Et lite notat om og rundt normalfordelingen.
|
|
|
- Inger Iversen
- 6 år siden
- Visninger:
Transkript
1 Et lite notat om og rundt normalfordelingen. Anta at vi har kontinuerlige data. Hva er likt og ulikt for histogrammer og fordelingskurver? Observasjoner Histogram Viser fordelingen av faktiske observerte verdier som søyler i intervaller Kan være symmetrisk, skjev, ha en eller flere topper, lette eller tunge haler (outliere/ekstremverdier) Gjennomsnitt: x Tyngdepunktet for histogrammet Median: Verdien som har like mange observasjoner på hver side Kvartiler: Deler inn observasjonene i fire grupper med like mange observasjoner i hver gruppe (Empirisk) standardavvik: sd, SD Varians Teoretisk/tenkt Fordelingskurve Viser den idealiserte fordelingen av verdier som en kontinuerlig kurve Kan være symmetrisk, skjev, ha en eller flere topper, lette eller tunge haler Forventningsverdi: Tyngdepunktet for kurven Median: Verdien som har like mye areal under kurven på hver side Kvartiler: Deler inn x-aksen i fire intervaller, så det er like stort areal under kurven i hvert intervall. Standardavvik: σ Varians: σ 2 Toppunkt = Mode Histogrammer kan enten vise antall på y-aksen, eller skaleres slik at arealet av hver søyle reflekterer andelen av observasjonene som er i det gitte intervallet. Fordelingskurver har totalt areal lik 1. Velger vi et intervall på x- aksen, vil arealet under kurven i dette intervallet tilsvare andelen verdier som havner i intervallet.
2
3

4 Hei på deg, normalfordeling! (Finn μ og σ)


5 Normalfordeling Hvordan ser en normalfordeling ut? OBS: Teoretisk sannsynlighetstetthet Entoppet, symmetrisk, lette haler. «Bell-shaped» Formelen for normalfordeling: Normalfordelingen og dens far: Johann Carl Friedrich Gauß ( )
6 Hva bruker vi den til, og hvorfor er den viktig? Normalfordelingen brukes (blant annet) som modell for observerte data, når fordelingen til observasjonene er entoppet, symmetrisk og har lette haler:
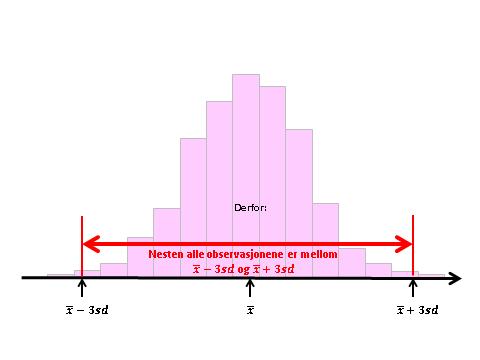
