ut. Pass på hvis klare brudd normalitet eller data inneholder ``outliere''. I så fall, bruk noe annet. n 1 + n 2 15: Her kan t-tester/t-konfidensintervaller brukes bortsett fra der det er tydelig skjevhet eller ``outliere''. n 1 + n 2 40: Da kan selv klare brudd tolereres. Små utvalg krever ekstra oppmerksomhet. Det er lite informasjon i boksplott og normalfordelingsplott i slike tilfeller. Det kan derfor være vanskelig å oppdage outliere. Utvalg av tilnærmet samme størrelse er å foretrekke.
50 I spesialtilfellet der de to normalfordelte populasjonene har samme standardavvik, kan dette utnyttes. Begge variansestimatorene 2 2 s 1 og s 2 er da forventningsrette estimatorer for σ 2, og ved å kombinere dem kan man få en bedre estimator. Denne er s 2 p = (n 2 1 1)s 1 +(n2 1)s 2 2. n 1 + n 2 2 Dette kalles «the pooled etimator» for σ 2, derav fotskrift p. Den kombinerer informasjon fra begge utvalg, og brukes til å standarisere på samme måte som tidligere.
51 Nå er variansen til x1 - x 2 er siden de to utvalgene er uavhengige σ 2 x 1 x 2 = σ2 ( 1 n n 2 ), slik at den tilfeldige variabelen z = (x 1 x 2 ) (μ 1 μ 2 ) σ n1 n2 er standard normalfordelt N(0,1). Ved å erstatte σ med estimatoren s p 2 får man en t-fordelt variabel med n 1 + n 2-2 frihetsgrader. Det gir konfidensintervall og tester av formen.
52 For konfidensintervaller: Anta at x1 er gjennomsnittet av et enkelt tilfeldig utvalg fra en populasjon som er normalfordelt med ukjent forventning μ 1, og at x 2 er gjennomsnittet av et annet uavhengig enkelt tilfeldig utvalg fra en populasjon som er normalfordelt med ukjent forventning μ 2. Anta at standardavviket i de to fordelingene er det samme. Et konfidensintervall med konfidenskoeffesient lik C for μ 1 μ 2 har grenser (x1 - x 2) ± t* s p 1 n n 2. Her er t* den verdien som gjør at arealet under tetthetskurven til en t(n 1 + n 2-2) fordeling mellom -t* og t* er C.
53 For tester: Anta at x1 er gjennomsnittet av et enkelt tilfeldig utvalg fra en populasjon som er normalfordelt med ukjent forventning μ 1, og at x 2 er gjennomsnittet av et annet uavhengig enkelt tilfeldig utvalg fra en populasjon som er normalfordelt med ukjent forventning μ 2. Anta at standardavviket i de to fordelingene er det samme. For å teste nullhypotesen H 0 :μ 1 =μ 2 beregn ``the pooled'' t-observator t = x 1 x 2 s p 1 n1 + 1 n2
54 Under nullhypotesen er den tilsvarende tilfeldige variabelen, T, t(n 1 + n 2-2) fordelt. Derfor er P-verdiene Hvis alternativet er ensidig H a :μ 1 > μ 2, P(T t). Hvis alternativet er ensidig H a :μ 1 < μ 2, P(T t). Hvis alternativet er tosidig H a :μ 1 μ 2, 2 P(T t ).
55 Eksempel: Kalsium supplement og blodtrykk (i mm kvikksølv) To grupper svarte menn målt på to tidspunkter. Placebo og behandlingsgruppe, dobbelt blindt
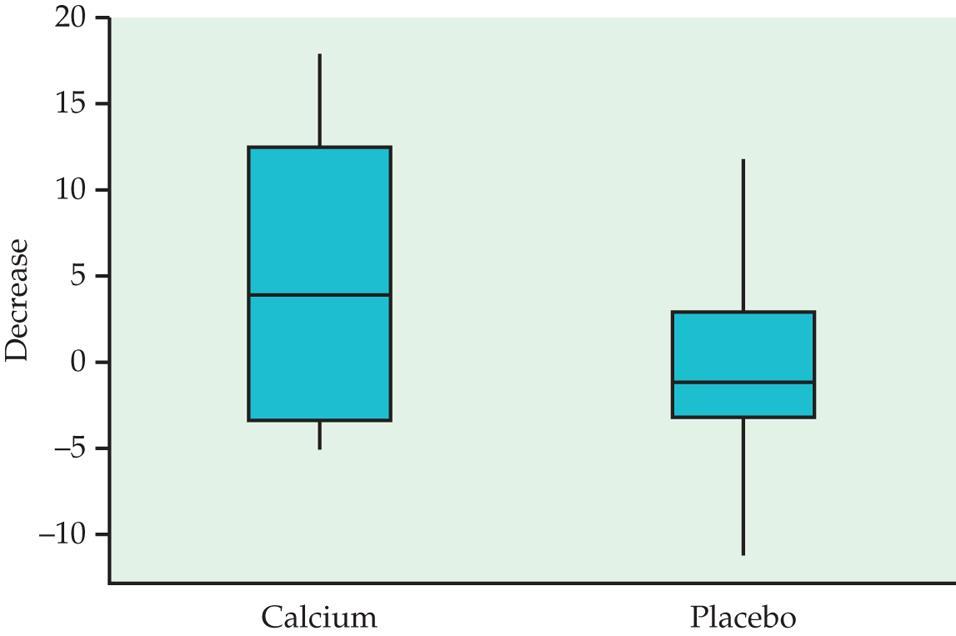
56
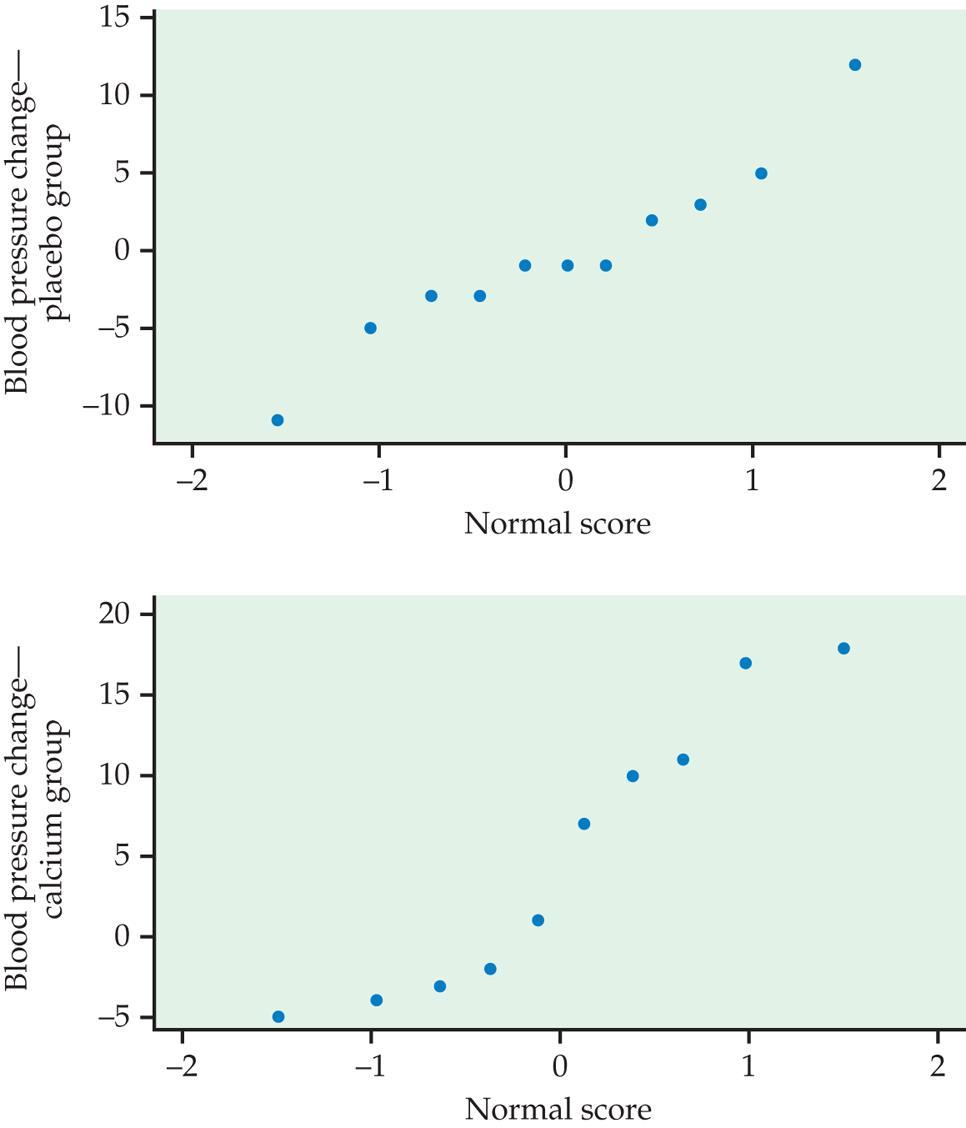
57
58 Data for nedgang: Behandling n x s Kalsium Placebo Vi tester H 0 :μ 1 = μ 2 mot H a :μ 1 > μ 2 Beregner først «pooled variance» s p 2 = (n 1 1)s 1 2 +(n2 1)s 2 2 n 1 + n 2 2 = (11 1) =
59 Da er s p = = kombinerte t-observatoren og den t = x 1 x 2 s p 1 n1 + 1 n2 = ( 0.273) = =1.634 P-verdien er P(T 1.634) = beregnet fra en t(19)-fordeling, slik at dataene tyder på en viss reduksjon av blodtrykket, men ikke nok til forkastning på nivå 1% eller 5%.
