Kapittel 7: Inferens for forventningerukjent standardavvik
|
|
|
- Lene Thoresen
- 7 år siden
- Visninger:
Transkript
1 Kapittel 7: Inferens for forventningerukjent standardavvik 7.1: Inferens for forventningen i en populasjon 7.: Inferens for å sammenligne to forventninger
2 7.1 Inferens for forventningen i en populasjon t fordelingen Ett utvalgs t konfidensintervall Ett utvalgs t test Matchede par t prosedyrer Robusthet
3 Ødelegger lagring søtheten av Cola? En cola produsent ønsker å teste hvor mye søtheten til en ny cola drikk påvirkes av lagring. Søthets tapet som følge av lagring ble bedømt av 10 profesjonelle smakstestere (ved å sammenligne søtheten før og etter lagring): Smakstester Søthets tap Vi ønsker altså å teste om lagring medfører tap i søthet, altså: H0: m = 0 versus Ha: m > 0 der m er forventet tap av søthet Dette ser kjent ut. Men siden dette er en ny cola-oppskrift har vi ikke noe populasjonsdata fra tidligere, og vi kjenner ikke populasjonsparameteren s. Dette er en veldig vanlig situasjon for relle data.
4 Når s er ukjent Empirisk standardavvik s gir oss et estimat for populasjonens standardavvik s. Når utvalgsstørrelsen er stor, er det sannsynlig at utvalget representerer populasjonen godt. Da er s et godt estimat for s. Men hvis utvalgsstørrelsen er liten, er s et dårlig estimat for s. Populasjonsfordeling Stort utvalg Lite utvalg
5 Husk empirisk standardavvik 1 s ( x x ) i n 1 der n-1 kaltes antall frihetsgrader (degrees of freedom, df)
6 En populasjon Anta x1,...,xn uavhengige fra N(μ,σ) Statistikk: xx σ kjent: z=(xx-μ)/(σ/ n) σ/ n: standardavvik for statistikk xx s/ n: estimert standardavvik for statistikk xx Kalles standardfeil Standard Error, SE = s/ n
7 t fordeling z=(xx -μ)/(σ/ n) er N(0,1)-fordelt t=(xx -μ)/(s/ n) er t-fordelt med n-1 frihetsgrader x m Kalles ett-utvalgs t-statistikk t s n (eller ett-utvalgs t-observator) Form som normalfordeling Ekstra spredning/usikkerhet pga. ukjent σ Nærmer seg N(0,1) når n vokser
8
9
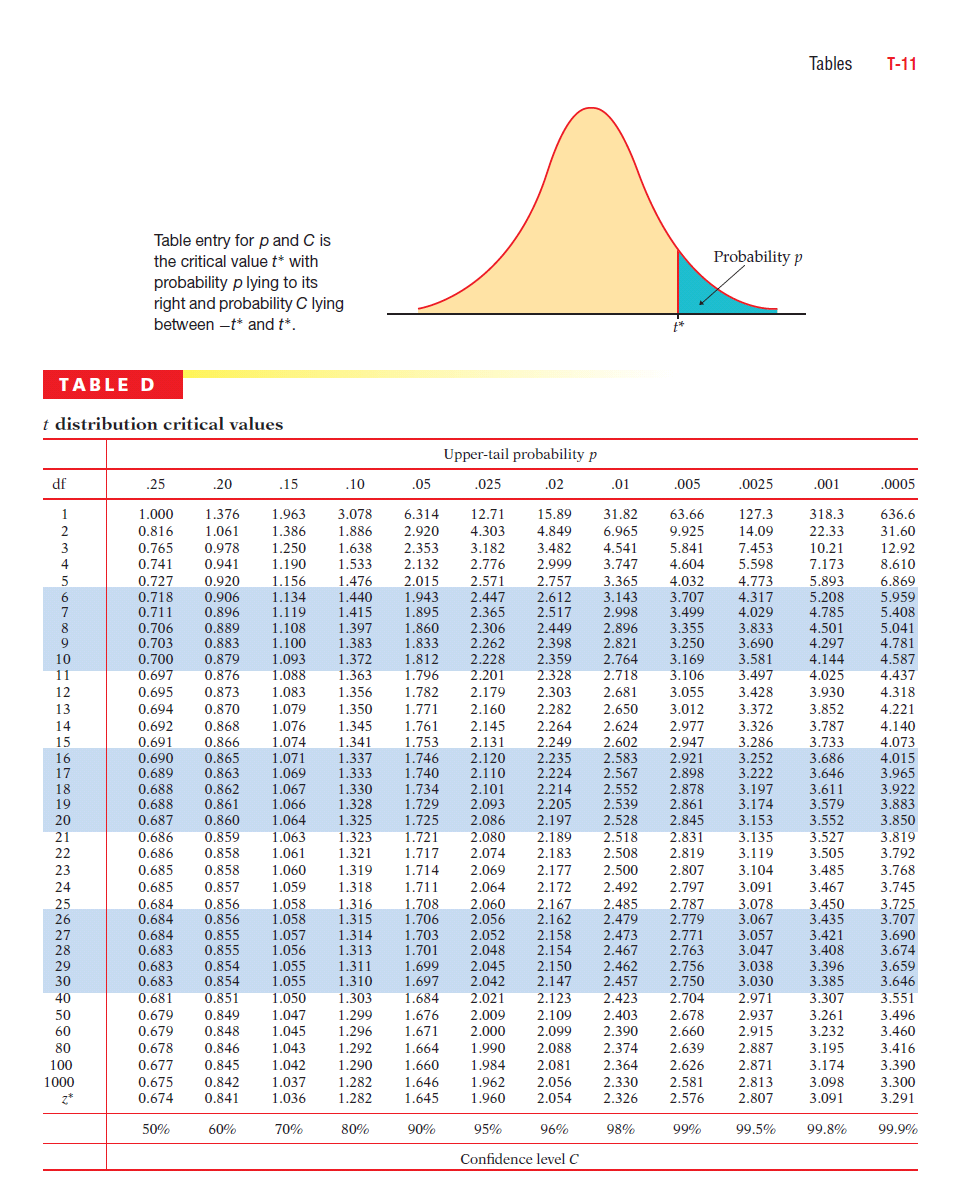
10 Ett utvalgs t konfidensintervall σ kjent: [xx -z*σ/ n,xx+z*σ/ n] z* er verdien slik at arealet mellom -z* og z* i N(0,1) fordelingen er C σ ukjent: [xx -t*s/ n,xx+t*s/ n] t* er verdien slik at arealet mellom -t* og t* i t(n-1) fordelingen er C

11 C m t* m t* Feilmarginen er m = t*s/ n Eksakt hvis normalfordelte data Tilnærmet riktig ellers

12 Når σ er ukjent, bruker vi t-fordeling med n 1 frihetsgrader (degrees of freedom df). x m t s n Tabell D viser z-verdier og t-verdier knyttet til typiske Pverdier/ konfidensnivåer Når σ er kjent, bruker vi normalfordeling og den standardiserte z-verdien.
13 Moderate mengder rødvin Å drikke rødvin i moderate mengder kan beskytte mot hjerteinfarkt. Polyphenolene i rødvinen virker på kolesterolet, noe som kanskje kan motvirke hjerteinfarkt. For å undersøke om moderat inntak av rødvin øker forventet nivå av polyphenoler i blodet skulle en gruppe på 9 tilfeldig valgte friske menn drikke en moderat mengde rødvin hver dag i uker. Nivået av polyphenoler i blodet ble målt både før og etter disse ukene, og den prosentvise endringen var som følger: Først: Er dataene tilnærmet normalfordelte? Normal quantiles Det er en lav verdi, men generelt ser det ut til at man kan anta at dataene kan antas å være tilnærmet normalfordelte.

14 Hva er 95% konfidensintervallet for forventet prosentvis økning av nivå av polyphenoler i blodet? Utvalgs-gjennomsnitt = 5.5; s =.517; df = n 1 = 8 Utvalgsfordelingen er en t-fordeling med n 1 frihetsgrader. For df = 8 og C = 95%: t* =.306. Feilmarginen m er: m = t*s/ n =.306*.517/ Med 95% sikkerhet kan vi si at forventet prosentvis økning av nivå av polyphenoler i blodet for friske menn som drikker en moderat mengde rødvin hver dag er mellom 3.6% og 7.4%. Viktig: Konfidensintervallet viser hvor stor endringen av nivået av ployphenoler I blodet er, men ikke om det har en innvirkning på menns helse!
15 Ett-utvalgs t-test Fremgangsmåten for å teste en hypotese er som tidligere: 1. Formuler null- og alternativ-hypoteser (H0 versus Ha). Velg signifikansnivå a 3. Beregn t-observator og antall frihetsgrader (beregnet ved å anta at parameterverdien gitt av H0 er sann) 4. Finn ønsket sannsynlighet fra Tabell D (sannsynligheten for at et utfall er like ekstremt eller mer ekstremt enn faktisk utfall) 5. Oppgi P-verdi og formuler en konklusjon
16
17 Søthet av cola (fortsettelse) Er det bevis for at lagring medfører søthets tap for den nye cola oppskriften på et 0.05 signifikansnivå (a = 5%)? H0: m = 0 versus Ha: m > 0 (ensidig test) t x m s n Antall frihetsgrader: df=10 1=9 Taster Sweetness loss Average 1.0 Standard deviation Degrees of freedom n 1 = 9
; for en to-sidig Ha, hadde P-verdien vært det dobbelte (mellom 0.")
18 For df = 9 ser vi bare på denne linjen i tabellen Den beregnede verdi av t er.7. Vi finner de to nærmeste t-verdiene:.398 < t =.7 <.81 så 0.0 > øvre hale p > 0.01 For en en-sidig Ha, er dette P-verdien (mellom 0.01 og 0.0); for en to-sidig Ha, hadde P-verdien vært det dobbelte (mellom 0.0 og 0.04).