7 En praktisk anvendelse: Oppsummeringstall for det vanlige/typiske/senteret i en fordeling av kontinuerlige data (av og til diskrete data): Standardavviket er et utmerket oppsummeringstall for spredningen når datasettet ligner på en normalfordeling, altså når fordelingen er symmetrisk, entoppet, og har lette haler, fordi: Da vil intervallet x ± 2sd inneholde omtrent 95% av observasjonene, og så godt som ingen observasjoner befinner seg utenfor x ± 3sd. Hvis man oppgir x og sd som oppsummeringstall, har man altså implisitt sagt at fordelingen ligner på en normalfordeling, og at de fleste observasjonene ligger mellom 2 til 3 standardavvik fra midten. Hvorfor? Normalfordelingen er formulert som en formel (!), og kan regnes på:
8
9
10 Standardisering: Fra originalobservasjoner til z-scorer. Normalfordelingen er gitt ved der y viser høyden på y-aksen, og x er verdiene til variabelen som er normalfordelt. Siden μ kan være et hvilket som helst tall på tallinja, og σ kan være et hvilket som helst tall større eller lik null, finnes det uendelig mange normalfordelinger. Men alle normalfordelte verdier kan regnes om til en såkalt standard normalfordeling, som har forventning 0 og standardavvik 1. Hvis vi vet hva μ og σ er, finner vi z-scoren, altså den standardiserte verdien av x, slik: z = x μ σ
11 Vi bruker notasjonen N(μ, σ) for en generell normalfordeling, og N(0, 1) for en standard normalfordeling. Ofte skriver vi også X~N(μ, σ), og Z~N(0, 1). Slik ser fordelingene ut: X~N(μ, σ) Z~N(0, 1)

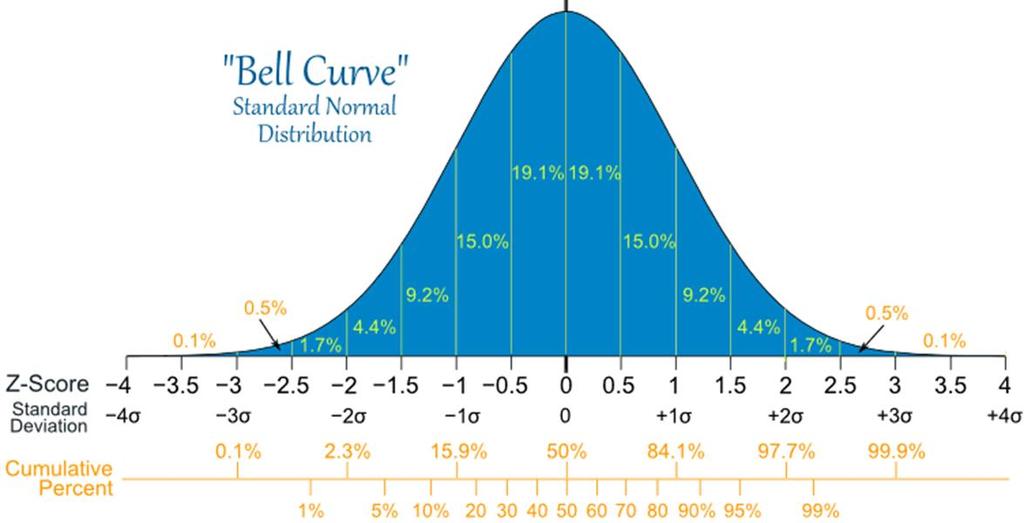
12 Eksempel: IQ (Ukas oppgave) IQ-tester er konstruert for å ha et populasjonsgjennomsnitt (μ) på 100, og standardavvik (σ) på 15: Jeg tok en IQ-test på og endte med et resultat på 115. Den tilsvarende z-scoren blir da z = x μ σ = 15 = 1 Ser på figuren at siden z-scoren er nøyaktig 1, kan det leses rett ut av figuren at 15.8% av befolkningen (13.6%+2.1%+0.1%) er smartere enn meg. Oppgave: Ta samme IQ-test som jeg har tatt, og regn om til z-score.
13 Hvis vi ikke vet hva μ og σ er, kan vi erstatte dem med x og sd, og allikevel lage z-scorer. Eksempel: Høyde: I en fil med høyde for 1016 kvinner som har født barn i perioden , er gjennomsnittshøyden cm, og sd 5.8 cm Med en høyde på cm har KFF en z-score på z = x μ σ = 5. 8 = Nå kan det ikke leses rett ut av figuren hvor stor andel som er høyere eller lavere enn meg. Da trenger vi en normalfordelingstabell!