60 Et 90% konfidens intervall har grenser ( x1 - x 2) ± t* s p 1 n n 2 der P(T t*) = 0.05 slik at t*= fra en tabell over t(19)- fordeling. Der gir grensene [ (-0.273)] ± x = ± 5.579, slik at 90% konfidensintervallet blir (-0.306, ).
61 Det er vanskelig å verifisere antagelsen om at σ 1 = σ 2, slik at man skal være forsiktig med å bruke «the pooled procedure». Hvis utvalgene er omtrent like store, er metoden rimelig robust. Hvis utvalgene er av svært ulik størrelse, er metoden meget følsom for antagelsen om lik vatians. Forskjellig varians i de to populasjonene er vanlig.
Introduksjon til inferens
 Introduksjon til inferens Hittil: Populasjon der verdien til et individ/enhet beskrives med en fordeling. Her inngår vanligvis ukjente parametre, μ, p,... Enkelt tilfeldig utvalg (SRS), observator p =
Introduksjon til inferens Hittil: Populasjon der verdien til et individ/enhet beskrives med en fordeling. Her inngår vanligvis ukjente parametre, μ, p,... Enkelt tilfeldig utvalg (SRS), observator p =
Simulering med Applet fra boken, av z og t basert på en rekke utvalg av en gitt størrelse n fra N(μ,σ). Illustrerer hvordan estimering av variansen
. Illustrerer hvordan estimering av variansen") Simulering med Applet fra boken, av z og t basert på en rekke utvalg av en gitt størrelse n fra N(μ,σ). Illustrerer hvordan estimering av variansen gir testobservatoren t mer spredning enn testobservatoren
Simulering med Applet fra boken, av z og t basert på en rekke utvalg av en gitt størrelse n fra N(μ,σ). Illustrerer hvordan estimering av variansen gir testobservatoren t mer spredning enn testobservatoren
7.2 Sammenligning av to forventinger
 7.2 Sammenligning av to forventinger To-utvalgs z-observator To-utvalgs t-prosedyrer To-utvalgs t-tester To-utvalgs t-konfidensintervall Robusthet To-utvalgs t-prosedyrerår variansene er like Sammenlikning
7.2 Sammenligning av to forventinger To-utvalgs z-observator To-utvalgs t-prosedyrer To-utvalgs t-tester To-utvalgs t-konfidensintervall Robusthet To-utvalgs t-prosedyrerår variansene er like Sammenlikning
Denne uken: kap : Introduksjon til statistisk inferens. - Konfidensintervall - Hypotesetesting - P-verdier - Statistisk signifikans
 Denne uken: kap. 6.1-6.2-6.3: Introduksjon til statistisk inferens - Konfidensintervall - Hypotesetesting - P-verdier - Statistisk signifikans VG 25/9 2011 Statistisk inferens Mål: Trekke konklusjoner
Denne uken: kap. 6.1-6.2-6.3: Introduksjon til statistisk inferens - Konfidensintervall - Hypotesetesting - P-verdier - Statistisk signifikans VG 25/9 2011 Statistisk inferens Mål: Trekke konklusjoner
Kapittel 3: Studieopplegg
 Oversikt over pensum Kapittel 1: Empirisk fordeling for en variabel o Begrepet fordeling o Mål for senter (gj.snitt, median) + persentiler/kvartiler o Mål for spredning (Standardavvik s, IQR) o Outliere
Oversikt over pensum Kapittel 1: Empirisk fordeling for en variabel o Begrepet fordeling o Mål for senter (gj.snitt, median) + persentiler/kvartiler o Mål for spredning (Standardavvik s, IQR) o Outliere
Kort overblikk over kurset sålangt
 Kort overblikk over kurset sålangt Kapittel 1: Deskriptiv statististikk for en variabel Kapittel 2: Deskriptiv statistikk for samvariasjon mellom to variable (regresjon) Kapittel 3: Metoder for å innhente
Kort overblikk over kurset sålangt Kapittel 1: Deskriptiv statististikk for en variabel Kapittel 2: Deskriptiv statistikk for samvariasjon mellom to variable (regresjon) Kapittel 3: Metoder for å innhente
Denne uken: kap : Introduksjon til statistisk inferens. - Konfidensintervall - Hypotesetesting - P-verdier - Statistisk signifikans
 Denne uken: kap. 6.1-6.2-6.3: Introduksjon til statistisk inferens - Konfidensintervall - Hypotesetesting - P-verdier - Statistisk signifikans VG 25/9 2011 Statistisk inferens Mål: Trekke konklusjoner
Denne uken: kap. 6.1-6.2-6.3: Introduksjon til statistisk inferens - Konfidensintervall - Hypotesetesting - P-verdier - Statistisk signifikans VG 25/9 2011 Statistisk inferens Mål: Trekke konklusjoner
Fasit for tilleggsoppgaver
 Fasit for tilleggsoppgaver Uke 5 Oppgave: Gitt en rekke med observasjoner x i (i = 1,, 3,, n), definerer vi variansen til x i som gjennomsnittlig kvadratavvik fra gjennomsnittet, m.a.o. Var(x i ) = (x
Fasit for tilleggsoppgaver Uke 5 Oppgave: Gitt en rekke med observasjoner x i (i = 1,, 3,, n), definerer vi variansen til x i som gjennomsnittlig kvadratavvik fra gjennomsnittet, m.a.o. Var(x i ) = (x
Verdens statistikk-dag.