19 Søthet av cola (fortsettelse) Er det bevis for at lagring medfører søthets tap for den nye cola oppskriften på et 0.05 signifikansnivå (a = 5%)? H0: m = 0 versus Ha: m > 0 (ensidig test) t x m s n < t =.70 <.81, altså er 0.0 > p > p < a, altså er resultatet signifikant. Taster Sweetness loss Average 1.0 Standard deviation Degrees of freedom n 1 = 9 t testen har en signifikant p verdi. Vi forkaster H0. Det er et signifikant forventet tap av søthet som følge av lagring.

20 Søthet av cola (fortsettelse) Minitab x m s n df n 1 9 t
21 Parrede (matchede) t prosedyrer Noen ganger vil vi sammenligne behandlinger på de samme individene. Dette gir oss observasjoner som ikke er uavhengige de er parret eller matchede to og to: Eks. Før og etter behandling (blodtrykk før og etter behandling med betablokker, søtsmak før og etter lagring) Eks. Tvillingstudier, begrenser effekten av genetiske forskjeller ved å se på en variabel i sett av tvillinger Eks. Ved å bruke folk som matcher hverandre i alder, kjønn, utdanning i sosiale studier, kan man kansellere ut effekten av slike underliggende lurevariable
22 I slike situasjoner kan vi bruke par data til å teste forskjell i forventning mellom de to fordelingene. Vi studerer variabelen Xdiff = (X1 X), og tester H0: µdiff = 0 ; Ha: µdiff > 0 (eller <0, eller 0) Dette er det samme som å teste i en ett utvalgs situasjon. Data for individ nr i er da xdiff = x1i xi
23 Søthet av cola (om igjen) Søthets tapet pga lagring ble bedømt av 10 profesjonelle smakstestere (som sammenlignet søtheten før og etter): Smakstester Søthets tap Vi ønsker å teste om lagring medfører tap I søthet, atltså: H0: m = 0 versus Ha: m > 0 Selv om teksten ikke sa det eksplisitt, er dette et pre-/post-test design og variabelen er differensen i søthet av cola før (X1) minus etter lagring (X). En parret signifikanstest er altså akkurat det samme som en ett-utvalgs signifikanstest.

24 Gir koffeinavholdenhet økt depresjon? 11 individer som er diagnostisert som koffeinavhengige blir forhindret fra å innta koffein-holdig mat og drikke og får i stedet daglige piller. Noen ganger inneholder disse pillene koffein og noen ganger inneholder de en placebo. Forskjellen i depresjonsnivå når individene får koffein kontra når de får Depression Depression Placebo Subject with Caffeine with Placebo Cafeine placebo ble evaluert. Det er datapunkter for hvert individ, men vi ser bare på differansen i depresjonsnivå (x=xi x1i) Utvalgsfordelingen ser ut til å være passende for en t test difference data points Normal quantiles
25 Gir koffeinavholdenhet økt depresjon? For hvert individ i utvalget har vi beregnet forskjellen i depresjonsnivå (placebo minus koffein). Det var 11 differanse verdier, altså er df = n 1 = 10. Vi beregner at x = 7.36; s = 6.9 H0: m diff = 0 ; H0: mdiff > 0 x t 3.53 s n 6.9 / 11 Depression Depression Placebo Subject with Caffeine with Placebo Cafeine For df = 10: < t = 3.53 < > p > Koffeinavholdenhet gir en signifikant økning av depresjon.
26 Robusthet t prosedyrene er eksakt riktige når populasjonen er eksakt normalfordelt. I praksis vil vi ikke alltid ha eksakt normalfordeling, men t prosedyrene er robuste i forhold til mindre avvik fra normalitet resultatene blir ikke så gale selv om normalitetsantakelsen ikke holder. Viktige faktorer er: Tilfeldig utvalg. Utvalget må være et SRS fra populasjonen. Uteliggere og skjevhet. Påvirker gjennomsnittet og derfor også t prosedyrene. MEN, betydningen av dette avtar med økende antall observasjoner på grunn av sentralgrenseteoremet (CLT).
27 Spesielt: Når n < 15, må data være tilnærmet normalfordelte og uten uteliggere Når 15 > n > 40, er det ok med noe skjevhet, men ikke uteliggere Når n > 40, er t-observatoren ok selv med sterk skjevhet i underliggende fordeling
28
29 7. Sammenligning av to forventinger To utvalgs z statistikk To utvalgs t prosedyrer To utvalgs t tester To utvalgs t konfidensintervall Robusthet To utvalgs t prosedyrer når variansene er like
30 Sammenlikning av to forventninger Effekt av økt kalsium på blodtrykk En gruppe får økt kalsium i diett Kontrollgruppe får placebo Bank: To kampanjer for å øke bruk av kredittkort Et tilfeldig utvalg eksponert for kampanje 1 Et annet tilfeldig utvalg eksponert for kamp.
31 Sammenligning av to utvalg (A) Populasjon 1 Populasjon Utvalg Utvalg 1 Hvilken situasjon har vi? (B) Populasjon Vi sammenligner ofte to behandlinger på to uavhengige utvalg. Utvalg Utvalg 1 Er forskjellene vi observerer et resultat av variasjon i utvalgene (B), eller er det en ekte forskjell, dvs. at utvalgene kommer fra to forskjellige populasjoner (A)?
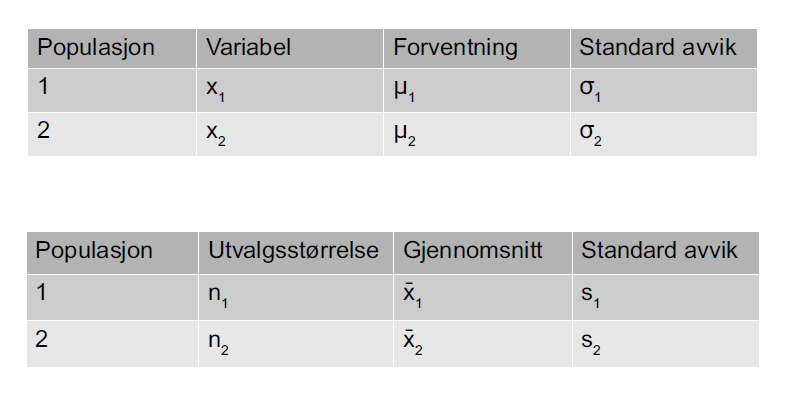
32 Notasjon
33 Statistikk for to utvalg med kjente standardavvik Men veldig uvanlig at man kjenner standardavvikene!
34 To utvalg ukjente varianser I praksis: σ1 og σ ukjente Estimeres ved s1 og s, får da x 1 x (μ 1 μ ) Statistikk t = s1 s + n1 n Ikke t-fordelt! En t-fordeling erstatter en N(0,1)-fordeling bare når et enkelt standardavvik σ i en z-statistikk erstattes med ett empirisk standardavvik s Men: Tilnærmet t(k)-fordelt med passende antall frihetsgrader k To måter å estimere k på: En metode som beregnes fra data (med dataprogram), eller den minste verdien av (n1-1) og (n-1)
35 To utvalgs t konfidensintervall Når vi har to tilfeldige, uavhengige utvalg av størrelser n og n fra to normalfordelte 1 populasjoner med ukjente forventninger m og m, har følgende konfidensintervall 1 for ( m m ) 1 s s ( x x ) t * 1 1 n n 1 minst konfidensnivå C. Her er t* verdien slik at arealet mellom -t* og t* i t( k )-fordelingen er C. Antall frihetsgrader k beregnes av et dataprogram eller vi bruker den minste verdien av n 1 and n 1. 1
36 Eks. ny læringsmetode for lesing 1 elever prøver ny metode 3 elever følger dagens metode
")
37 Ny læringsmetode: (Normale) Kvantilplott
38 Ny læringsmetode for lesing 1 elever prøver ny metode 3 elever følger dagens metode Frihetsgrader: Minste av n1 1=0 og n 1= s s ( x x ) t * t * t * 1 n n Konservativt valg: t(0) fordeling: t*= % KI: [0.97,18.95] Minitab: t(37) fordeling: t*=.06, 95% KI: [1.3,18.69]
39
40 To utvalgs t tester For å teste H0: μ1=μ mot Ha:μ1>μ(Ha:μ1-μ>0) P verdi = P(T t) For å teste H0: μ1=μ mot Ha:μ1<μ(Ha:μ1-μ<0) P verdi = P(T t) For å teste H0: μ1=μ mot Ha:μ1 μ(ha:μ1-μ 0) P verdi = P(T t ), der T er t fordelt med k frihetsgrader
41 Ødelegger røyking hos foreldrene lungene til barna deres? Forsert vital kapasitet (FVC) er volumet (i milliliter) av luft som en person kan puste ut etter maksimal innpust. FVC ble målt for et utvalg av barn som ikke hadde vært utsatt for røyking hos foreldrene og et utvalg av barn som hadde vært utsatt for røyking hos foreldrene. Foreldrene røyker FVC Ja Nei x s n Vi ønsker å finne ut om røyking hos foreldrene senker barns lungekapasitet målt av FVC-testen. Er forventet FVC lavere i populasjonen av barn som har vært utsatt for røyking hos foreldrene?
42 H0: mrøyk = mikke-røyk <=> (mrøyk mikk-røyk) = 0 Ha: mrøyk < mikke-røyk <=> (mrøyk mikke-røyk) < 0 (en-sidig) Forskjellen I utvalgs-gjennomsnittene følger tilnærmet en t-fordeling: t 0, ssmoke sno n smoke n no, df 9 Vi beregner t-observatoren: t xrøyk xikke røyk s røyk nrøyk ikke røyk s nikke røyk 1.7 t Røyking hos foreldrene FVC Ja Nei x s n I tabell D, for antall frihetsgrader=9, finner vi: t > => p < (en-sidig) Det er en veldig signifikant forskjell, og vi forkaster H0 (p< ). Lungekapasiteten blir signifikant svekket hos barn av røykende foreldre.
43 Ny læringsmetode for lesing 1 elever prøver ny metode 3 elever følger dagens metode H0: μ1=μ mot Ha:μ1>μ
44 Egenskaper to utvalgs t test Mer robust enn ett utvalgs t test Svært presise når n1 nog formene på fordelingene er ganske like Større utvalg trengs når ulike former på fordelinger Velg så like utvalgsstørrelser som mulig!