14 Table A, side i boka: Med andre ord: 55.6% av norske kvinner er lavere enn meg. R: > pnorm(0.14) [1]
15 Hvordan sjekker vi om noe «er normalfordelt»? Lag histogram, boksplott: Sjekk symmetri og haler Fortsatt usikker? Lag normalfordelingsplott (QQ-plott): Hvis normalfordelt: Rett linje Hvis ikke rett linje: Ikke normalfordelt QQ-plott/Normal quantile plot lages ikke for hånd, vi bruker alltid programvare. Da gjøres dette i bakgrunnen: Sortér alle observasjonene dine fra lavest til høyest, og gjør dem om til percentiler, altså verdier som sier hvor stor andel av de observerte verdiene som er mindre eller lik den verdien du kikker på. Finn hvilken z-score de ulike percentilene ville hatt hvis de var i en N(0,1)-fordeling (Bruk tabellen motsatt vei) Plott observasjonene mot de tilsvarende z-scorene

16 Hvis normalfordelt: QQ-plottet viser en rett linje QQ-plottet viser ikke en rett linje: Ikke normalfordelt
17 (Fortsatt:) Hva bruker vi den til, og hvorfor er den viktig? Mange matematiske resultater (kall det gjerne formler) er basert på at enten dataene selv, eller en avledning av dataene, er normalfordelt. For eksempel er formelen for 95% konfidensintervall for populasjonsgjennomsnittet (forventningen) μ: x ± 1. 96SE(x ), Denne formelen stammer fra sentralgrenseteoremet, der normalfordelingen også dukker opp. Dette skal vi se på senere i kurset. Dessuten: Normalfordelingen er en god approksimasjon til binomisk fordeling med stor n, og poissonfordeling med høy frekvens, og det gjør utregningene av tester og konfidensintervaller mye enklere. Vi får da også at 95% konfidensintervall for en andel p i populasjonen: p ± 1. 96SE(p ) Dette kommer vi også til senere. Så: Mange statistiske analyser forutsetter at normalfordelingen er til stede, enten at observasjonene er normalfordelte, eller at noe avledet av data er normalfordelt.
Et lite notat om og rundt normalfordelingen.
 Et lite notat om og rundt normalfordelingen. Anta at vi har kontinuerlige data. Hva er likt og ulikt for histogrammer og fordelingskurver? Observasjoner Histogram Viser fordelingen av faktiske observerte
Et lite notat om og rundt normalfordelingen. Anta at vi har kontinuerlige data. Hva er likt og ulikt for histogrammer og fordelingskurver? Observasjoner Histogram Viser fordelingen av faktiske observerte
STK1000 Uke 36, Studentene forventes å lese Ch 1.4 ( ) i læreboka (MMC). Tetthetskurver. Eksempel: Drivstofforbruk hos 32 biler
 i læreboka (MMC). Tetthetskurver. Eksempel: Drivstofforbruk hos 32 biler") STK1000 Uke 36, 2016. Studentene forventes å lese Ch 1.4 (+ 3.1-3.3 + 3.5) i læreboka (MMC). Tetthetskurver Eksempel: Drivstofforbruk hos 32 biler Fra histogram til tetthetskurver Anta at vi har kontinuerlige
STK1000 Uke 36, 2016. Studentene forventes å lese Ch 1.4 (+ 3.1-3.3 + 3.5) i læreboka (MMC). Tetthetskurver Eksempel: Drivstofforbruk hos 32 biler Fra histogram til tetthetskurver Anta at vi har kontinuerlige
Et lite notat om og rundt normalfordelingen. Anta at vi har kontinuerlige data. Hva er likt og ulikt for histogrammer og fordelingskurver?
 Et lite notat om og rundt normalfordelingen. Anta at vi har kontinuerlige data. Hva er likt og ulikt for histogrammer og fordelingskurver? Boka (Ch 1.4) motiverer dette ved å gå fra histogrammer til tetthetskurver.
Et lite notat om og rundt normalfordelingen. Anta at vi har kontinuerlige data. Hva er likt og ulikt for histogrammer og fordelingskurver? Boka (Ch 1.4) motiverer dette ved å gå fra histogrammer til tetthetskurver.