 Verdens statistikk-dag http://unstats.un.org/unsd/wsd/ Signifikanstester Ønsker å teste hypotese om populasjon Bruker data til å teste hypotese Typisk prosedyre Beregn sannsynlighet for utfall av observator
Verdens statistikk-dag http://unstats.un.org/unsd/wsd/ Signifikanstester Ønsker å teste hypotese om populasjon Bruker data til å teste hypotese Typisk prosedyre Beregn sannsynlighet for utfall av observator
6.2 Signifikanstester
 6.2 Signifikanstester Konfidensintervaller er nyttige når vi ønsker å estimere en populasjonsparameter Signifikanstester er nyttige dersom vi ønsker å teste en hypotese om en parameter i en populasjon
6.2 Signifikanstester Konfidensintervaller er nyttige når vi ønsker å estimere en populasjonsparameter Signifikanstester er nyttige dersom vi ønsker å teste en hypotese om en parameter i en populasjon
ST0103 Brukerkurs i statistikk Forelesning 26, 18. november 2016 Kapittel 8: Sammenligning av grupper
 ST0103 Brukerkurs i statistikk Forelesning 26, 18. november 2016 Kapittel 8: Sammenligning av grupper Bo Lindqvist Institutt for matematiske fag 2 Kapittel 8: Sammenligning av grupper Situasjon: Vi ønsker
ST0103 Brukerkurs i statistikk Forelesning 26, 18. november 2016 Kapittel 8: Sammenligning av grupper Bo Lindqvist Institutt for matematiske fag 2 Kapittel 8: Sammenligning av grupper Situasjon: Vi ønsker
Inferens i regresjon
 Strategi som er fulgt hittil: Inferens i regresjon Deskriptiv analyse og dataanalyse først. Analyse av en variabel før studie av samvariasjon. Emne for dette kapittel er inferens når det er en respons
Strategi som er fulgt hittil: Inferens i regresjon Deskriptiv analyse og dataanalyse først. Analyse av en variabel før studie av samvariasjon. Emne for dette kapittel er inferens når det er en respons
Kapittel 7: Inferens for forventningerukjent standardavvik
 Kapittel 7: Inferens for forventningerukjent standardavvik 7.1: Inferens for forventningen i en populasjon 7.2: Inferens for å sammenligne to forventninger 7.1 Inferens for forventningen i en populasjon
Kapittel 7: Inferens for forventningerukjent standardavvik 7.1: Inferens for forventningen i en populasjon 7.2: Inferens for å sammenligne to forventninger 7.1 Inferens for forventningen i en populasjon
Denne uken: kap. 6.1-6.2-6.3: Introduksjon til statistisk inferens. - Konfidensintervall - Hypotesetesting - P-verdier - Statistisk signifikans
 Denne uken: kap. 6.1-6.2-6.3: Introduksjon til statistisk inferens - Konfidensintervall - Hypotesetesting - P-verdier - Statistisk signifikans VG 25/9 2011 Statistisk inferens Mål: Trekke konklusjoner
Denne uken: kap. 6.1-6.2-6.3: Introduksjon til statistisk inferens - Konfidensintervall - Hypotesetesting - P-verdier - Statistisk signifikans VG 25/9 2011 Statistisk inferens Mål: Trekke konklusjoner
Verdens statistikk-dag. Signifikanstester. Eksempel studentlån. http://unstats.un.org/unsd/wsd/
 Verdens statistikk-dag http://unstats.un.org/unsd/wsd/ Signifikanstester Ønsker å teste hypotese om populasjon Bruker data til å teste hypotese Typisk prosedyre Beregn sannsynlighet for utfall av observator
Verdens statistikk-dag http://unstats.un.org/unsd/wsd/ Signifikanstester Ønsker å teste hypotese om populasjon Bruker data til å teste hypotese Typisk prosedyre Beregn sannsynlighet for utfall av observator
Kapittel 7: Inferens for forventningerukjent standardavvik
 Kapittel 7: Inferens for forventningerukjent standardavvik 7.1: Inferens for forventningen i en populasjon 7.: Inferens for å sammenligne to forventninger 7.1 Inferens for forventningen i en populasjon
Kapittel 7: Inferens for forventningerukjent standardavvik 7.1: Inferens for forventningen i en populasjon 7.: Inferens for å sammenligne to forventninger 7.1 Inferens for forventningen i en populasjon
I enkel lineær regresjon beskrev linja. μ y = β 0 + β 1 x
 Multiple regresjon Her utvider vi perspektivet for enkel lineær regresjon til også å omfatte flere forklaringsvariable.det er fortsatt en responsvariabel. Måten dette gjøre på er nokså naturlig. Prediktoren
Multiple regresjon Her utvider vi perspektivet for enkel lineær regresjon til også å omfatte flere forklaringsvariable.det er fortsatt en responsvariabel. Måten dette gjøre på er nokså naturlig. Prediktoren
Kapittel 9 og 10: Hypotesetesting
 Kapittel 9 og 1: Hypotesetesting Hypotesetesting er en standard vitenskapelig fremgangsmåte for å sjekke påstander. Generell problemstilling: Basert på informasjonen i data fra et tilfeldig utvalg ønsker
Kapittel 9 og 1: Hypotesetesting Hypotesetesting er en standard vitenskapelig fremgangsmåte for å sjekke påstander. Generell problemstilling: Basert på informasjonen i data fra et tilfeldig utvalg ønsker
ST0202 Statistikk for samfunnsvitere
 ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Kap. 10: Inferens om to populasjoner Situasjon: Vi ønsker å sammenligne to populasjoner med populasjonsgjennomsnitt henholdsvis
ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Kap. 10: Inferens om to populasjoner Situasjon: Vi ønsker å sammenligne to populasjoner med populasjonsgjennomsnitt henholdsvis
Statistikk og dataanalyse
 Njål Foldnes, Steffen Grønneberg og Gudmund Horn Hermansen Statistikk og dataanalyse En moderne innføring Kapitteloversikt del 1 INTRODUKSJON TIL STATISTIKK Kapittel 1 Populasjon og utvalg 19 Kapittel
Njål Foldnes, Steffen Grønneberg og Gudmund Horn Hermansen Statistikk og dataanalyse En moderne innføring Kapitteloversikt del 1 INTRODUKSJON TIL STATISTIKK Kapittel 1 Populasjon og utvalg 19 Kapittel
ST0202 Statistikk for samfunnsvitere
 ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Inferens om varians og standardavvik for ett normalfordelt utvalg (9.4) Inferens om variansen til en normalfordelt populasjon
ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Inferens om varians og standardavvik for ett normalfordelt utvalg (9.4) Inferens om variansen til en normalfordelt populasjon
Kap. 10: Inferens om to populasjoner. Eksempel. ST0202 Statistikk for samfunnsvitere
 Kap. 10: Inferens om to populasjoner Situasjon: Vi ønsker å sammenligne to populasjoner med populasjonsgjennomsnitt henholdsvis μ 1 og μ. Vi trekker da ett utvalg fra hver populasjon. ST00 Statistikk for
Kap. 10: Inferens om to populasjoner Situasjon: Vi ønsker å sammenligne to populasjoner med populasjonsgjennomsnitt henholdsvis μ 1 og μ. Vi trekker da ett utvalg fra hver populasjon. ST00 Statistikk for
i x i
 TMA4245 Statistikk Vår 2016 Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag Anbefalte oppgaver 11, blokk II Oppgavene i denne øvingen dreier seg om hypotesetesting og sentrale
TMA4245 Statistikk Vår 2016 Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag Anbefalte oppgaver 11, blokk II Oppgavene i denne øvingen dreier seg om hypotesetesting og sentrale
Utvalgsfordelinger. Utvalg er en tilfeldig mekanisme. Sannsynlighetsregning dreier seg om tilfeldige mekanismer.
 Utvalgsfordelinger Vi har sett at utvalgsfordelinger til en observator er fordelingen av verdiene observatoren tar ved mange gjenttatte utvalg av samme størrelse fra samme populasjon. Utvalg er en tilfeldig
Utvalgsfordelinger Vi har sett at utvalgsfordelinger til en observator er fordelingen av verdiene observatoren tar ved mange gjenttatte utvalg av samme størrelse fra samme populasjon. Utvalg er en tilfeldig
OPPGAVEHEFTE I STK1000 TIL KAPITTEL Regneoppgaver til kapittel 7. X 1,i, X 2 = 1 n 2. D = X 1 X 2. På onsdagsforelesningen påstod jeg at da må
 OPPGAVEHEFTE I STK000 TIL KAPITTEL 7 Regneoppgaver til kapittel 7 Oppgave Anta at man har resultatet av et randomisert forsøk med to grupper, og observerer fra gruppe, mens man observerer X,, X,2,, X,n
OPPGAVEHEFTE I STK000 TIL KAPITTEL 7 Regneoppgaver til kapittel 7 Oppgave Anta at man har resultatet av et randomisert forsøk med to grupper, og observerer fra gruppe, mens man observerer X,, X,2,, X,n
Statistisk inferens (kap. 8) Hovedtyper av statistisk inferens. ST0202 Statistikk for samfunnsvitere