45 Lik varians: Pooled t metoder to utvalg Hittil har vi benyttet oss av at to utvalgs t statistikk er tilnærmet t fordelt når vi bruker de estimerte standardavvikene s1 og s Dersom de to underliggende normale populasjons fordelingene har samme standardavvik σ (dvs σ1=σ=σ), og vi erstatter den N(0,1) fordelte z statistikken med en t statistikk ved å bytte ut σ med et samlet estimat på σ, da er t statistikken eksakt t fordelt (Erstatter da bare ett enkelt standardavvik i en z statistikk med ett estimert standardavvik)
46 Statistikk for to utvalg Dersom σ1=σ=σ og σ er ukjent, erstatter vi bare ett enkelt standardavvik σ i en z observator med ett estimert standardavvik, da er t observatoren eksakt t fordelt
47 t metoder for samlede («pooled») to utvalg Begge de empiriske variansene s1 og s estimerer σ Den beste måten å utnytte begge disse til å estimere σ, er å ta et gjennomsnitt vektet med de respektive frihetsgradene n1 og n Det samlede estimatet av σ er da t statistikken er da eksakt t fordelt med frihetsgrader n1+ n
48 t metoder for samlede («pooled») to utvalg
49 Eksempel: Kalsium og blodtrykk Gir økt inntak av kalsium redusert blodtrykk? NB: Nedgang (decrease) er positiv når det er en reduksjon, negative ved oppgang

50 Eksempel: Kalsium og blodtrykk Kvantilplott: Ser ut til å passe ganske bra med normalfordeling for begge grupper Kalsium gruppen har en litt kort venstre hale Må gjøre en signifikanstest for å besvare spørsmålet: gir økt inntak av kalsium redusert blodtrykk?
51 Eksempel: Kalsium og blodtrykk Gruppe 1 med forventning μ1 fikk kalsium tilskudd, gruppe med forventning μ fikk placebo Naturlig med ensidig null hypotese, for forsøk med rotter hadde vist at kalsium ga en nedgang, ingen grunn til å ro at det skulle øke blodtrykket. Hypoteser: H0: μ1= μ, Ha: μ1 > μ Numeriske beskrivelser av data De empiriske standardavvikene utelukker ikke like populasjons standardavvik, forskjell i estimatene kan lett være pga. tilfeldigheter Vi vil anta like populasjons standardavvik
52 Eksempel: Kalsium og blodtrykk Den samlede empiriske variansen er som gir sp = Den samlede to utvalgs t statistikken er P verdi=p(t 1.634) der T er t(19) fordelt (10+11 =19) Tabell D sier oss at P verdien er mellom 0.05 og Analyse i Minitab gir P verdi=0.059 Konklusjon: Forsøket fant bevis for at kalsium muligens reduserer blodtrykket, men resultatet er ikke på 5% (eller 1% )nivå
53 Antagelsen om like populasjons standardavvik Vanskelig å verifisere Derfor kan t metodene for samlede («pooled») to utvalg noen ganger være risikable å bruke Ganske robuste mot både ikke-normalitet og ulike populasjons-standardavvik når utvalgsstørrelsene n1 og n er ganske like Når utvalgsstørrelsene n1 og n er veldig forskjellige, er metodene sensitive for ulike populasjonsstandardavvik, og man skal være forsiktige med å bruke dem med mindre utvalgsstørrelsene er store
Kapittel 7: Inferens for forventningerukjent standardavvik
 Kapittel 7: Inferens for forventningerukjent standardavvik 7.1: Inferens for forventningen i en populasjon 7.2: Inferens for å sammenligne to forventninger 7.1 Inferens for forventningen i en populasjon
Kapittel 7: Inferens for forventningerukjent standardavvik 7.1: Inferens for forventningen i en populasjon 7.2: Inferens for å sammenligne to forventninger 7.1 Inferens for forventningen i en populasjon
7.2 Sammenligning av to forventinger
 7.2 Sammenligning av to forventinger To-utvalgs z-observator To-utvalgs t-prosedyrer To-utvalgs t-tester To-utvalgs t-konfidensintervall Robusthet To-utvalgs t-prosedyrerår variansene er like Sammenlikning
7.2 Sammenligning av to forventinger To-utvalgs z-observator To-utvalgs t-prosedyrer To-utvalgs t-tester To-utvalgs t-konfidensintervall Robusthet To-utvalgs t-prosedyrerår variansene er like Sammenlikning
Simulering med Applet fra boken, av z og t basert på en rekke utvalg av en gitt størrelse n fra N(μ,σ). Illustrerer hvordan estimering av variansen
. Illustrerer hvordan estimering av variansen") Simulering med Applet fra boken, av z og t basert på en rekke utvalg av en gitt størrelse n fra N(μ,σ). Illustrerer hvordan estimering av variansen gir testobservatoren t mer spredning enn testobservatoren
Simulering med Applet fra boken, av z og t basert på en rekke utvalg av en gitt størrelse n fra N(μ,σ). Illustrerer hvordan estimering av variansen gir testobservatoren t mer spredning enn testobservatoren
Inference for Distributions
 Inference for Distributions IPS Chapter 7 7.1: Inference for the Mean of a Population 7.2: Comparing Two Means 7.3: Optional Topics in Comparing Distributions 2012 W.H. Freeman and Company 7.1 Inferens
Inference for Distributions IPS Chapter 7 7.1: Inference for the Mean of a Population 7.2: Comparing Two Means 7.3: Optional Topics in Comparing Distributions 2012 W.H. Freeman and Company 7.1 Inferens
Inferens i fordelinger
 Inferens i fordelinger Modifiserer antagelsen om at standardavviket i populasjonen σ er kjent Mer kompleks systematisk del ( her forventningen i populasjonen). Skal se på en situasjon der populasjonsfordelingen
Inferens i fordelinger Modifiserer antagelsen om at standardavviket i populasjonen σ er kjent Mer kompleks systematisk del ( her forventningen i populasjonen). Skal se på en situasjon der populasjonsfordelingen
Denne uken: kap. 6.1-6.2-6.3: Introduksjon til statistisk inferens. - Konfidensintervall - Hypotesetesting - P-verdier - Statistisk signifikans
 Denne uken: kap. 6.1-6.2-6.3: Introduksjon til statistisk inferens - Konfidensintervall - Hypotesetesting - P-verdier - Statistisk signifikans VG 25/9 2011 Statistisk inferens Mål: Trekke konklusjoner
Denne uken: kap. 6.1-6.2-6.3: Introduksjon til statistisk inferens - Konfidensintervall - Hypotesetesting - P-verdier - Statistisk signifikans VG 25/9 2011 Statistisk inferens Mål: Trekke konklusjoner
Denne uken: kap : Introduksjon til statistisk inferens. - Konfidensintervall - Hypotesetesting - P-verdier - Statistisk signifikans
 Denne uken: kap. 6.1-6.2-6.3: Introduksjon til statistisk inferens - Konfidensintervall - Hypotesetesting - P-verdier - Statistisk signifikans VG 25/9 2011 Statistisk inferens Mål: Trekke konklusjoner
Denne uken: kap. 6.1-6.2-6.3: Introduksjon til statistisk inferens - Konfidensintervall - Hypotesetesting - P-verdier - Statistisk signifikans VG 25/9 2011 Statistisk inferens Mål: Trekke konklusjoner
Denne uken: kap : Introduksjon til statistisk inferens. - Konfidensintervall - Hypotesetesting - P-verdier - Statistisk signifikans
 Denne uken: kap. 6.1-6.2-6.3: Introduksjon til statistisk inferens - Konfidensintervall - Hypotesetesting - P-verdier - Statistisk signifikans VG 25/9 2011 Statistisk inferens Mål: Trekke konklusjoner
Denne uken: kap. 6.1-6.2-6.3: Introduksjon til statistisk inferens - Konfidensintervall - Hypotesetesting - P-verdier - Statistisk signifikans VG 25/9 2011 Statistisk inferens Mål: Trekke konklusjoner
I dag. Konfidensintervall og hypotesetes4ng ukjent standardavvik (kap. 7.1) t-fordelingen
 t-fordelingen") I dag Konfidensintervall og hypotesetes4ng ukjent standardavvik (kap. 7.1) t-fordelingen Inferens for forventningen 4l en populasjon (7.1) Kapi@el 6: En antagelse om kjent standardavvik s i populasjonen
I dag Konfidensintervall og hypotesetes4ng ukjent standardavvik (kap. 7.1) t-fordelingen Inferens for forventningen 4l en populasjon (7.1) Kapi@el 6: En antagelse om kjent standardavvik s i populasjonen
6.2 Signifikanstester
 6.2 Signifikanstester Konfidensintervaller er nyttige når vi ønsker å estimere en populasjonsparameter Signifikanstester er nyttige dersom vi ønsker å teste en hypotese om en parameter i en populasjon
6.2 Signifikanstester Konfidensintervaller er nyttige når vi ønsker å estimere en populasjonsparameter Signifikanstester er nyttige dersom vi ønsker å teste en hypotese om en parameter i en populasjon
Verdens statistikk-dag.