ST0202 Statistikk for samfunnsvitere
 ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag Situasjonen er som i quiz-eksempelet: n = 4, p = 1/3 ( suksess betyr å gjette riktig alternativ), q = 2/3. Oppgave: Finn
ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag Situasjonen er som i quiz-eksempelet: n = 4, p = 1/3 ( suksess betyr å gjette riktig alternativ), q = 2/3. Oppgave: Finn
Seksjon 1.3 Tetthetskurver og normalfordelingen
 Seksjon 1.3 Tetthetskurver og normalfordelingen Har sett på ulike metoder for å plotte eller oppsummere data Vil nå starte på hvordan beskrive data ved modeller Hovedmetode er tetthetskurver Tetthetskurver
Seksjon 1.3 Tetthetskurver og normalfordelingen Har sett på ulike metoder for å plotte eller oppsummere data Vil nå starte på hvordan beskrive data ved modeller Hovedmetode er tetthetskurver Tetthetskurver
Binomisk sannsynlighetsfunksjon
 ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Binomisk sannsynlighetsfunksjon La det være n forsøk, sannsynlighet p for suksess og sannsynlighet q for fiasko. Den tilfeldige
ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Binomisk sannsynlighetsfunksjon La det være n forsøk, sannsynlighet p for suksess og sannsynlighet q for fiasko. Den tilfeldige
Løsning på Dårlige egg med bruk av Tabell 2 i Appendix B
 Situasjonen er som i quiz-eksempelet: n = 4, p = 1/3 ( suksess betyr å gjette riktig alternativ), q = 2/3. Oppgave: Finn P(x), x=0,1,2,3,4 fra den generelle formelen for binomisk sannsynlighetsfordeling
Situasjonen er som i quiz-eksempelet: n = 4, p = 1/3 ( suksess betyr å gjette riktig alternativ), q = 2/3. Oppgave: Finn P(x), x=0,1,2,3,4 fra den generelle formelen for binomisk sannsynlighetsfordeling
UNIVERSITETET I OSLO
 UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i: STK1000 Innføring i anvendt statistikk Eksamensdag: Onsdag 12. oktober 2016 Tid for eksamen: 10.00 12.00 Oppgavesettet er på
UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i: STK1000 Innføring i anvendt statistikk Eksamensdag: Onsdag 12. oktober 2016 Tid for eksamen: 10.00 12.00 Oppgavesettet er på
Seksjon 1.3 Tetthetskurver og normalfordelingen
 Seksjon 1.3 Tetthetskurver og normalfordelingen Har sett på ulike metoder for å plotte eller oppsummere data ved tall Vil nå starte på hvordan beskrive data ved modeller Hovedmetode er tetthetskurver Tetthetskurver
Seksjon 1.3 Tetthetskurver og normalfordelingen Har sett på ulike metoder for å plotte eller oppsummere data ved tall Vil nå starte på hvordan beskrive data ved modeller Hovedmetode er tetthetskurver Tetthetskurver
Forelesning 5: Kontinuerlige fordelinger, normalfordelingen. Jo Thori Lind
 Forelesning 5: Kontinuerlige fordelinger, normalfordelingen Jo Thori Lind j.t.lind@econ.uio.no Oversikt 1. Kontinuerlige fordelinger 2. Uniform fordeling 3. Normal-fordelingen 1. Kontinuerlige fordelinger
Forelesning 5: Kontinuerlige fordelinger, normalfordelingen Jo Thori Lind j.t.lind@econ.uio.no Oversikt 1. Kontinuerlige fordelinger 2. Uniform fordeling 3. Normal-fordelingen 1. Kontinuerlige fordelinger
Utvalgsfordelinger; utvalg, populasjon, grafiske metoder, X, S 2, t-fordeling, χ 2 -fordeling
 Kapittel 8 Utvalgsfordelinger; utvalg, populasjon, grafiske metoder, X, S 2, t-fordeling, χ 2 -fordeling TMA4240 H2006: Eirik Mo 2 Til nå... Definert sannsynlighet og stokastiske variabler (kap. 2 & 3).