 Hovedtyper av statistisk inferens. ST0202 Statistikk for samfunnsvitere") 2 Statistisk inferens (kap. 8) Statistisk inferens er å tolke/analysere resultater fra utvalget for å finne ut mest mulig om populasjonen. Konkret: Å analysere en utvalgsobservator for å trekke slutninger
2 Statistisk inferens (kap. 8) Statistisk inferens er å tolke/analysere resultater fra utvalget for å finne ut mest mulig om populasjonen. Konkret: Å analysere en utvalgsobservator for å trekke slutninger
STK1000 Uke 36, Studentene forventes å lese Ch 1.4 ( ) i læreboka (MMC). Tetthetskurver. Eksempel: Drivstofforbruk hos 32 biler
 i læreboka (MMC). Tetthetskurver. Eksempel: Drivstofforbruk hos 32 biler") STK1000 Uke 36, 2016. Studentene forventes å lese Ch 1.4 (+ 3.1-3.3 + 3.5) i læreboka (MMC). Tetthetskurver Eksempel: Drivstofforbruk hos 32 biler Fra histogram til tetthetskurver Anta at vi har kontinuerlige
STK1000 Uke 36, 2016. Studentene forventes å lese Ch 1.4 (+ 3.1-3.3 + 3.5) i læreboka (MMC). Tetthetskurver Eksempel: Drivstofforbruk hos 32 biler Fra histogram til tetthetskurver Anta at vi har kontinuerlige
Notasjon og Tabell 8. ST0202 Statistikk for samfunnsvitere
 2 Inferens om varians og standardavvik for ett normalfordelt utvalg (9.4) Inferens om variansen til en normalfordelt populasjon bruker kjikvadrat-fordelingen ( chi-square distribution ) (der kji er den
2 Inferens om varians og standardavvik for ett normalfordelt utvalg (9.4) Inferens om variansen til en normalfordelt populasjon bruker kjikvadrat-fordelingen ( chi-square distribution ) (der kji er den
I dag. Konfidensintervall og hypotesetes4ng ukjent standardavvik (kap. 7.1) t-fordelingen
 t-fordelingen") I dag Konfidensintervall og hypotesetes4ng ukjent standardavvik (kap. 7.1) t-fordelingen Inferens for forventningen 4l en populasjon (7.1) Kapi@el 6: En antagelse om kjent standardavvik s i populasjonen
I dag Konfidensintervall og hypotesetes4ng ukjent standardavvik (kap. 7.1) t-fordelingen Inferens for forventningen 4l en populasjon (7.1) Kapi@el 6: En antagelse om kjent standardavvik s i populasjonen
ST0202 Statistikk for samfunnsvitere
 ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Statistisk inferens (kap. 8) Statistisk inferens er å tolke/analysere resultater fra utvalget for å finne ut mest mulig
ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Statistisk inferens (kap. 8) Statistisk inferens er å tolke/analysere resultater fra utvalget for å finne ut mest mulig
Statistisk inferens (kap. 8) Hovedtyper av statistisk inferens. ST0202 Statistikk for samfunnsvitere
 Hovedtyper av statistisk inferens. ST0202 Statistikk for samfunnsvitere") 2 Statistisk inferens (kap. 8) Statistisk inferens er å tolke/analysere resultater fra utvalget for å finne ut mest mulig om populasjonen. Konkret: Analysere en observator for å finne ut noe om korresponderende
2 Statistisk inferens (kap. 8) Statistisk inferens er å tolke/analysere resultater fra utvalget for å finne ut mest mulig om populasjonen. Konkret: Analysere en observator for å finne ut noe om korresponderende
TMA4240 Statistikk Høst 2016
 TMA4240 Statistikk Høst 2016 Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag Anbefalt øving 11 Oppgavene i denne øvingen dreier seg om hypotesetesting og sentrale begreper
TMA4240 Statistikk Høst 2016 Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag Anbefalt øving 11 Oppgavene i denne øvingen dreier seg om hypotesetesting og sentrale begreper
Utvalgsfordelinger. Utvalg er en tilfeldig mekanisme. Sannsynlighetsregning dreier seg om tilfeldige mekanismer.
 Utvalgsfordelinger Vi har sett at utvalgsfordelinger til en statistikk (observator) er fordelingen av verdiene statistikken tar ved mange gjenttatte utvalg av samme størrelse fra samme populasjon. Utvalg
Utvalgsfordelinger Vi har sett at utvalgsfordelinger til en statistikk (observator) er fordelingen av verdiene statistikken tar ved mange gjenttatte utvalg av samme størrelse fra samme populasjon. Utvalg
ST0202 Statistikk for samfunnsvitere
 ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Statistisk inferens (kap. 8) Statistisk inferens er å tolke/analysere resultater fra utvalget for å finne ut mest mulig
ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Statistisk inferens (kap. 8) Statistisk inferens er å tolke/analysere resultater fra utvalget for å finne ut mest mulig
ST0202 Statistikk for samfunnsvitere
 ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Kap. 10: Inferens om to populasjoner Situasjon: Det er to populasjoner som vi ønsker å sammenligne. Vi trekker da et utvalg
ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Kap. 10: Inferens om to populasjoner Situasjon: Det er to populasjoner som vi ønsker å sammenligne. Vi trekker da et utvalg
ST0202 Statistikk for samfunnsvitere
 ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Kap. 9: Inferens om én populasjon I Kapittel 8 brukte vi observatoren z = x µ σ/ n for å trekke konklusjoner om µ. Dette
ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Kap. 9: Inferens om én populasjon I Kapittel 8 brukte vi observatoren z = x µ σ/ n for å trekke konklusjoner om µ. Dette
ST0202 Statistikk for samfunnsvitere Kapittel 9: Inferens om én populasjon
 ST0202 Statistikk for samfunnsvitere Kapittel 9: Inferens om én populasjon Bo Lindqvist Institutt for matematiske fag 2 Kap. 9: Inferens om én populasjon Statistisk inferens har som mål å tolke/analysere
ST0202 Statistikk for samfunnsvitere Kapittel 9: Inferens om én populasjon Bo Lindqvist Institutt for matematiske fag 2 Kap. 9: Inferens om én populasjon Statistisk inferens har som mål å tolke/analysere
UNIVERSITETET I OSLO
 UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i: STK1110 Løsningsforslag: Statistiske metoder og dataanalys Eksamensdag: Fredag 9. desember 2011 Tid for eksamen: 14.30 18.30
UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i: STK1110 Løsningsforslag: Statistiske metoder og dataanalys Eksamensdag: Fredag 9. desember 2011 Tid for eksamen: 14.30 18.30
Løsningsforslag Til Statlab 5
 Løsningsforslag Til Statlab 5 Jimmy Paul September 6, 007 Oppgave 8.1 Vi skal se på ukentlige forbruk av søtsaker blant barn i et visst område. En pilotstudie gir at standardavviket til det ukentige forbruket
Løsningsforslag Til Statlab 5 Jimmy Paul September 6, 007 Oppgave 8.1 Vi skal se på ukentlige forbruk av søtsaker blant barn i et visst område. En pilotstudie gir at standardavviket til det ukentige forbruket
Oppgave 1. X 1 B(n 1, p 1 ) X 2. Vi er interessert i forskjellen i andeler p 1 p 2, som vi estimerer med. p 1 p 2 = X 1. n 1 n 2.
 X 2. Vi er interessert i forskjellen i andeler p 1 p 2, som vi estimerer med. p 1 p 2 = X 1. n 1 n 2.") Løsningsforslag til eksamen i MOT310 STATISTISKE METODER 1 VARIGHET: 4 TIMER DATO: 17 november 2008 TILLATTE HJELPEMIDLER: Kalkulator: HP30S, Casio FX82 eller TI-30 Tabeller og formler i statistikk Tapir
Løsningsforslag til eksamen i MOT310 STATISTISKE METODER 1 VARIGHET: 4 TIMER DATO: 17 november 2008 TILLATTE HJELPEMIDLER: Kalkulator: HP30S, Casio FX82 eller TI-30 Tabeller og formler i statistikk Tapir
UNIVERSITETET I OSLO
 UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i: STK1000 Innføring i anvendt statistikk Eksamensdag: Onsdag 12. oktober 2016 Tid for eksamen: 10.00 12.00 Oppgavesettet er på
UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i: STK1000 Innføring i anvendt statistikk Eksamensdag: Onsdag 12. oktober 2016 Tid for eksamen: 10.00 12.00 Oppgavesettet er på
EKSAMENSOPPGAVER STAT100 Vår 2011
 EKSAMENSOPPGAVER STAT100 Vår 2011 Løsningsforslag Oppgave 1 (Med referanse til Tabell 1) a) De 3 fiskene på 2 år hadde lengder på henholdsvis 48, 46 og 35 cm. Finn de manglende tallene i Tabell 1. Test
EKSAMENSOPPGAVER STAT100 Vår 2011 Løsningsforslag Oppgave 1 (Med referanse til Tabell 1) a) De 3 fiskene på 2 år hadde lengder på henholdsvis 48, 46 og 35 cm. Finn de manglende tallene i Tabell 1. Test
Et lite notat om og rundt normalfordelingen.