 Verdens statistikk-dag http://unstats.un.org/unsd/wsd/ Signifikanstester Ønsker å teste hypotese om populasjon Bruker data til å teste hypotese Typisk prosedyre Beregn sannsynlighet for utfall av observator
Verdens statistikk-dag http://unstats.un.org/unsd/wsd/ Signifikanstester Ønsker å teste hypotese om populasjon Bruker data til å teste hypotese Typisk prosedyre Beregn sannsynlighet for utfall av observator
Introduksjon til inferens
 Introduksjon til inferens Hittil: Populasjon der verdien til et individ/enhet beskrives med en fordeling. Her inngår vanligvis ukjente parametre, μ, p,... Enkelt tilfeldig utvalg (SRS), observator p =
Introduksjon til inferens Hittil: Populasjon der verdien til et individ/enhet beskrives med en fordeling. Her inngår vanligvis ukjente parametre, μ, p,... Enkelt tilfeldig utvalg (SRS), observator p =
ST0202 Statistikk for samfunnsvitere
 ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Kap. 10: Inferens om to populasjoner Situasjon: Vi ønsker å sammenligne to populasjoner med populasjonsgjennomsnitt henholdsvis
ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Kap. 10: Inferens om to populasjoner Situasjon: Vi ønsker å sammenligne to populasjoner med populasjonsgjennomsnitt henholdsvis
ST0202 Statistikk for samfunnsvitere
 ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Kap. 10: Inferens om to populasjoner Situasjon: Det er to populasjoner som vi ønsker å sammenligne. Vi trekker da et utvalg
ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Kap. 10: Inferens om to populasjoner Situasjon: Det er to populasjoner som vi ønsker å sammenligne. Vi trekker da et utvalg
Verdens statistikk-dag. Signifikanstester. Eksempel studentlån. http://unstats.un.org/unsd/wsd/
 Verdens statistikk-dag http://unstats.un.org/unsd/wsd/ Signifikanstester Ønsker å teste hypotese om populasjon Bruker data til å teste hypotese Typisk prosedyre Beregn sannsynlighet for utfall av observator
Verdens statistikk-dag http://unstats.un.org/unsd/wsd/ Signifikanstester Ønsker å teste hypotese om populasjon Bruker data til å teste hypotese Typisk prosedyre Beregn sannsynlighet for utfall av observator
Kap. 10: Inferens om to populasjoner. Eksempel. ST0202 Statistikk for samfunnsvitere
 Kap. 10: Inferens om to populasjoner Situasjon: Vi ønsker å sammenligne to populasjoner med populasjonsgjennomsnitt henholdsvis μ 1 og μ. Vi trekker da ett utvalg fra hver populasjon. ST00 Statistikk for
Kap. 10: Inferens om to populasjoner Situasjon: Vi ønsker å sammenligne to populasjoner med populasjonsgjennomsnitt henholdsvis μ 1 og μ. Vi trekker da ett utvalg fra hver populasjon. ST00 Statistikk for
Statistisk inferens (kap. 8) Hovedtyper av statistisk inferens. ST0202 Statistikk for samfunnsvitere
 Hovedtyper av statistisk inferens. ST0202 Statistikk for samfunnsvitere") 2 Statistisk inferens (kap. 8) Statistisk inferens er å tolke/analysere resultater fra utvalget for å finne ut mest mulig om populasjonen. Konkret: Å analysere en utvalgsobservator for å trekke slutninger
2 Statistisk inferens (kap. 8) Statistisk inferens er å tolke/analysere resultater fra utvalget for å finne ut mest mulig om populasjonen. Konkret: Å analysere en utvalgsobservator for å trekke slutninger
ST0202 Statistikk for samfunnsvitere
 ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Statistisk inferens (kap. 8) Statistisk inferens er å tolke/analysere resultater fra utvalget for å finne ut mest mulig
ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Statistisk inferens (kap. 8) Statistisk inferens er å tolke/analysere resultater fra utvalget for å finne ut mest mulig
ST0202 Statistikk for samfunnsvitere
 ST0202 Statistikk for samfunnsvitere Kapittel 7: Utvalgsfordeling Bo Lindqvist Institutt for matematiske fag 2 Fra kapittel 1: Populasjon Den mengden av individer/objekter som vi ønsker å analysere. Utvalg
ST0202 Statistikk for samfunnsvitere Kapittel 7: Utvalgsfordeling Bo Lindqvist Institutt for matematiske fag 2 Fra kapittel 1: Populasjon Den mengden av individer/objekter som vi ønsker å analysere. Utvalg
Statistisk inferens (kap. 8) Hovedtyper av statistisk inferens. ST0202 Statistikk for samfunnsvitere
 Hovedtyper av statistisk inferens. ST0202 Statistikk for samfunnsvitere") 2 Statistisk inferens (kap. 8) Statistisk inferens er å tolke/analysere resultater fra utvalget for å finne ut mest mulig om populasjonen. Konkret: Analysere en observator for å finne ut noe om korresponderende
2 Statistisk inferens (kap. 8) Statistisk inferens er å tolke/analysere resultater fra utvalget for å finne ut mest mulig om populasjonen. Konkret: Analysere en observator for å finne ut noe om korresponderende
ST0202 Statistikk for samfunnsvitere
 ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Fra første forelesning: Populasjon Den mengden av individer/objekter som vi ønsker å analysere. Utvalg En delmengde av
ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Fra første forelesning: Populasjon Den mengden av individer/objekter som vi ønsker å analysere. Utvalg En delmengde av
ST0202 Statistikk for samfunnsvitere
 ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Inferens om varians og standardavvik for ett normalfordelt utvalg (9.4) Inferens om variansen til en normalfordelt populasjon
ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Inferens om varians og standardavvik for ett normalfordelt utvalg (9.4) Inferens om variansen til en normalfordelt populasjon
Fra første forelesning:
 2 Fra første forelesning: ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag opulasjon Den mengden av individer/objekter som vi ønsker å analysere. Utvalg En delmengde av populasjonen
2 Fra første forelesning: ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag opulasjon Den mengden av individer/objekter som vi ønsker å analysere. Utvalg En delmengde av populasjonen
ST0202 Statistikk for samfunnsvitere
 ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Statistisk inferens (kap. 8) Statistisk inferens er å tolke/analysere resultater fra utvalget for å finne ut mest mulig
ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Statistisk inferens (kap. 8) Statistisk inferens er å tolke/analysere resultater fra utvalget for å finne ut mest mulig
ST0202 Statistikk for samfunnsvitere Kapittel 9: Inferens om én populasjon
 ST0202 Statistikk for samfunnsvitere Kapittel 9: Inferens om én populasjon Bo Lindqvist Institutt for matematiske fag 2 Kap. 9: Inferens om én populasjon Statistisk inferens har som mål å tolke/analysere
ST0202 Statistikk for samfunnsvitere Kapittel 9: Inferens om én populasjon Bo Lindqvist Institutt for matematiske fag 2 Kap. 9: Inferens om én populasjon Statistisk inferens har som mål å tolke/analysere
Utvalgsfordelinger (Kapittel 5)
") Utvalgsfordelinger (Kapittel 5) Oversikt pensum, fortid og fremtid Eksplorativ data-analyse (Kap 1, 2) Hvordan produsere data (Kap 3) Sannsynlighetsteori (Kap 4) Utvalgsfordelinger til observatorer (Kap
Utvalgsfordelinger (Kapittel 5) Oversikt pensum, fortid og fremtid Eksplorativ data-analyse (Kap 1, 2) Hvordan produsere data (Kap 3) Sannsynlighetsteori (Kap 4) Utvalgsfordelinger til observatorer (Kap
Kapittel 3: Studieopplegg
 Oversikt over pensum Kapittel 1: Empirisk fordeling for en variabel o Begrepet fordeling o Mål for senter (gj.snitt, median) + persentiler/kvartiler o Mål for spredning (Standardavvik s, IQR) o Outliere
Oversikt over pensum Kapittel 1: Empirisk fordeling for en variabel o Begrepet fordeling o Mål for senter (gj.snitt, median) + persentiler/kvartiler o Mål for spredning (Standardavvik s, IQR) o Outliere
Notasjon og Tabell 8. ST0202 Statistikk for samfunnsvitere
 2 Inferens om varians og standardavvik for ett normalfordelt utvalg (9.4) Inferens om variansen til en normalfordelt populasjon bruker kjikvadrat-fordelingen ( chi-square distribution ) (der kji er den
2 Inferens om varians og standardavvik for ett normalfordelt utvalg (9.4) Inferens om variansen til en normalfordelt populasjon bruker kjikvadrat-fordelingen ( chi-square distribution ) (der kji er den
Supplement til power-point presentasjonen i medisinsk statistikk, forelesning 7 januar 2013. Skrevet av Stian Lydersen 16 januar 2013
 1 Supplement til power-point presentasjonen i medisinsk statistikk, forelesning 7 januar 013. Skrevet av Stian Lydersen 16 januar 013 Vi antar at vårt utvalg er et tilfeldig og representativt utvalg for
1 Supplement til power-point presentasjonen i medisinsk statistikk, forelesning 7 januar 013. Skrevet av Stian Lydersen 16 januar 013 Vi antar at vårt utvalg er et tilfeldig og representativt utvalg for
ST0103 Brukerkurs i statistikk Forelesning 26, 18. november 2016 Kapittel 8: Sammenligning av grupper
 ST0103 Brukerkurs i statistikk Forelesning 26, 18. november 2016 Kapittel 8: Sammenligning av grupper Bo Lindqvist Institutt for matematiske fag 2 Kapittel 8: Sammenligning av grupper Situasjon: Vi ønsker
ST0103 Brukerkurs i statistikk Forelesning 26, 18. november 2016 Kapittel 8: Sammenligning av grupper Bo Lindqvist Institutt for matematiske fag 2 Kapittel 8: Sammenligning av grupper Situasjon: Vi ønsker
ST0202 Statistikk for samfunnsvitere
 ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Kap. 9: Inferens om én populasjon I Kapittel 8 brukte vi observatoren z = x µ σ/ n for å trekke konklusjoner om µ. Dette
ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Kap. 9: Inferens om én populasjon I Kapittel 8 brukte vi observatoren z = x µ σ/ n for å trekke konklusjoner om µ. Dette
Inferens i regresjon
 Strategi som er fulgt hittil: Inferens i regresjon Deskriptiv analyse og dataanalyse først. Analyse av en variabel før studie av samvariasjon. Emne for dette kapittel er inferens når det er en respons
Strategi som er fulgt hittil: Inferens i regresjon Deskriptiv analyse og dataanalyse først. Analyse av en variabel før studie av samvariasjon. Emne for dette kapittel er inferens når det er en respons
Utvalgsfordelinger (Kapittel 5)
") Utvalgsfordelinger (Kapittel 5) Observator En observator er en funksjon av data for mange individer, for eksempel Gjennomsnitt Andel Stigningstall i regresjonslinje En observator er en tilfeldig variabel
Utvalgsfordelinger (Kapittel 5) Observator En observator er en funksjon av data for mange individer, for eksempel Gjennomsnitt Andel Stigningstall i regresjonslinje En observator er en tilfeldig variabel
Hypotesetesting. Hvorfor og hvordan? Gardermoen 21. april 2016 Ørnulf Borgan. H. Aschehoug & Co Sehesteds gate 3, 0102 Oslo Tlf:
 Hypotesetesting Hvorfor og hvordan? Gardermoen 21. april 2016 Ørnulf Borgan H. Aschehoug & Co Sehesteds gate 3, 0102 Oslo Tlf: 22 400 400 www.aschehoug.no 1 Oversikt Sannsynlighetsregning og statistikk
Hypotesetesting Hvorfor og hvordan? Gardermoen 21. april 2016 Ørnulf Borgan H. Aschehoug & Co Sehesteds gate 3, 0102 Oslo Tlf: 22 400 400 www.aschehoug.no 1 Oversikt Sannsynlighetsregning og statistikk
Analyse av kontinuerlige data. Intro til hypotesetesting. 21. april 2005. Seksjon for medisinsk statistikk, UIO. Tron Anders Moger
 Intro til hypotesetesting Analyse av kontinuerlige data 21. april 2005 Tron Anders Moger Seksjon for medisinsk statistikk, UIO 1 Repetisjon fra i går: Normalfordelingen Variasjon i målinger kan ofte beskrives
Intro til hypotesetesting Analyse av kontinuerlige data 21. april 2005 Tron Anders Moger Seksjon for medisinsk statistikk, UIO 1 Repetisjon fra i går: Normalfordelingen Variasjon i målinger kan ofte beskrives
TMA4240 Statistikk H2010
 TMA4240 Statistikk H2010 Statistisk inferens: 9.6: Prediksjonsintervall 9.8: To utvalg, differanse µ 1 µ 2 Mette Langaas Foreleses mandag 18.oktober, 2010 2 Prediksjonsintervall for fremtidig observasjon,
TMA4240 Statistikk H2010 Statistisk inferens: 9.6: Prediksjonsintervall 9.8: To utvalg, differanse µ 1 µ 2 Mette Langaas Foreleses mandag 18.oktober, 2010 2 Prediksjonsintervall for fremtidig observasjon,
ST0202 Statistikk for samfunnsvitere Kapittel 10: Inferens om to populasjoner
 ST0202 Statistikk for samfunnsvitere Kapittel 10: Inferens om to populasjoner Bo Lindqvist Institutt for matematiske fag 2 Kapittel 10: Inferens om to populasjoner Situasjon: Vi ønsker å sammenligne to
ST0202 Statistikk for samfunnsvitere Kapittel 10: Inferens om to populasjoner Bo Lindqvist Institutt for matematiske fag 2 Kapittel 10: Inferens om to populasjoner Situasjon: Vi ønsker å sammenligne to
Gruppe 1 Gruppe 2 Gruppe a) Finn aritmetisk gjennomsnitt, median, modus og standardavvik for gruppe 2.