Kapittel 8 Utvalgsfordelinger; utvalg, populasjon, grafiske metoder, X, S 2, t-fordeling, χ 2 -fordeling TMA4240 H2006: Eirik Mo 2 Til nå... Definert sannsynlighet og stokastiske variabler (kap. 2 & 3).
Statistikk og dataanalyse
 Njål Foldnes, Steffen Grønneberg og Gudmund Horn Hermansen Statistikk og dataanalyse En moderne innføring Kapitteloversikt del 1 INTRODUKSJON TIL STATISTIKK Kapittel 1 Populasjon og utvalg 19 Kapittel
Njål Foldnes, Steffen Grønneberg og Gudmund Horn Hermansen Statistikk og dataanalyse En moderne innføring Kapitteloversikt del 1 INTRODUKSJON TIL STATISTIKK Kapittel 1 Populasjon og utvalg 19 Kapittel
ST0202 Statistikk for samfunnsvitere Kapittel 6: Normalfordelingen
 ST0202 Statistikk for samfunnsvitere Kapittel 6: Normalfordelingen Bo Lindqvist Institutt for matematiske fag 2 Kap. 6: Normalfordelingen Normalfordelingen regnes som den viktigste statistiske fordelingen!
ST0202 Statistikk for samfunnsvitere Kapittel 6: Normalfordelingen Bo Lindqvist Institutt for matematiske fag 2 Kap. 6: Normalfordelingen Normalfordelingen regnes som den viktigste statistiske fordelingen!
Tema: Deskriptiv statistikk for kontinuerlige data. Av Kathrine Frey Frøslie,
 Tema: Deskriptiv statistikk for kontinuerlige data. Av Kathrine Frey Frøslie, www.statistrikk.no Kontinuerlige data er målinger som gjøres langs en skala, for eksempel tid, lengde og vekt. Noen ganger
Tema: Deskriptiv statistikk for kontinuerlige data. Av Kathrine Frey Frøslie, www.statistrikk.no Kontinuerlige data er målinger som gjøres langs en skala, for eksempel tid, lengde og vekt. Noen ganger
Medisinsk statistikk Del I høsten 2009:
 Medisinsk statistikk Del I høsten 2009: Kontinuerlige sannsynlighetsfordelinger Pål Romundstad Beregning av sannsynlighet i en binomisk forsøksrekke generelt Sannsynligheten for at suksess intreffer X
Medisinsk statistikk Del I høsten 2009: Kontinuerlige sannsynlighetsfordelinger Pål Romundstad Beregning av sannsynlighet i en binomisk forsøksrekke generelt Sannsynligheten for at suksess intreffer X
Kap. 8: Utvalsfordelingar og databeskrivelse
 Kap. 8: Utvalsfordelingar og databeskrivelse Utvalsfordelingar Utvalsfordeling for gjennomsnitt (med kjent varians) ( X ) Sentralgrenseteoremet (SGT) Utvalsfordeling for varians (normalfordeling) Utvalfordeling
Kap. 8: Utvalsfordelingar og databeskrivelse Utvalsfordelingar Utvalsfordeling for gjennomsnitt (med kjent varians) ( X ) Sentralgrenseteoremet (SGT) Utvalsfordeling for varians (normalfordeling) Utvalfordeling
Forslag til endringar
 Forslag til endringar Bakgrunn: Vi har ingen forelesningar veka etter påske. Eg skal bort 18. og 19. april. Eksamen er 30.mai Forslag til endringar: Ekstra forelesningar onsdag 16.mars og onsdag 30 mars
Forslag til endringar Bakgrunn: Vi har ingen forelesningar veka etter påske. Eg skal bort 18. og 19. april. Eksamen er 30.mai Forslag til endringar: Ekstra forelesningar onsdag 16.mars og onsdag 30 mars
STK1100 våren Normalfordelingen. Normalfordelingen er den viktigste av alle sannsynlighetsfordelinger
 STK00 våren 206 Normalfordelingen Svarer til avsnitt 4.3 i læreboka Geir Storvik Matematisk institutt Universitetet i Oslo Normalfordelingen er den viktigste av alle sannsynlighetsfordelinger Normalfordelingen