 Et lite notat om og rundt normalfordelingen. Anta at vi har kontinuerlige data. Hva er likt og ulikt for histogrammer og fordelingskurver? Observasjoner Histogram Viser fordelingen av faktiske observerte
Et lite notat om og rundt normalfordelingen. Anta at vi har kontinuerlige data. Hva er likt og ulikt for histogrammer og fordelingskurver? Observasjoner Histogram Viser fordelingen av faktiske observerte
TMA4245 Statistikk Eksamen desember 2016
 Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag TMA4245 Statistikk Eksamen desember 2016 Oppgave 1 En bedrift produserer elektriske komponenter. Komponentene kan ha to typer
Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag TMA4245 Statistikk Eksamen desember 2016 Oppgave 1 En bedrift produserer elektriske komponenter. Komponentene kan ha to typer
Seksjon 1.3 Tetthetskurver og normalfordelingen
 Seksjon 1.3 Tetthetskurver og normalfordelingen Har sett på ulike metoder for å plotte eller oppsummere data ved tall Vil nå starte på hvordan beskrive data ved modeller Hovedmetode er tetthetskurver Tetthetskurver
Seksjon 1.3 Tetthetskurver og normalfordelingen Har sett på ulike metoder for å plotte eller oppsummere data ved tall Vil nå starte på hvordan beskrive data ved modeller Hovedmetode er tetthetskurver Tetthetskurver
HØGSKOLEN I STAVANGER
 EKSAMEN I: MOT0 STATISTISKE METODER VARIGHET: TIMER DATO:. NOVEMBER 00 TILLATTE HJELPEMIDLER: KALKULATOR, TABELLER OG FORMLER I STATISTIKK (TAPIR FORLAG) OPPGAVESETTET BESTÅR AV OPPGAVER PÅ 7 SIDER HØGSKOLEN
EKSAMEN I: MOT0 STATISTISKE METODER VARIGHET: TIMER DATO:. NOVEMBER 00 TILLATTE HJELPEMIDLER: KALKULATOR, TABELLER OG FORMLER I STATISTIKK (TAPIR FORLAG) OPPGAVESETTET BESTÅR AV OPPGAVER PÅ 7 SIDER HØGSKOLEN
Et lite notat om og rundt normalfordelingen. Anta at vi har kontinuerlige data. Hva er likt og ulikt for histogrammer og fordelingskurver?
 Et lite notat om og rundt normalfordelingen. Anta at vi har kontinuerlige data. Hva er likt og ulikt for histogrammer og fordelingskurver? Boka (Ch 1.4) motiverer dette ved å gå fra histogrammer til tetthetskurver.
Et lite notat om og rundt normalfordelingen. Anta at vi har kontinuerlige data. Hva er likt og ulikt for histogrammer og fordelingskurver? Boka (Ch 1.4) motiverer dette ved å gå fra histogrammer til tetthetskurver.
Hypotesetest: generell fremgangsmåte
 TMA4240 Statistikk H2010 (21) 10.8, 10.10: To normalfordelte utvalg 10.9: Teststyrke og antall observasjoner Mette Langaas Foreleses mandag 1.november, 2010 2 Hypotesetest: generell fremgangsmåte Generell
TMA4240 Statistikk H2010 (21) 10.8, 10.10: To normalfordelte utvalg 10.9: Teststyrke og antall observasjoner Mette Langaas Foreleses mandag 1.november, 2010 2 Hypotesetest: generell fremgangsmåte Generell
Løsningsforslag eksamen 27. februar 2004
 MOT30 Statistiske metoder Løsningsforslag eksamen 7 februar 004 Oppgave a) Y ij = µ i + ε ij, der ε ij uavh N(0, σ ) der µ i er forventa kopperinnhold for legering i og ε ij er feilleddet (tilfeldig variasjon)
MOT30 Statistiske metoder Løsningsforslag eksamen 7 februar 004 Oppgave a) Y ij = µ i + ε ij, der ε ij uavh N(0, σ ) der µ i er forventa kopperinnhold for legering i og ε ij er feilleddet (tilfeldig variasjon)
LØSNINGSFORSLAG ) = Dvs
 = Dvs") LØSNINGSFORSLAG 12 OPPGAVE 1 D j er differansen mellom måling j med metode A og metode B. D j N(µ D, 0.1 2 ). H 0 : µ D = 0 mot alternativet H 1 : µ D > 0. Vi forkaster om ˆµ D > k Under H 0 er ˆµ D =
LØSNINGSFORSLAG 12 OPPGAVE 1 D j er differansen mellom måling j med metode A og metode B. D j N(µ D, 0.1 2 ). H 0 : µ D = 0 mot alternativet H 1 : µ D > 0. Vi forkaster om ˆµ D > k Under H 0 er ˆµ D =
ST0202 Statistikk for samfunnsvitere
 ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Kap. 13: Lineær korrelasjons- og regresjonsanalyse Kap. 13.1-13.3: Lineær korrelasjonsanalyse. Disse avsnitt er ikke pensum,
ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Kap. 13: Lineær korrelasjons- og regresjonsanalyse Kap. 13.1-13.3: Lineær korrelasjonsanalyse. Disse avsnitt er ikke pensum,
Utvalgsfordelinger (Kapittel 5)
") Utvalgsfordelinger (Kapittel 5) Oversikt pensum, fortid og fremtid Eksplorativ data-analyse (Kap 1, 2) Hvordan produsere data (Kap 3) Sannsynlighetsteori (Kap 4) Utvalgsfordelinger til observatorer (Kap
Utvalgsfordelinger (Kapittel 5) Oversikt pensum, fortid og fremtid Eksplorativ data-analyse (Kap 1, 2) Hvordan produsere data (Kap 3) Sannsynlighetsteori (Kap 4) Utvalgsfordelinger til observatorer (Kap
TMA4240 Statistikk H2010 (20)
") TMA4240 Statistikk H2010 (20) 10.5: Ett normalfordelt utvalg, kjent varians (repetisjon) 10.4: P-verdi 10.6: Konfidensintervall vs. hypotesetest 10.7: Ett normalfordelt utvalg, ukjent varians Mette Langaas
TMA4240 Statistikk H2010 (20) 10.5: Ett normalfordelt utvalg, kjent varians (repetisjon) 10.4: P-verdi 10.6: Konfidensintervall vs. hypotesetest 10.7: Ett normalfordelt utvalg, ukjent varians Mette Langaas
Ferdig før tiden 4 7 Ferdig til avtalt tid 12 7 Forsinket 1 måned 2 6 Forsinket 2 måneder 4 4 Forsinket 3 måneder 6 2 Forsinket 4 måneder 0 2
 Besvar alle oppgavene. Hver deloppgave har lik vekt. Oppgave I En kommune skal bygge ny idrettshall og vurderer to entreprenører, A og B. Begge gir samme pristilbud, men kommunen er bekymret for forsinkelser.
Besvar alle oppgavene. Hver deloppgave har lik vekt. Oppgave I En kommune skal bygge ny idrettshall og vurderer to entreprenører, A og B. Begge gir samme pristilbud, men kommunen er bekymret for forsinkelser.
TMA4240 Statistikk H2010
 TMA4240 Statistikk H2010 Statistisk inferens: 8.1: Tilfeldig utvalg 9.1-9.3: Estimering Mette Langaas Foreleses uke 40, 2010 2 Utfordring Ved en bedrift produseres en elektrisk komponent. Komponenten må
TMA4240 Statistikk H2010 Statistisk inferens: 8.1: Tilfeldig utvalg 9.1-9.3: Estimering Mette Langaas Foreleses uke 40, 2010 2 Utfordring Ved en bedrift produseres en elektrisk komponent. Komponenten må
Utfordring. TMA4240 Statistikk H2010. Mette Langaas. Foreleses uke 40, 2010
 TMA4240 Statistikk H2010 Statistisk inferens: 8.1: Tilfeldig utvalg 9.1-9.3: Estimering Mette Langaas Foreleses uke 40, 2010 2 Utfordring Ved en bedrift produseres en elektrisk komponent. Komponenten må
TMA4240 Statistikk H2010 Statistisk inferens: 8.1: Tilfeldig utvalg 9.1-9.3: Estimering Mette Langaas Foreleses uke 40, 2010 2 Utfordring Ved en bedrift produseres en elektrisk komponent. Komponenten må
Et lite notat om og rundt normalfordelingen.