 Finn aritmetisk gjennomsnitt, median, modus og standardavvik for gruppe 2.") Sensurveiledning Ped 3001 h12 Oppgave 1 Er det sammenheng mellom støtte fra venner og selvaktelse hos ungdom? Dette spørsmålet ønsket en forsker å undersøke. Han samlet data på 9. klassingers opplevde
Sensurveiledning Ped 3001 h12 Oppgave 1 Er det sammenheng mellom støtte fra venner og selvaktelse hos ungdom? Dette spørsmålet ønsket en forsker å undersøke. Han samlet data på 9. klassingers opplevde
OPPGAVEHEFTE I STK1000 TIL KAPITTEL Regneoppgaver til kapittel 7. X 1,i, X 2 = 1 n 2. D = X 1 X 2. På onsdagsforelesningen påstod jeg at da må
 OPPGAVEHEFTE I STK000 TIL KAPITTEL 7 Regneoppgaver til kapittel 7 Oppgave Anta at man har resultatet av et randomisert forsøk med to grupper, og observerer fra gruppe, mens man observerer X,, X,2,, X,n
OPPGAVEHEFTE I STK000 TIL KAPITTEL 7 Regneoppgaver til kapittel 7 Oppgave Anta at man har resultatet av et randomisert forsøk med to grupper, og observerer fra gruppe, mens man observerer X,, X,2,, X,n
10.1 Enkel lineær regresjon Multippel regresjon
 Inferens for regresjon 10.1 Enkel lineær regresjon 11.1-11.2 Multippel regresjon 2012 W.H. Freeman and Company Denne uken: Enkel lineær regresjon Litt repetisjon fra kapittel 2 Statistisk modell for enkel
Inferens for regresjon 10.1 Enkel lineær regresjon 11.1-11.2 Multippel regresjon 2012 W.H. Freeman and Company Denne uken: Enkel lineær regresjon Litt repetisjon fra kapittel 2 Statistisk modell for enkel
EKSAMENSOPPGAVER STAT100 Vår 2011
 EKSAMENSOPPGAVER STAT100 Vår 2011 Løsningsforslag Oppgave 1 (Med referanse til Tabell 1) a) De 3 fiskene på 2 år hadde lengder på henholdsvis 48, 46 og 35 cm. Finn de manglende tallene i Tabell 1. Test
EKSAMENSOPPGAVER STAT100 Vår 2011 Løsningsforslag Oppgave 1 (Med referanse til Tabell 1) a) De 3 fiskene på 2 år hadde lengder på henholdsvis 48, 46 og 35 cm. Finn de manglende tallene i Tabell 1. Test
Fasit for tilleggsoppgaver
 Fasit for tilleggsoppgaver Uke 5 Oppgave: Gitt en rekke med observasjoner x i (i = 1,, 3,, n), definerer vi variansen til x i som gjennomsnittlig kvadratavvik fra gjennomsnittet, m.a.o. Var(x i ) = (x
Fasit for tilleggsoppgaver Uke 5 Oppgave: Gitt en rekke med observasjoner x i (i = 1,, 3,, n), definerer vi variansen til x i som gjennomsnittlig kvadratavvik fra gjennomsnittet, m.a.o. Var(x i ) = (x
Fordelinger, mer om sentralmål og variasjonsmål. Tron Anders Moger
 Fordelinger, mer om sentralmål og variasjonsmål Tron Anders Moger 20. april 2005 1 Forrige gang: Så på et eksempel med data over medisinerstudenter Lærte hvordan man skulle få oversikt over dataene ved
Fordelinger, mer om sentralmål og variasjonsmål Tron Anders Moger 20. april 2005 1 Forrige gang: Så på et eksempel med data over medisinerstudenter Lærte hvordan man skulle få oversikt over dataene ved
HØGSKOLEN I STAVANGER
 EKSAMEN I: MOT0 STATISTISKE METODER VARIGHET: TIMER DATO:. NOVEMBER 00 TILLATTE HJELPEMIDLER: KALKULATOR, TABELLER OG FORMLER I STATISTIKK (TAPIR FORLAG) OPPGAVESETTET BESTÅR AV OPPGAVER PÅ 7 SIDER HØGSKOLEN
EKSAMEN I: MOT0 STATISTISKE METODER VARIGHET: TIMER DATO:. NOVEMBER 00 TILLATTE HJELPEMIDLER: KALKULATOR, TABELLER OG FORMLER I STATISTIKK (TAPIR FORLAG) OPPGAVESETTET BESTÅR AV OPPGAVER PÅ 7 SIDER HØGSKOLEN
Kapittel 9 og 10: Hypotesetesting
 Kapittel 9 og 1: Hypotesetesting Hypotesetesting er en standard vitenskapelig fremgangsmåte for å sjekke påstander. Generell problemstilling: Basert på informasjonen i data fra et tilfeldig utvalg ønsker
Kapittel 9 og 1: Hypotesetesting Hypotesetesting er en standard vitenskapelig fremgangsmåte for å sjekke påstander. Generell problemstilling: Basert på informasjonen i data fra et tilfeldig utvalg ønsker
Kort overblikk over kurset sålangt
 Kort overblikk over kurset sålangt Kapittel 1: Deskriptiv statististikk for en variabel Kapittel 2: Deskriptiv statistikk for samvariasjon mellom to variable (regresjon) Kapittel 3: Metoder for å innhente
Kort overblikk over kurset sålangt Kapittel 1: Deskriptiv statististikk for en variabel Kapittel 2: Deskriptiv statistikk for samvariasjon mellom to variable (regresjon) Kapittel 3: Metoder for å innhente
TMA4240 Statistikk H2010 (22)
") TMA4240 Statistikk H2010 (22) 10.11-10.12: Testing av andelser 10.13: Testing av varians i ett N utvalg Mette Langaas Foreleses onsdag 3.november, 2010 2 Laban strakk seg ikke lenger, men smaker den bedre?
TMA4240 Statistikk H2010 (22) 10.11-10.12: Testing av andelser 10.13: Testing av varians i ett N utvalg Mette Langaas Foreleses onsdag 3.november, 2010 2 Laban strakk seg ikke lenger, men smaker den bedre?