STK00 våren 206 Normalfordelingen Svarer til avsnitt 4.3 i læreboka Geir Storvik Matematisk institutt Universitetet i Oslo Normalfordelingen er den viktigste av alle sannsynlighetsfordelinger Normalfordelingen
Diskrete sannsynlighetsfordelinger som histogram. Varians. Histogram og kumulativ sannsynlighet. Forventning (gjennomsnitt) (X=antall mynt i tre kast)
 (X=antall mynt i tre kast)") Diskret sannsynlighetsfordeling (kap 1.1-1.6) Oversikt Utfallsrom (sample space) Sannsynlighetsfordeling Forventning (expectation), E(X), populasjonsgjennomsnitt Bruk av figurer og histogram Binomialfordelingen
Diskret sannsynlighetsfordeling (kap 1.1-1.6) Oversikt Utfallsrom (sample space) Sannsynlighetsfordeling Forventning (expectation), E(X), populasjonsgjennomsnitt Bruk av figurer og histogram Binomialfordelingen
Analyseoversikt, Uke 35
 Analyseoversikt, Uke 35 STK1000 Uke 35, 2016. Studentene forventes å lese Ch 1.1-1.3 i læreboka (MMC). Avsnittet om Stem-and-leaf-plot er ikke pensum. Ulike typer data Kategoriske data MMC: «Kvalitative
Analyseoversikt, Uke 35 STK1000 Uke 35, 2016. Studentene forventes å lese Ch 1.1-1.3 i læreboka (MMC). Avsnittet om Stem-and-leaf-plot er ikke pensum. Ulike typer data Kategoriske data MMC: «Kvalitative
Tabell 1: Beskrivende statistikker for dataene
 Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag Øving nummer 7, blokk II Løsningsskisse Oppgave 1 a) Utfør en beskrivende analyse av datasettet % Data for Trondheim: TRD_mean=mean(TRD);
Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag Øving nummer 7, blokk II Løsningsskisse Oppgave 1 a) Utfør en beskrivende analyse av datasettet % Data for Trondheim: TRD_mean=mean(TRD);
Løsningsforslag ECON 2130 Obligatorisk semesteroppgave 2017 vår
 Løsningsforslag ECON 130 Obligatorisk semesteroppgave 017 vår Andreas Myhre Oppgave 1 1. (i) Siden X og Z er uavhengige, vil den simultane fordelingen mellom X og Z kunne skrives som: f(x, z) = P(X = x
Løsningsforslag ECON 130 Obligatorisk semesteroppgave 017 vår Andreas Myhre Oppgave 1 1. (i) Siden X og Z er uavhengige, vil den simultane fordelingen mellom X og Z kunne skrives som: f(x, z) = P(X = x
Statistisk beskrivelse av enkeltvariabler. SOS1120 Kvantitativ metode. Disposisjon. Datamatrisen. Forelesningsnotater 6. forelesning høsten 2005
 SOS110 Kvantitativ metode Forelesningsnotater 6 forelesning høsten 005 Statistisk beskrivelse av enkeltvariabler (Univariat analyse) Per Arne Tufte Disposisjon Datamatrisen Variabler Datamatrisen Frekvensfordelinger
SOS110 Kvantitativ metode Forelesningsnotater 6 forelesning høsten 005 Statistisk beskrivelse av enkeltvariabler (Univariat analyse) Per Arne Tufte Disposisjon Datamatrisen Variabler Datamatrisen Frekvensfordelinger
UNIVERSITETET I OSLO
 UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i: STK1000 Innføring i anvendt statistikk Eksamensdag: Fredag 28. oktober 2016 Tid for eksamen: 14.00 16.00 Oppgavesettet er på
UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i: STK1000 Innføring i anvendt statistikk Eksamensdag: Fredag 28. oktober 2016 Tid for eksamen: 14.00 16.00 Oppgavesettet er på
ÅMA110 Sannsylighetsregning og statistikk Løsningsforslag til eksamen høst 2010, s. 1. Oppgave 1. Histogram over frekvenser.