 Et lite notat om og rundt normalfordelingen. Anta at vi har kontinuerlige data. Hva er likt og ulikt for histogrammer og fordelingskurver? Observasjoner Histogram Viser fordelingen av faktiske observerte
Et lite notat om og rundt normalfordelingen. Anta at vi har kontinuerlige data. Hva er likt og ulikt for histogrammer og fordelingskurver? Observasjoner Histogram Viser fordelingen av faktiske observerte
Løsningsforslag Eksamen i Statistikk SIF5060 Aug 2002
 Løsningsforslag Eksamen i Statistikk SIF5060 Aug 2002 Oppgave 1 a) En god estimator er forventningsrett og har liten varians. Vi tester forventningsretthet: E[ˆµ] E[Y ] µ E[ µ] E[ 1 2 X + 1 2 Y ] 1 2 E[X]
Løsningsforslag Eksamen i Statistikk SIF5060 Aug 2002 Oppgave 1 a) En god estimator er forventningsrett og har liten varians. Vi tester forventningsretthet: E[ˆµ] E[Y ] µ E[ µ] E[ 1 2 X + 1 2 Y ] 1 2 E[X]
ÅMA110 Sannsynlighetsregning med statistikk, våren 2006 Kp. 6, del 4
 ÅMA110 Sannsynlighetsregning med statistikk, våren 2006 Kp. 6, del 4 Bjørn H. Auestad Institutt for matematikk og naturvitenskap Universitetet i Stavanger 27. mars Bjørn H. Auestad Kp. 6: Hypotesetesting
ÅMA110 Sannsynlighetsregning med statistikk, våren 2006 Kp. 6, del 4 Bjørn H. Auestad Institutt for matematikk og naturvitenskap Universitetet i Stavanger 27. mars Bjørn H. Auestad Kp. 6: Hypotesetesting
Eksempel på data: Karakterer i «Stat class» Introduksjon
 Eksempel på data: Karakterer i «Stat class» Introduksjon Viktige begreper for å beskrive data: Enheter som er objektene i datasettet «label» som av og til brukes for å skille enhetene En variabel er en
Eksempel på data: Karakterer i «Stat class» Introduksjon Viktige begreper for å beskrive data: Enheter som er objektene i datasettet «label» som av og til brukes for å skille enhetene En variabel er en
TMA4240 Statistikk H2010 (22)
") TMA4240 Statistikk H2010 (22) 10.11-10.12: Testing av andelser 10.13: Testing av varians i ett N utvalg Mette Langaas Foreleses onsdag 3.november, 2010 2 Laban strakk seg ikke lenger, men smaker den bedre?
TMA4240 Statistikk H2010 (22) 10.11-10.12: Testing av andelser 10.13: Testing av varians i ett N utvalg Mette Langaas Foreleses onsdag 3.november, 2010 2 Laban strakk seg ikke lenger, men smaker den bedre?
TMA4240 Statistikk 2014
 TMA4240 Statistikk 2014 Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag Øving nummer 12, blokk II Oppgave 1 På ein av vegane inn til Trondheim er UP interessert i å måle effekten
TMA4240 Statistikk 2014 Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag Øving nummer 12, blokk II Oppgave 1 På ein av vegane inn til Trondheim er UP interessert i å måle effekten
Hypotesetesting. Hvorfor og hvordan? Gardermoen 21. april 2016 Ørnulf Borgan. H. Aschehoug & Co Sehesteds gate 3, 0102 Oslo Tlf:
 Hypotesetesting Hvorfor og hvordan? Gardermoen 21. april 2016 Ørnulf Borgan H. Aschehoug & Co Sehesteds gate 3, 0102 Oslo Tlf: 22 400 400 www.aschehoug.no 1 Oversikt Sannsynlighetsregning og statistikk
Hypotesetesting Hvorfor og hvordan? Gardermoen 21. april 2016 Ørnulf Borgan H. Aschehoug & Co Sehesteds gate 3, 0102 Oslo Tlf: 22 400 400 www.aschehoug.no 1 Oversikt Sannsynlighetsregning og statistikk
TMA4240 Statistikk H2010
 TMA4240 Statistikk H2010 Statistisk inferens: 9.6: Prediksjonsintervall 9.8: To utvalg, differanse µ 1 µ 2 Mette Langaas Foreleses mandag 18.oktober, 2010 2 Prediksjonsintervall for fremtidig observasjon,
TMA4240 Statistikk H2010 Statistisk inferens: 9.6: Prediksjonsintervall 9.8: To utvalg, differanse µ 1 µ 2 Mette Langaas Foreleses mandag 18.oktober, 2010 2 Prediksjonsintervall for fremtidig observasjon,
Hypotesetesting. mot. mot. mot. ˆ x
 Kapittel 6.4-6.5: ypotesetesting ypotesetesting er en standard vitenskapelig fremgangsmåte for å sjekke påstander. Generell problemstilling: Basert på informasjonen i data fra et tilfeldig utvalg ønsker
Kapittel 6.4-6.5: ypotesetesting ypotesetesting er en standard vitenskapelig fremgangsmåte for å sjekke påstander. Generell problemstilling: Basert på informasjonen i data fra et tilfeldig utvalg ønsker
Kapittel 9 og 10: Hypotesetesting
 Kapittel 9 og 1: ypotesetesting ypotesetesting er en standard vitenskapelig fremgangsmåte for å sjekke påstander. Generell problemstilling: Basert på informasjonen i data fra et tilfeldig utvalg ønsker
Kapittel 9 og 1: ypotesetesting ypotesetesting er en standard vitenskapelig fremgangsmåte for å sjekke påstander. Generell problemstilling: Basert på informasjonen i data fra et tilfeldig utvalg ønsker
HØGSKOLEN I STAVANGER
 HØGSKOLEN I STAVANGER Avdeling for TEKNISK NATURVITEN- EKSAMEN I: TE199 SANNSYNLIGHETSREGNING MED STATISTIKK SKAPELIGE FAG VARIGHET: 4 TIMER DATO: 5. JUNI 2003 TILLATTE HJELPEMIDLER: KALKULATOR OPPGAVESETTET
HØGSKOLEN I STAVANGER Avdeling for TEKNISK NATURVITEN- EKSAMEN I: TE199 SANNSYNLIGHETSREGNING MED STATISTIKK SKAPELIGE FAG VARIGHET: 4 TIMER DATO: 5. JUNI 2003 TILLATTE HJELPEMIDLER: KALKULATOR OPPGAVESETTET
Kapittel 4.4: Forventning og varians til stokastiske variable
 Kapittel 4.4: Forventning og varians til stokastiske variable Forventning og varians til stokastiske variable Histogrammer for observerte data: Sannsynlighets-histogrammer og tetthetskurver for stokastiske
Kapittel 4.4: Forventning og varians til stokastiske variable Forventning og varians til stokastiske variable Histogrammer for observerte data: Sannsynlighets-histogrammer og tetthetskurver for stokastiske
Forelesning 6: Punktestimering, usikkerhet i estimering. Jo Thori Lind
 Forelesning 6: Punktestimering, usikkerhet i estimering Jo Thori Lind j.t.lind@econ.uio.no Oversikt 1. Trekke utvalg 2. Estimatorer og observatorer som stokastiske variable 3. Egenskapene til en estimator
Forelesning 6: Punktestimering, usikkerhet i estimering Jo Thori Lind j.t.lind@econ.uio.no Oversikt 1. Trekke utvalg 2. Estimatorer og observatorer som stokastiske variable 3. Egenskapene til en estimator
Oppgave 1. T = 9 Hypotesetest for å teste om kolesterolnivået har endret seg etter dietten: T observert = 2.16 0
 Løsningsforslag til eksamen i MOT310 STATISTISKE METODER 1 VARIGHET: 4 TIMER DATO: 08. mai 2008 TILLATTE HJELPEMIDLER: Kalkulator: HP30S, Casio FX82 eller TI-30 Tabeller og formler i statistikk (Tapir
Løsningsforslag til eksamen i MOT310 STATISTISKE METODER 1 VARIGHET: 4 TIMER DATO: 08. mai 2008 TILLATTE HJELPEMIDLER: Kalkulator: HP30S, Casio FX82 eller TI-30 Tabeller og formler i statistikk (Tapir
UNIVERSITETET I OSLO
 UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i: STK1000 Innføring i anvendt statistikk Eksamensdag: Fredag 28. oktober 2016 Tid for eksamen: 14.00 16.00 Oppgavesettet er på
UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i: STK1000 Innføring i anvendt statistikk Eksamensdag: Fredag 28. oktober 2016 Tid for eksamen: 14.00 16.00 Oppgavesettet er på
ST0202 Statistikk for samfunnsvitere
 ST0202 Statistikk for samfunnsvitere Kapittel 7: Utvalgsfordeling Bo Lindqvist Institutt for matematiske fag 2 Fra kapittel 1: Populasjon Den mengden av individer/objekter som vi ønsker å analysere. Utvalg
ST0202 Statistikk for samfunnsvitere Kapittel 7: Utvalgsfordeling Bo Lindqvist Institutt for matematiske fag 2 Fra kapittel 1: Populasjon Den mengden av individer/objekter som vi ønsker å analysere. Utvalg
Seksjon 1.3 Tetthetskurver og normalfordelingen
 Seksjon 1.3 Tetthetskurver og normalfordelingen Har sett på ulike metoder for å plotte eller oppsummere data Vil nå starte på hvordan beskrive data ved modeller Hovedmetode er tetthetskurver Tetthetskurver
Seksjon 1.3 Tetthetskurver og normalfordelingen Har sett på ulike metoder for å plotte eller oppsummere data Vil nå starte på hvordan beskrive data ved modeller Hovedmetode er tetthetskurver Tetthetskurver
Løsningsforslag til andre sett med obligatoriske oppgaver i STK1110 høsten 2010
 Løsningsforslag til andre sett med obligatoriske oppgaver i STK1110 høsten 2010 Oppgave 1 a Forventet antall dødsulykker i år i er E(X i λ i. Dermed er θ i λ i E(X i forventet antall dødsulykker per 100
Løsningsforslag til andre sett med obligatoriske oppgaver i STK1110 høsten 2010 Oppgave 1 a Forventet antall dødsulykker i år i er E(X i λ i. Dermed er θ i λ i E(X i forventet antall dødsulykker per 100
Multippel regresjon. Her utvider vi perspektivet for enkel lineær regresjon til også å omfatte flere forklaringsvariable x 1, x 2,, x p.