Oppgave 1. T = 9 Hypotesetest for å teste om kolesterolnivået har endret seg etter dietten: T observert = 2.16 0
 Løsningsforslag til eksamen i MOT310 STATISTISKE METODER 1 VARIGHET: 4 TIMER DATO: 08. mai 2008 TILLATTE HJELPEMIDLER: Kalkulator: HP30S, Casio FX82 eller TI-30 Tabeller og formler i statistikk (Tapir
Løsningsforslag til eksamen i MOT310 STATISTISKE METODER 1 VARIGHET: 4 TIMER DATO: 08. mai 2008 TILLATTE HJELPEMIDLER: Kalkulator: HP30S, Casio FX82 eller TI-30 Tabeller og formler i statistikk (Tapir
TMA4245 Statistikk Eksamen desember 2016
 Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag TMA4245 Statistikk Eksamen desember 2016 Oppgave 1 En bedrift produserer elektriske komponenter. Komponentene kan ha to typer
Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag TMA4245 Statistikk Eksamen desember 2016 Oppgave 1 En bedrift produserer elektriske komponenter. Komponentene kan ha to typer
Løsningsforslag Til Statlab 5
 Løsningsforslag Til Statlab 5 Jimmy Paul September 6, 007 Oppgave 8.1 Vi skal se på ukentlige forbruk av søtsaker blant barn i et visst område. En pilotstudie gir at standardavviket til det ukentige forbruket
Løsningsforslag Til Statlab 5 Jimmy Paul September 6, 007 Oppgave 8.1 Vi skal se på ukentlige forbruk av søtsaker blant barn i et visst område. En pilotstudie gir at standardavviket til det ukentige forbruket
Hypotesetest: generell fremgangsmåte
 TMA4240 Statistikk H2010 (21) 10.8, 10.10: To normalfordelte utvalg 10.9: Teststyrke og antall observasjoner Mette Langaas Foreleses mandag 1.november, 2010 2 Hypotesetest: generell fremgangsmåte Generell
TMA4240 Statistikk H2010 (21) 10.8, 10.10: To normalfordelte utvalg 10.9: Teststyrke og antall observasjoner Mette Langaas Foreleses mandag 1.november, 2010 2 Hypotesetest: generell fremgangsmåte Generell
TMA4240 Statistikk H2010 (20)
") TMA4240 Statistikk H2010 (20) 10.5: Ett normalfordelt utvalg, kjent varians (repetisjon) 10.4: P-verdi 10.6: Konfidensintervall vs. hypotesetest 10.7: Ett normalfordelt utvalg, ukjent varians Mette Langaas
TMA4240 Statistikk H2010 (20) 10.5: Ett normalfordelt utvalg, kjent varians (repetisjon) 10.4: P-verdi 10.6: Konfidensintervall vs. hypotesetest 10.7: Ett normalfordelt utvalg, ukjent varians Mette Langaas
Kap. 8: Utvalsfordelingar og databeskrivelse
 Kap. 8: Utvalsfordelingar og databeskrivelse Utvalsfordelingar Utvalsfordeling for gjennomsnitt (med kjent varians) ( X ) Sentralgrenseteoremet (SGT) Utvalsfordeling for varians (normalfordeling) Utvalfordeling
Kap. 8: Utvalsfordelingar og databeskrivelse Utvalsfordelingar Utvalsfordeling for gjennomsnitt (med kjent varians) ( X ) Sentralgrenseteoremet (SGT) Utvalsfordeling for varians (normalfordeling) Utvalfordeling
Seksjon 1.3 Tetthetskurver og normalfordelingen
 Seksjon 1.3 Tetthetskurver og normalfordelingen Har sett på ulike metoder for å plotte eller oppsummere data ved tall Vil nå starte på hvordan beskrive data ved modeller Hovedmetode er tetthetskurver Tetthetskurver
Seksjon 1.3 Tetthetskurver og normalfordelingen Har sett på ulike metoder for å plotte eller oppsummere data ved tall Vil nå starte på hvordan beskrive data ved modeller Hovedmetode er tetthetskurver Tetthetskurver
Forelesning 6: Punktestimering, usikkerhet i estimering. Jo Thori Lind
 Forelesning 6: Punktestimering, usikkerhet i estimering Jo Thori Lind j.t.lind@econ.uio.no Oversikt 1. Trekke utvalg 2. Estimatorer og observatorer som stokastiske variable 3. Egenskapene til en estimator
Forelesning 6: Punktestimering, usikkerhet i estimering Jo Thori Lind j.t.lind@econ.uio.no Oversikt 1. Trekke utvalg 2. Estimatorer og observatorer som stokastiske variable 3. Egenskapene til en estimator
Oppgave 1. X 1 B(n 1, p 1 ) X 2. Vi er interessert i forskjellen i andeler p 1 p 2, som vi estimerer med. p 1 p 2 = X 1. n 1 n 2.
 X 2. Vi er interessert i forskjellen i andeler p 1 p 2, som vi estimerer med. p 1 p 2 = X 1. n 1 n 2.") Løsningsforslag til eksamen i MOT310 STATISTISKE METODER 1 VARIGHET: 4 TIMER DATO: 17 november 2008 TILLATTE HJELPEMIDLER: Kalkulator: HP30S, Casio FX82 eller TI-30 Tabeller og formler i statistikk Tapir
Løsningsforslag til eksamen i MOT310 STATISTISKE METODER 1 VARIGHET: 4 TIMER DATO: 17 november 2008 TILLATTE HJELPEMIDLER: Kalkulator: HP30S, Casio FX82 eller TI-30 Tabeller og formler i statistikk Tapir
OPPGAVESETTET BESTÅR AV 3 OPPGAVER PÅ 6 SIDER MERKNADER: Alle deloppgaver vektlegges likt.
 EKSAMEN I: MOT310 STATISTISKE METODER 1 VARIGHET: 4 TIMER DATO: 08. mai 2008 TILLATTE HJELPEMIDLER: Kalkulator: HP30S, Casio FX82 eller TI-30 Tabeller og formler i statistikk (Tapir forlag) OPPGAVESETTET
EKSAMEN I: MOT310 STATISTISKE METODER 1 VARIGHET: 4 TIMER DATO: 08. mai 2008 TILLATTE HJELPEMIDLER: Kalkulator: HP30S, Casio FX82 eller TI-30 Tabeller og formler i statistikk (Tapir forlag) OPPGAVESETTET
TMA4240 Statistikk H2010
 TMA4240 Statistikk H2010 9.8: To uvalg (siste del) 9.9: Parvise observasjoner 9.10-9.11: Andelser 9.12: Varians Mette Langaas Foreleses onsdag 20.oktober, 2010 2 Norske hoppdommere og Janne Ahonen Janne
TMA4240 Statistikk H2010 9.8: To uvalg (siste del) 9.9: Parvise observasjoner 9.10-9.11: Andelser 9.12: Varians Mette Langaas Foreleses onsdag 20.oktober, 2010 2 Norske hoppdommere og Janne Ahonen Janne
Norske hoppdommere og Janne Ahonen
 TMA440 Statistikk H010 9.8: To uvalg (siste del) 9.9: Parvise observasjoner 9.10-9.11: Andelser 9.1: Varians Mette Langaas Foreleses onsdag 0.oktober, 010 Norske hoppdommere og Janne Ahonen Janne Ahonen
TMA440 Statistikk H010 9.8: To uvalg (siste del) 9.9: Parvise observasjoner 9.10-9.11: Andelser 9.1: Varians Mette Langaas Foreleses onsdag 0.oktober, 010 Norske hoppdommere og Janne Ahonen Janne Ahonen
Tillatte hjelpemidler: C3: alle typer kalkulator, alle andre hjelpemidler
 EKSAMENSOPPGAVER Institutt: Eksamen i: Tid: IKBM STAT100 Torsdag 13.des 2012 STATISTIKK 09.00-12.30 (3.5 timer) Emneansvarlig: Solve Sæbø ( 90065281) Tillatte hjelpemidler: C3: alle typer kalkulator, alle
EKSAMENSOPPGAVER Institutt: Eksamen i: Tid: IKBM STAT100 Torsdag 13.des 2012 STATISTIKK 09.00-12.30 (3.5 timer) Emneansvarlig: Solve Sæbø ( 90065281) Tillatte hjelpemidler: C3: alle typer kalkulator, alle
Econ 2130 uke 16 (HG)
") Econ 213 uke 16 (HG) Hypotesetesting I Løvås: 6.4.1 6, 6.5.1-2 1 Testing av µ i uid modellen (situasjon I Z-test ). Grunnbegreper. Eksempel. En lege står overfor følgende problemstilling. Standardbehandling
Econ 213 uke 16 (HG) Hypotesetesting I Løvås: 6.4.1 6, 6.5.1-2 1 Testing av µ i uid modellen (situasjon I Z-test ). Grunnbegreper. Eksempel. En lege står overfor følgende problemstilling. Standardbehandling
Hypotesetesting. mot. mot. mot. ˆ x
 Kapittel 6.4-6.5: ypotesetesting ypotesetesting er en standard vitenskapelig fremgangsmåte for å sjekke påstander. Generell problemstilling: Basert på informasjonen i data fra et tilfeldig utvalg ønsker
Kapittel 6.4-6.5: ypotesetesting ypotesetesting er en standard vitenskapelig fremgangsmåte for å sjekke påstander. Generell problemstilling: Basert på informasjonen i data fra et tilfeldig utvalg ønsker
EKSAMEN I FAG TMA4260 INDUSTRIELL STATISTIKK
 Norges teknisk naturvitenskapelige universitet Institutt for matematiske fag Side 1 av 12 Faglig kontakt under eksamen: Bo Lindqvist Tlf. 975 89 418 EKSAMEN I FAG TMA4260 INDUSTRIELL STATISTIKK Onsdag
Norges teknisk naturvitenskapelige universitet Institutt for matematiske fag Side 1 av 12 Faglig kontakt under eksamen: Bo Lindqvist Tlf. 975 89 418 EKSAMEN I FAG TMA4260 INDUSTRIELL STATISTIKK Onsdag
Utvalgsfordelinger. Utvalg er en tilfeldig mekanisme. Sannsynlighetsregning dreier seg om tilfeldige mekanismer.
 Utvalgsfordelinger Vi har sett at utvalgsfordelinger til en statistikk (observator) er fordelingen av verdiene statistikken tar ved mange gjenttatte utvalg av samme størrelse fra samme populasjon. Utvalg
Utvalgsfordelinger Vi har sett at utvalgsfordelinger til en statistikk (observator) er fordelingen av verdiene statistikken tar ved mange gjenttatte utvalg av samme størrelse fra samme populasjon. Utvalg
Løsningsforsalg til andre sett med obligatoriske oppgaver i STK1110 høsten 2015
 Løsningsforsalg til andre sett med obligatoriske oppgaver i STK1110 høsten 2015 R-kode for alle oppgaver er gitt bakerst. Oppgave 1 (a) Boksplottet antyder at verdiene er høyere for kvinner enn for menn.
Løsningsforsalg til andre sett med obligatoriske oppgaver i STK1110 høsten 2015 R-kode for alle oppgaver er gitt bakerst. Oppgave 1 (a) Boksplottet antyder at verdiene er høyere for kvinner enn for menn.