 ÅMA1 Sannsylighetsregning og statistikk Løsningsforslag til eksamen høst 0, s. 1 (Det tas forbehold om feil i løsningsforslaget.) a) Gjennomsnitt: x = 1 Emp. standardavvik: Median: 1 (1.33 + 1.) = 1.35
ÅMA1 Sannsylighetsregning og statistikk Løsningsforslag til eksamen høst 0, s. 1 (Det tas forbehold om feil i løsningsforslaget.) a) Gjennomsnitt: x = 1 Emp. standardavvik: Median: 1 (1.33 + 1.) = 1.35
Kapittel 8: Tilfeldige utvalg, databeskrivelse og fordeling til observatorar, Kapittel 9: Estimering
 Kapittel 8: Tilfeldige utvalg, databeskrivelse og fordeling til observatorar, Kapittel 9: Estimering TMA4245 Statistikk Kapittel 8.1-8.5. Kapittel 9.1-9.3+9.15 Turid.Follestad@math.ntnu.no p.1/21 Har sett
Kapittel 8: Tilfeldige utvalg, databeskrivelse og fordeling til observatorar, Kapittel 9: Estimering TMA4245 Statistikk Kapittel 8.1-8.5. Kapittel 9.1-9.3+9.15 Turid.Follestad@math.ntnu.no p.1/21 Har sett
ØVINGER 2017 Løsninger til oppgaver. Øving 1
 ØVINGER 017 Løsninger til oppgaver Øving 1.1. Frekvenstabell For å lage en frekvenstabell må vi telle antall observasjoner av hvert antall henvendelser. Siden antall henvendelser på en gitt dag alltid
ØVINGER 017 Løsninger til oppgaver Øving 1.1. Frekvenstabell For å lage en frekvenstabell må vi telle antall observasjoner av hvert antall henvendelser. Siden antall henvendelser på en gitt dag alltid
Fordelinger, mer om sentralmål og variasjonsmål. Tron Anders Moger
 Fordelinger, mer om sentralmål og variasjonsmål Tron Anders Moger 20. april 2005 1 Forrige gang: Så på et eksempel med data over medisinerstudenter Lærte hvordan man skulle få oversikt over dataene ved
Fordelinger, mer om sentralmål og variasjonsmål Tron Anders Moger 20. april 2005 1 Forrige gang: Så på et eksempel med data over medisinerstudenter Lærte hvordan man skulle få oversikt over dataene ved
Diskrete sannsynlighetsfordelinger som histogram. Varians. Histogram og kumulativ sannsynlighet. Binomial-fordelingen
 Diskret sannsynlighetsfordeling (kap 1.1-1.6) Oversikt Utfallsrom (sample space) Sannsynlighetsfordeling Forventning (expectation), E(, populasjonsgjennomsnitt Bruk av figurer og histogram Binomialfordelingen
Diskret sannsynlighetsfordeling (kap 1.1-1.6) Oversikt Utfallsrom (sample space) Sannsynlighetsfordeling Forventning (expectation), E(, populasjonsgjennomsnitt Bruk av figurer og histogram Binomialfordelingen
Eksempel på data: Karakterer i «Stat class» Introduksjon
 Eksempel på data: Karakterer i «Stat class» Introduksjon Viktige begreper for å beskrive data: Enheter som er objektene i datasettet «label» som av og til brukes for å skille enhetene En variabel er en
Eksempel på data: Karakterer i «Stat class» Introduksjon Viktige begreper for å beskrive data: Enheter som er objektene i datasettet «label» som av og til brukes for å skille enhetene En variabel er en
Introduksjon til statistikk og dataanalyse. Arild Brandrud Næss TMA4240 Statistikk NTNU, høsten 2013
 Introduksjon til statistikk og dataanalyse Arild Brandrud Næss TMA4240 Statistikk NTNU, høsten 2013 Introduksjon til statistikk og dataanalyse Hollywood-filmer fra 2011 135 filmer Samla budsjett: $ 7 166