 Multippel regresjon Her utvider vi perspektivet for enkel lineær regresjon til også å omfatte flere forklaringsvariable x 1, x 2,, x p. Det er fortsatt en responsvariabel y. Måten dette gjøre på er nokså
Multippel regresjon Her utvider vi perspektivet for enkel lineær regresjon til også å omfatte flere forklaringsvariable x 1, x 2,, x p. Det er fortsatt en responsvariabel y. Måten dette gjøre på er nokså
+ S2 Y ) 2. = 6.737 6 (avrundet nedover til nærmeste heltall) n Y 1
 2. = 6.737 6 (avrundet nedover til nærmeste heltall) n Y 1") Løsningsforslag for: MOT10 STATISTISKE METODER 1 VARIGHET: 4 TIMER DATO: 6. november 007 TILLATTE HJELPEMIDLER: Kalkulator: HP0S, Casio FX8 eller TI-0 Tabeller og formler i statistikk (Tapir forlag) MERKNADER:
Løsningsforslag for: MOT10 STATISTISKE METODER 1 VARIGHET: 4 TIMER DATO: 6. november 007 TILLATTE HJELPEMIDLER: Kalkulator: HP0S, Casio FX8 eller TI-0 Tabeller og formler i statistikk (Tapir forlag) MERKNADER:
Kp. 9.8 Forskjell mellom to forventninger
 andeler I analysene skal vi se på situasjonene der σx og σ Y er kjente; normalantakelse a σx og σ Y er ukjente men σ X = σ Y ; normalantakelse og b σx og σ Y er ukjente og σ X σ Y ; normalantakelse 3 og
andeler I analysene skal vi se på situasjonene der σx og σ Y er kjente; normalantakelse a σx og σ Y er ukjente men σ X = σ Y ; normalantakelse og b σx og σ Y er ukjente og σ X σ Y ; normalantakelse 3 og
Løsningsforslag eksamen 25. november 2003
 MOT310 Statistiske metoder 1 Løsningsforslag eksamen 25. november 2003 Oppgave 1 a) Vi har µ D = µ X µ Y. Sangere bruker generelt trapesius-muskelen mindre etter biofeedback dersom forventet bruk av trapesius
MOT310 Statistiske metoder 1 Løsningsforslag eksamen 25. november 2003 Oppgave 1 a) Vi har µ D = µ X µ Y. Sangere bruker generelt trapesius-muskelen mindre etter biofeedback dersom forventet bruk av trapesius
UNIVERSITETET I OSLO Matematisk Institutt
 UNIVERSITETET I OSLO Matematisk Institutt Midtveiseksamen i: STK 1000: Innføring i anvendt statistikk Tid for eksamen: Onsdag 9. oktober 2013, 11:00 13:00 Hjelpemidler: Lærebok, ordliste for STK1000, godkjent
UNIVERSITETET I OSLO Matematisk Institutt Midtveiseksamen i: STK 1000: Innføring i anvendt statistikk Tid for eksamen: Onsdag 9. oktober 2013, 11:00 13:00 Hjelpemidler: Lærebok, ordliste for STK1000, godkjent
Løsningsforslag: STK2120-v15.
 Løsningsforslag: STK2120-v15 Oppgave 1 a) Den statistiske modellen er: X ij = µ i + ϵ ij, j = 1,, J, i = 1,, I Her indekserer i = 1,, I gruppene og j = 1,, J observasjone innen hver gruppe Feilleddene
Løsningsforslag: STK2120-v15 Oppgave 1 a) Den statistiske modellen er: X ij = µ i + ϵ ij, j = 1,, J, i = 1,, I Her indekserer i = 1,, I gruppene og j = 1,, J observasjone innen hver gruppe Feilleddene
Snøtetthet. Institutt for matematiske fag, NTNU 15. august Notat for TMA4240/TMA4245 Statistikk
 Snøtetthet Notat for TMA424/TMA4245 Statistikk Institutt for matematiske fag, NTNU 5. august 22 I forbindelse med varsling av om, klimaforskning og særlig kraftproduksjon er det viktig å kunne anslå hvor
Snøtetthet Notat for TMA424/TMA4245 Statistikk Institutt for matematiske fag, NTNU 5. august 22 I forbindelse med varsling av om, klimaforskning og særlig kraftproduksjon er det viktig å kunne anslå hvor
ST0202 Statistikk for samfunnsvitere
 ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Fra første forelesning: Populasjon Den mengden av individer/objekter som vi ønsker å analysere. Utvalg En delmengde av
ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Fra første forelesning: Populasjon Den mengden av individer/objekter som vi ønsker å analysere. Utvalg En delmengde av
Supplement til power-point presentasjonen i medisinsk statistikk, forelesning 7 januar 2013. Skrevet av Stian Lydersen 16 januar 2013
 1 Supplement til power-point presentasjonen i medisinsk statistikk, forelesning 7 januar 013. Skrevet av Stian Lydersen 16 januar 013 Vi antar at vårt utvalg er et tilfeldig og representativt utvalg for
1 Supplement til power-point presentasjonen i medisinsk statistikk, forelesning 7 januar 013. Skrevet av Stian Lydersen 16 januar 013 Vi antar at vårt utvalg er et tilfeldig og representativt utvalg for
ST0202 Statistikk for samfunnsvitere Kapittel 10: Inferens om to populasjoner
 ST0202 Statistikk for samfunnsvitere Kapittel 10: Inferens om to populasjoner Bo Lindqvist Institutt for matematiske fag 2 Kapittel 10: Inferens om to populasjoner Situasjon: Vi ønsker å sammenligne to
ST0202 Statistikk for samfunnsvitere Kapittel 10: Inferens om to populasjoner Bo Lindqvist Institutt for matematiske fag 2 Kapittel 10: Inferens om to populasjoner Situasjon: Vi ønsker å sammenligne to
Eksamensoppgave i TMA4240 Statistikk
 Institutt for matematiske fag Eksamensoppgave i TMA4240 Statistikk Faglig kontakt under eksamen: Mette Langaas a, Ingelin Steinsland b, Geir-Arne Fuglstad c Tlf: a 988 47 649, b 926 63 096, c 452 70 806
Institutt for matematiske fag Eksamensoppgave i TMA4240 Statistikk Faglig kontakt under eksamen: Mette Langaas a, Ingelin Steinsland b, Geir-Arne Fuglstad c Tlf: a 988 47 649, b 926 63 096, c 452 70 806
TMA4240 Statistikk Høst 2015
 TMA4240 Statistikk Høst 2015 Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag Øving nummer 11, blokk II I denne øvingen skal vi fokusere på hypotesetesting. Vi ønsker å gi dere
TMA4240 Statistikk Høst 2015 Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag Øving nummer 11, blokk II I denne øvingen skal vi fokusere på hypotesetesting. Vi ønsker å gi dere
Fra første forelesning:
 2 Fra første forelesning: ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag opulasjon Den mengden av individer/objekter som vi ønsker å analysere. Utvalg En delmengde av populasjonen
2 Fra første forelesning: ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag opulasjon Den mengden av individer/objekter som vi ønsker å analysere. Utvalg En delmengde av populasjonen
TMA4240 Statistikk Høst 2018
 TMA4240 Statistikk Høst 2018 Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag Innlevering 5 Dette er andre av tre innleveringer i blokk 2. Denne øvingen skal oppsummere pensum
TMA4240 Statistikk Høst 2018 Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag Innlevering 5 Dette er andre av tre innleveringer i blokk 2. Denne øvingen skal oppsummere pensum
Oppgaven består av 9 delspørsmål som anbefales å veie like mye. Kommentarer og tallsvar er skrevet inn mellom << >>. Oppgave 1
 ECON 0 EKSMEN 007 VÅR SENSORVEILEDNING Oppgaven består av 9 delspørsmål som anbefales å veie like mye. Kommentarer og tallsvar er skrevet inn mellom >. Oppgave. La begivenhetene BC,, være slik at og
ECON 0 EKSMEN 007 VÅR SENSORVEILEDNING Oppgaven består av 9 delspørsmål som anbefales å veie like mye. Kommentarer og tallsvar er skrevet inn mellom >. Oppgave. La begivenhetene BC,, være slik at og
EKSAMEN I FAG TMA4260 INDUSTRIELL STATISTIKK
 Norges teknisk naturvitenskapelige universitet Institutt for matematiske fag Side 1 av 12 Faglig kontakt under eksamen: Bo Lindqvist Tlf. 975 89 418 EKSAMEN I FAG TMA4260 INDUSTRIELL STATISTIKK Onsdag
Norges teknisk naturvitenskapelige universitet Institutt for matematiske fag Side 1 av 12 Faglig kontakt under eksamen: Bo Lindqvist Tlf. 975 89 418 EKSAMEN I FAG TMA4260 INDUSTRIELL STATISTIKK Onsdag
Gruppe 1 Gruppe 2 Gruppe a) Finn aritmetisk gjennomsnitt, median, modus og standardavvik for gruppe 2.