Statistikk og dataanalyse
 Njål Foldnes, Steffen Grønneberg og Gudmund Horn Hermansen Statistikk og dataanalyse En moderne innføring Kapitteloversikt del 1 INTRODUKSJON TIL STATISTIKK Kapittel 1 Populasjon og utvalg 19 Kapittel
Njål Foldnes, Steffen Grønneberg og Gudmund Horn Hermansen Statistikk og dataanalyse En moderne innføring Kapitteloversikt del 1 INTRODUKSJON TIL STATISTIKK Kapittel 1 Populasjon og utvalg 19 Kapittel
I enkel lineær regresjon beskrev linja. μ y = β 0 + β 1 x
 Multiple regresjon Her utvider vi perspektivet for enkel lineær regresjon til også å omfatte flere forklaringsvariable.det er fortsatt en responsvariabel. Måten dette gjøre på er nokså naturlig. Prediktoren
Multiple regresjon Her utvider vi perspektivet for enkel lineær regresjon til også å omfatte flere forklaringsvariable.det er fortsatt en responsvariabel. Måten dette gjøre på er nokså naturlig. Prediktoren
TMA4240 Statistikk Høst 2009
 TMA4240 Statistikk Høst 2009 Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag Øving nummer b5 Løsningsskisse Oppgave 1 Vi ønsker å finne ut om et nytt serum kan stanse leukemi.
TMA4240 Statistikk Høst 2009 Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag Øving nummer b5 Løsningsskisse Oppgave 1 Vi ønsker å finne ut om et nytt serum kan stanse leukemi.
Eksamensoppgave i TMA4240 Statistikk
 Institutt for matematiske fag Eksamensoppgave i TMA4240 Statistikk Faglig kontakt under eksamen: Mette Langaas a, Ingelin Steinsland b, Geir-Arne Fuglstad c Tlf: a 988 47 649, b 926 63 096, c 452 70 806
Institutt for matematiske fag Eksamensoppgave i TMA4240 Statistikk Faglig kontakt under eksamen: Mette Langaas a, Ingelin Steinsland b, Geir-Arne Fuglstad c Tlf: a 988 47 649, b 926 63 096, c 452 70 806
Bivariate analyser. Analyse av sammenhengen mellom to variabler. H 0 : Ingen sammenheng H 1 : Sammenheng
 Bivariate analyser Analyse av sammenhengen mellom to variabler H : Ingen sammenheng H 1 : Sammenheng Hvis den ene variabelen er kategorisk er en slik analyse det samme som å sammenligne grupper. Ulike
Bivariate analyser Analyse av sammenhengen mellom to variabler H : Ingen sammenheng H 1 : Sammenheng Hvis den ene variabelen er kategorisk er en slik analyse det samme som å sammenligne grupper. Ulike
1 Section 7-2: Estimere populasjonsandelen. 2 Section 7-4: Estimere µ når σ er ukjent
 1 Section 7-2: Estimere populasjonsandelen 2 Section 7-4: Estimere µ når σ er ukjent Kapittel 7 Nå begynner vi med statistisk inferens! Bruke stikkprøven til å 1 Estimere verdien til en parameter i populasjonen.
1 Section 7-2: Estimere populasjonsandelen 2 Section 7-4: Estimere µ når σ er ukjent Kapittel 7 Nå begynner vi med statistisk inferens! Bruke stikkprøven til å 1 Estimere verdien til en parameter i populasjonen.
Sensorveiledning: skoleeksamen i SOS Kvantitativ metode
 Sensorveiledning: skoleeksamen i SOS1120 - Kvantitativ metode Tirsdag 30. mai 2016 (4 timer) Poenggivning og karakter I del 1 gis det ett poeng for hvert riktige svar. Ubesvart eller feil svar gis 0 poeng.
Sensorveiledning: skoleeksamen i SOS1120 - Kvantitativ metode Tirsdag 30. mai 2016 (4 timer) Poenggivning og karakter I del 1 gis det ett poeng for hvert riktige svar. Ubesvart eller feil svar gis 0 poeng.
1 Sec 3-2: Hvordan beskrive senteret i dataene. 2 Sec 3-3: Hvordan beskrive spredningen i dataene
 1 Sec 3-2: Hvordan beskrive senteret i dataene 2 Sec 3-3: Hvordan beskrive spredningen i dataene Todeling av statistikk Deskriptiv statistikk Oppsummering og beskrivelse av den stikkprøven du har. Statistisk
1 Sec 3-2: Hvordan beskrive senteret i dataene 2 Sec 3-3: Hvordan beskrive spredningen i dataene Todeling av statistikk Deskriptiv statistikk Oppsummering og beskrivelse av den stikkprøven du har. Statistisk
Medisinsk statistikk Del I høsten 2009:
 Medisinsk statistikk Del I høsten 2009: Kontinuerlige sannsynlighetsfordelinger Pål Romundstad Beregning av sannsynlighet i en binomisk forsøksrekke generelt Sannsynligheten for at suksess intreffer X
Medisinsk statistikk Del I høsten 2009: Kontinuerlige sannsynlighetsfordelinger Pål Romundstad Beregning av sannsynlighet i en binomisk forsøksrekke generelt Sannsynligheten for at suksess intreffer X
Tid: 29. mai (3.5 timer) Ved alle hypotesetester skal både nullhypotese og alternativ hypotese skrives ned.
 Ved alle hypotesetester skal både nullhypotese og alternativ hypotese skrives ned.") EKSAMENSOPPGAVE, bokmål Institutt: IKBM Eksamen i: STAT100 STATISTIKK Tid: 29. mai 2012 09.00-12.30 (3.5 timer) Emneansvarlig: Trygve Almøy (Tlf: 95141344) Tillatte hjelpemidler: C3: alle typer kalkulator,
EKSAMENSOPPGAVE, bokmål Institutt: IKBM Eksamen i: STAT100 STATISTIKK Tid: 29. mai 2012 09.00-12.30 (3.5 timer) Emneansvarlig: Trygve Almøy (Tlf: 95141344) Tillatte hjelpemidler: C3: alle typer kalkulator,
UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet
 UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i: STK1120 Statistiske metoder og dataanalyse 2 Eksamensdag: Mandag 4. juni 2007. Tid for eksamen: 14.30 17.30. Oppgavesettet er
UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i: STK1120 Statistiske metoder og dataanalyse 2 Eksamensdag: Mandag 4. juni 2007. Tid for eksamen: 14.30 17.30. Oppgavesettet er
Statistisk inferens: 9.14: Sannsynlighetsmaksimeringsestimatoren 8.5: Fordeling til gjennomsnittet 9.4: Konfidensintervall for µ (σ kjent)
") TMA440 Statistikk H010 Statistisk inferens: 9.14: Sannsynlighetsmaksimeringsestimatoren 8.5: Fordeling til gjennomsnittet 9.4: Konfidensintervall for µ (σ kjent) Mette Langaas Foreleses mandag 11.oktober,
TMA440 Statistikk H010 Statistisk inferens: 9.14: Sannsynlighetsmaksimeringsestimatoren 8.5: Fordeling til gjennomsnittet 9.4: Konfidensintervall for µ (σ kjent) Mette Langaas Foreleses mandag 11.oktober,
Datamatrisen: observasjoner, variabler og verdier. Variablers målenivå: Nominal Ordinal Intervall Forholdstall (ratio)
") Datamatrisen: observasjoner, variabler og verdier. Variablers målenivå: Nominal Ordinal Intervall Forholdstall (ratio) Beskrive fordelinger (sentraltendens, variasjon og form): Observasjon y i Sentraltendens
Datamatrisen: observasjoner, variabler og verdier. Variablers målenivå: Nominal Ordinal Intervall Forholdstall (ratio) Beskrive fordelinger (sentraltendens, variasjon og form): Observasjon y i Sentraltendens
UNIVERSITETET I OSLO
 UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i: STK1000 Innføring i anvendt statistikk Eksamensdag: Onsdag 12. oktober 2016 Tid for eksamen: 10.00 12.00 Oppgavesettet er på
UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i: STK1000 Innføring i anvendt statistikk Eksamensdag: Onsdag 12. oktober 2016 Tid for eksamen: 10.00 12.00 Oppgavesettet er på
ÅMA110 Sannsylighetsregning og statistikk Løsningsforslag til eksamen høst 2010, s. 1. Oppgave 1. Histogram over frekvenser.
 ÅMA1 Sannsylighetsregning og statistikk Løsningsforslag til eksamen høst 0, s. 1 (Det tas forbehold om feil i løsningsforslaget.) a) Gjennomsnitt: x = 1 Emp. standardavvik: Median: 1 (1.33 + 1.) = 1.35
ÅMA1 Sannsylighetsregning og statistikk Løsningsforslag til eksamen høst 0, s. 1 (Det tas forbehold om feil i løsningsforslaget.) a) Gjennomsnitt: x = 1 Emp. standardavvik: Median: 1 (1.33 + 1.) = 1.35
ÅMA110 Sannsynlighetsregning med statistikk, våren 2006 Kp. 6, del 4
 ÅMA110 Sannsynlighetsregning med statistikk, våren 2006 Kp. 6, del 4 Bjørn H. Auestad Institutt for matematikk og naturvitenskap Universitetet i Stavanger 27. mars Bjørn H. Auestad Kp. 6: Hypotesetesting
ÅMA110 Sannsynlighetsregning med statistikk, våren 2006 Kp. 6, del 4 Bjørn H. Auestad Institutt for matematikk og naturvitenskap Universitetet i Stavanger 27. mars Bjørn H. Auestad Kp. 6: Hypotesetesting
UNIVERSITETET I OSLO
 UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i STK1000 Innføring i anvendt statistikk. Eksamensdag: Torsdag 9. oktober 2008. Tid for eksamen: 15:00 17:00. Oppgavesettet er på
UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i STK1000 Innføring i anvendt statistikk. Eksamensdag: Torsdag 9. oktober 2008. Tid for eksamen: 15:00 17:00. Oppgavesettet er på
TMA4240 Statistikk H2010
 TMA4240 Statistikk H2010 Statistisk inferens: 8.1: Tilfeldig utvalg 9.1-9.3: Estimering Mette Langaas Foreleses uke 40, 2010 2 Utfordring Ved en bedrift produseres en elektrisk komponent. Komponenten må
TMA4240 Statistikk H2010 Statistisk inferens: 8.1: Tilfeldig utvalg 9.1-9.3: Estimering Mette Langaas Foreleses uke 40, 2010 2 Utfordring Ved en bedrift produseres en elektrisk komponent. Komponenten må
Utfordring. TMA4240 Statistikk H2010. Mette Langaas. Foreleses uke 40, 2010
 TMA4240 Statistikk H2010 Statistisk inferens: 8.1: Tilfeldig utvalg 9.1-9.3: Estimering Mette Langaas Foreleses uke 40, 2010 2 Utfordring Ved en bedrift produseres en elektrisk komponent. Komponenten må
TMA4240 Statistikk H2010 Statistisk inferens: 8.1: Tilfeldig utvalg 9.1-9.3: Estimering Mette Langaas Foreleses uke 40, 2010 2 Utfordring Ved en bedrift produseres en elektrisk komponent. Komponenten må
Løsningsforslag STK1110-h11: Andre obligatoriske oppgave.