 Finn aritmetisk gjennomsnitt, median, modus og standardavvik for gruppe 2.") Sensurveiledning Ped 3001 h12 Oppgave 1 Er det sammenheng mellom støtte fra venner og selvaktelse hos ungdom? Dette spørsmålet ønsket en forsker å undersøke. Han samlet data på 9. klassingers opplevde
Sensurveiledning Ped 3001 h12 Oppgave 1 Er det sammenheng mellom støtte fra venner og selvaktelse hos ungdom? Dette spørsmålet ønsket en forsker å undersøke. Han samlet data på 9. klassingers opplevde
Oppgave 1. Det oppgis at dersom y ij er observasjon nummer j fra laboratorium i så er SSA = (y ij ȳ i ) 2 = 3.6080.
 2 = 3.6080.") EKSAMEN I: MOT310 STATISTISKE METODER 1 VARIGHET: 4 TIMER DATO: 28. FEBRUAR 2005 TILLATTE HJELPEMIDLER: KALKULATOR, TABELLER OG FORMLER I STATISTIKK (TAPIR FORLAG) OPPGAVESETTET BESTÅR AV 4 OPPGAVER PÅ
EKSAMEN I: MOT310 STATISTISKE METODER 1 VARIGHET: 4 TIMER DATO: 28. FEBRUAR 2005 TILLATTE HJELPEMIDLER: KALKULATOR, TABELLER OG FORMLER I STATISTIKK (TAPIR FORLAG) OPPGAVESETTET BESTÅR AV 4 OPPGAVER PÅ
Eksamensoppgave i ST1201/ST6201 Statistiske metoder
 Institutt for matematiske fag Eksamensoppgave i ST1201/ST6201 Statistiske metoder Faglig kontakt under eksamen: Nikolai Ushakov Tlf: 45128897 Eksamensdato: 20. desember 2016 Eksamenstid (fra til): 09:00
Institutt for matematiske fag Eksamensoppgave i ST1201/ST6201 Statistiske metoder Faglig kontakt under eksamen: Nikolai Ushakov Tlf: 45128897 Eksamensdato: 20. desember 2016 Eksamenstid (fra til): 09:00
OPPGAVESETTET BESTÅR AV 3 OPPGAVER PÅ 6 SIDER MERKNADER: Alle deloppgaver vektlegges likt.
 EKSAMEN I: MOT310 STATISTISKE METODER 1 VARIGHET: 4 TIMER DATO: 08. mai 2008 TILLATTE HJELPEMIDLER: Kalkulator: HP30S, Casio FX82 eller TI-30 Tabeller og formler i statistikk (Tapir forlag) OPPGAVESETTET
EKSAMEN I: MOT310 STATISTISKE METODER 1 VARIGHET: 4 TIMER DATO: 08. mai 2008 TILLATTE HJELPEMIDLER: Kalkulator: HP30S, Casio FX82 eller TI-30 Tabeller og formler i statistikk (Tapir forlag) OPPGAVESETTET
ÅMA110 Sannsynlighetsregning med statistikk, våren 2006 Kp. 6, del 3
 ÅMA110 Sannsynlighetsregning med statistikk, våren 2006 Kp. 6, del 3 Bjørn H. Auestad Institutt for matematikk og naturvitenskap Universitetet i Stavanger 20. mars Bjørn H. Auestad Kp. 6: Hypotesetesting
ÅMA110 Sannsynlighetsregning med statistikk, våren 2006 Kp. 6, del 3 Bjørn H. Auestad Institutt for matematikk og naturvitenskap Universitetet i Stavanger 20. mars Bjørn H. Auestad Kp. 6: Hypotesetesting
Utvalgsfordelinger (Kapittel 5)
") Utvalgsfordelinger (Kapittel 5) Observator En observator er en funksjon av data for mange individer, for eksempel Gjennomsnitt Andel Stigningstall i regresjonslinje En observator er en tilfeldig variabel
Utvalgsfordelinger (Kapittel 5) Observator En observator er en funksjon av data for mange individer, for eksempel Gjennomsnitt Andel Stigningstall i regresjonslinje En observator er en tilfeldig variabel
EKSAMEN I FAG TMA4255 FORSØKSPLANLEGGING OG ANVENDTE STATISTISKE METODER
 Norges teknisk naturvitenskapelige universitet Institutt for matematiske fag Side 1 av 8 Faglig kontakt under eksamen: Bo Lindqvist Tlf. 975 89 418 EKSAMEN I FAG TMA4255 FORSØKSPLANLEGGING OG ANVENDTE
Norges teknisk naturvitenskapelige universitet Institutt for matematiske fag Side 1 av 8 Faglig kontakt under eksamen: Bo Lindqvist Tlf. 975 89 418 EKSAMEN I FAG TMA4255 FORSØKSPLANLEGGING OG ANVENDTE
ST0202 Statistikk for samfunnsvitere Kapittel 13: Lineær regresjon og korrelasjon
 ST0202 Statistikk for samfunnsvitere Kapittel 13: Lineær regresjon og korrelasjon Bo Lindqvist Institutt for matematiske fag http://wiki.math.ntnu.no/st0202/2012h/start 2 Kap. 13: Lineær korrelasjons-
ST0202 Statistikk for samfunnsvitere Kapittel 13: Lineær regresjon og korrelasjon Bo Lindqvist Institutt for matematiske fag http://wiki.math.ntnu.no/st0202/2012h/start 2 Kap. 13: Lineær korrelasjons-
Krysstabellanalyse (forts.) SOS1120 Kvantitativ metode. 4. Statistisk generalisering. Forelesningsnotater 9. forelesning høsten 2005.
 SOS1120 Kvantitativ metode. 4. Statistisk generalisering. Forelesningsnotater 9. forelesning høsten 2005.") SOS112 Kvantitativ metode Krysstabellanalyse (forts.) Forelesningsnotater 9. forelesning høsten 25 4. Statistisk generalisering Per Arne Tufte Eksempel: Hypoteser Eksempel: observerte frekvenser (O) Hvordan
SOS112 Kvantitativ metode Krysstabellanalyse (forts.) Forelesningsnotater 9. forelesning høsten 25 4. Statistisk generalisering Per Arne Tufte Eksempel: Hypoteser Eksempel: observerte frekvenser (O) Hvordan
Hypotesetesting. Formulere en hypotesetest: Når vi skal test om en parameter θ kan påstås å være større enn en verdi θ 0 skriver vi dette som:
 Hypotesetesting. 10 og fore- Dekkes av pensumsidene i kap. lesingsnotatene. Hypotesetesting er en systematisk fremgangsmåte for å undersøke hypoteser (påstander) knyttet til parametre i sannsynlighetsfordelinger.
Hypotesetesting. 10 og fore- Dekkes av pensumsidene i kap. lesingsnotatene. Hypotesetesting er en systematisk fremgangsmåte for å undersøke hypoteser (påstander) knyttet til parametre i sannsynlighetsfordelinger.