 Løsningsforslag STK1110-h11: Andre obligatoriske oppgave. Oppgave 1 a) Legg merke til at X er gamma-fordelt med formparameter 1 og skalaparameter λ. Da er E[X] = 1/λ. Små verdier av X tyder derfor på at
Løsningsforslag STK1110-h11: Andre obligatoriske oppgave. Oppgave 1 a) Legg merke til at X er gamma-fordelt med formparameter 1 og skalaparameter λ. Da er E[X] = 1/λ. Små verdier av X tyder derfor på at
Snøtetthet. Institutt for matematiske fag, NTNU 15. august Notat for TMA4240/TMA4245 Statistikk
 Snøtetthet Notat for TMA424/TMA4245 Statistikk Institutt for matematiske fag, NTNU 5. august 22 I forbindelse med varsling av om, klimaforskning og særlig kraftproduksjon er det viktig å kunne anslå hvor
Snøtetthet Notat for TMA424/TMA4245 Statistikk Institutt for matematiske fag, NTNU 5. august 22 I forbindelse med varsling av om, klimaforskning og særlig kraftproduksjon er det viktig å kunne anslå hvor
Skoleeksamen i SOS Kvantitativ metode
 Skoleeksamen i SOS1120 - Kvantitativ metode Hjelpemidler Ordbok Alle typer kalkulatorer Tirsdag 30. mai 2017 (4 timer) Lærerbok (det er mulig mulig å ha med en annen, tilsvarende pensumbok, som erstatning
Skoleeksamen i SOS1120 - Kvantitativ metode Hjelpemidler Ordbok Alle typer kalkulatorer Tirsdag 30. mai 2017 (4 timer) Lærerbok (det er mulig mulig å ha med en annen, tilsvarende pensumbok, som erstatning
TMA4240 Statistikk H2010
 TMA4240 Statistikk H2010 Statistisk inferens: 9.14: Sannsynlighetsmaksimeringsestimatoren 8.5: Fordeling til gjennomsnittet 9.4: Konfidensintervall for µ (σ kjent) Mette Langaas Foreleses mandag 11.oktober,
TMA4240 Statistikk H2010 Statistisk inferens: 9.14: Sannsynlighetsmaksimeringsestimatoren 8.5: Fordeling til gjennomsnittet 9.4: Konfidensintervall for µ (σ kjent) Mette Langaas Foreleses mandag 11.oktober,
i x i
 TMA4245 Statistikk Vår 2016 Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag Anbefalte oppgaver 11, blokk II Oppgavene i denne øvingen dreier seg om hypotesetesting og sentrale
TMA4245 Statistikk Vår 2016 Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag Anbefalte oppgaver 11, blokk II Oppgavene i denne øvingen dreier seg om hypotesetesting og sentrale
ÅMA110 Sannsynlighetsregning med statistikk, våren Hypotesetesting (kp. 6) Hypotesetesting, innledning. Kp.
 Hypotesetesting, innledning. Kp.") ÅMA Sannsynlighetsregning med statistikk, våren 8 Kp. 6 Hypotesetesting Hypotesetesting (kp. 6) Tre deler av faget/kurset:. Beskrivende statistikk. Sannsynlighetsteori, sannsynlighetsregning 3. Statistisk
ÅMA Sannsynlighetsregning med statistikk, våren 8 Kp. 6 Hypotesetesting Hypotesetesting (kp. 6) Tre deler av faget/kurset:. Beskrivende statistikk. Sannsynlighetsteori, sannsynlighetsregning 3. Statistisk
TMA4240 Statistikk Høst 2016
 TMA4240 Statistikk Høst 2016 Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag Anbefalt øving 11 Oppgavene i denne øvingen dreier seg om hypotesetesting og sentrale begreper
TMA4240 Statistikk Høst 2016 Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag Anbefalt øving 11 Oppgavene i denne øvingen dreier seg om hypotesetesting og sentrale begreper
Løsningsforslag eksamen 25. november 2003
 MOT310 Statistiske metoder 1 Løsningsforslag eksamen 25. november 2003 Oppgave 1 a) Vi har µ D = µ X µ Y. Sangere bruker generelt trapesius-muskelen mindre etter biofeedback dersom forventet bruk av trapesius
MOT310 Statistiske metoder 1 Løsningsforslag eksamen 25. november 2003 Oppgave 1 a) Vi har µ D = µ X µ Y. Sangere bruker generelt trapesius-muskelen mindre etter biofeedback dersom forventet bruk av trapesius
Forelesning 7: Store talls lov, sentralgrenseteoremet. Jo Thori Lind
 Forelesning 7: Store talls lov, sentralgrenseteoremet Jo Thori Lind j.t.lind@econ.uio.no Oversikt 1. Estimering av variansen 2. Asymptotisk teori 3. Store talls lov 4. Sentralgrenseteoremet 1.Estimering
Forelesning 7: Store talls lov, sentralgrenseteoremet Jo Thori Lind j.t.lind@econ.uio.no Oversikt 1. Estimering av variansen 2. Asymptotisk teori 3. Store talls lov 4. Sentralgrenseteoremet 1.Estimering
Kapittel 9 og 10: Hypotesetesting
 Kapittel 9 og 1: ypotesetesting ypotesetesting er en standard vitenskapelig fremgangsmåte for å sjekke påstander. Generell problemstilling: Basert på informasjonen i data fra et tilfeldig utvalg ønsker
Kapittel 9 og 1: ypotesetesting ypotesetesting er en standard vitenskapelig fremgangsmåte for å sjekke påstander. Generell problemstilling: Basert på informasjonen i data fra et tilfeldig utvalg ønsker
Utvalgsfordelinger. Utvalg er en tilfeldig mekanisme. Sannsynlighetsregning dreier seg om tilfeldige mekanismer.
 Utvalgsfordelinger Vi har sett at utvalgsfordelinger til en observator er fordelingen av verdiene observatoren tar ved mange gjenttatte utvalg av samme størrelse fra samme populasjon. Utvalg er en tilfeldig
Utvalgsfordelinger Vi har sett at utvalgsfordelinger til en observator er fordelingen av verdiene observatoren tar ved mange gjenttatte utvalg av samme størrelse fra samme populasjon. Utvalg er en tilfeldig
ST0202 Statistikk for samfunnsvitere
 ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Kap. 13: Lineær korrelasjons- og regresjonsanalyse Kap. 13.1-13.3: Lineær korrelasjonsanalyse. Disse avsnitt er ikke pensum,
ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Kap. 13: Lineær korrelasjons- og regresjonsanalyse Kap. 13.1-13.3: Lineær korrelasjonsanalyse. Disse avsnitt er ikke pensum,
ÅMA110 Sannsynlighetsregning med statistikk, våren
 ÅMA110 Sannsynlighetsregning med statistikk, våren 2006 Kp. 6, del 4 Bjørn H. Auestad Institutt for matematikk og naturvitenskap Universitetet i Stavanger 3. april Bjørn H. Auestad Kp. 6: Hypotesetesting
ÅMA110 Sannsynlighetsregning med statistikk, våren 2006 Kp. 6, del 4 Bjørn H. Auestad Institutt for matematikk og naturvitenskap Universitetet i Stavanger 3. april Bjørn H. Auestad Kp. 6: Hypotesetesting
2. Hva er en sampelfordeling? Nevn tre eksempler på sampelfordelinger.
 H12 - Semesteroppgave i statistikk - sensurveiledning Del 1 - teori 1. Gjør rede for resonnementet bak ANOVA. Enveis ANOVA tester om det er forskjeller mellom gjennomsnittene i tre eller flere populasjoner.
H12 - Semesteroppgave i statistikk - sensurveiledning Del 1 - teori 1. Gjør rede for resonnementet bak ANOVA. Enveis ANOVA tester om det er forskjeller mellom gjennomsnittene i tre eller flere populasjoner.
Forelesning 23 og 24 Wilcoxon test, Bivariate Normal fordeling
 Forelesning 23 og 24 Wilcoxon test, Bivariate Normal fordeling Wilcoxon Signed-Rank Test I uke, bruker vi Z test eller t-test for hypotesen H:, og begge tester er basert på forutsetningen om normalfordeling
Forelesning 23 og 24 Wilcoxon test, Bivariate Normal fordeling Wilcoxon Signed-Rank Test I uke, bruker vi Z test eller t-test for hypotesen H:, og begge tester er basert på forutsetningen om normalfordeling
Kontroller at oppgavesettet er komplett før du begynner å besvare spørsmålene. Ved sensuren teller alle delspørsmål likt.
 Eksamen i: MET040 Statistikk for økonomer Eksamensdag: 4. juni 2008 Tid for eksamen: 09.00-13.00 Oppgavesettet er på 5 sider. Tillatte hjelpemidler: Alle trykte eller egenskrevne hjelpemidler og kalkulator.
Eksamen i: MET040 Statistikk for økonomer Eksamensdag: 4. juni 2008 Tid for eksamen: 09.00-13.00 Oppgavesettet er på 5 sider. Tillatte hjelpemidler: Alle trykte eller egenskrevne hjelpemidler og kalkulator.