Introduksjon til statistikk og dataanalyse Arild Brandrud Næss TMA4240 Statistikk NTNU, høsten 2013 Introduksjon til statistikk og dataanalyse Hollywood-filmer fra 2011 135 filmer Samla budsjett: $ 7 166
UNIVERSITETET I OSLO
 UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i STK1000 Innføring i anvendt statistikk. Eksamensdag: Torsdag 9. oktober 2008. Tid for eksamen: 15:00 17:00. Oppgavesettet er på
UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Eksamen i STK1000 Innføring i anvendt statistikk. Eksamensdag: Torsdag 9. oktober 2008. Tid for eksamen: 15:00 17:00. Oppgavesettet er på
ECON2130 Kommentarer til oblig
 ECON2130 Kommentarer til oblig Her har jeg skrevet ganske utfyllende kommentarer til en del oppgaver som mange slet med. Har noen steder gått en del utover det som det strengt tatt ble spurt om i oppgaven,
ECON2130 Kommentarer til oblig Her har jeg skrevet ganske utfyllende kommentarer til en del oppgaver som mange slet med. Har noen steder gått en del utover det som det strengt tatt ble spurt om i oppgaven,
Kapittel 4.4: Forventning og varians til stokastiske variable
 Kapittel 4.4: Forventning og varians til stokastiske variable Forventning og varians til stokastiske variable Histogrammer for observerte data: Sannsynlighets-histogrammer og tetthetskurver for stokastiske
Kapittel 4.4: Forventning og varians til stokastiske variable Forventning og varians til stokastiske variable Histogrammer for observerte data: Sannsynlighets-histogrammer og tetthetskurver for stokastiske
Inferens i fordelinger
 Inferens i fordelinger Modifiserer antagelsen om at standardavviket i populasjonen σ er kjent Mer kompleks systematisk del ( her forventningen i populasjonen). Skal se på en situasjon der populasjonsfordelingen
Inferens i fordelinger Modifiserer antagelsen om at standardavviket i populasjonen σ er kjent Mer kompleks systematisk del ( her forventningen i populasjonen). Skal se på en situasjon der populasjonsfordelingen
Løsningsforslag til obligatorisk oppgave i ECON2130 våren 2014 av Jonas Schenkel.
 Løsningsforslag til obligatorisk oppgave i ECON2130 våren 2014 av Jonas Schenkel. Det er i flere av oppgavene flere fremgangsmåter. Om din måte var riktig burde komme frem i rettingen. A Både X og Y tilfredsstiller
Løsningsforslag til obligatorisk oppgave i ECON2130 våren 2014 av Jonas Schenkel. Det er i flere av oppgavene flere fremgangsmåter. Om din måte var riktig burde komme frem i rettingen. A Både X og Y tilfredsstiller
Forelesning 3. april, 2017
 Forelesning 3. april, 2017 APPENDIX TIL KAP. 6 Sentralgrenseteoremet AVSNITT 6.3 Anvendelser av sentralgrenseteoremet Histogrammer S-kurver Q-Q-plot Diverse eksempler MGF for følger av uavhengige identisk
Forelesning 3. april, 2017 APPENDIX TIL KAP. 6 Sentralgrenseteoremet AVSNITT 6.3 Anvendelser av sentralgrenseteoremet Histogrammer S-kurver Q-Q-plot Diverse eksempler MGF for følger av uavhengige identisk
Oppgaven består av 10 delspørsmål som anbefales å veie like mye. Kommentarer og tallsvar er skrevet inn mellom <<. >>. Oppgave 1
 ECON 0 EKSAMEN 004 VÅR SENSORVEILEDNING Oppgaven består av 0 delspørsmål som anbefales å veie like mye. Kommentarer og tallsvar er skrevet inn mellom
ECON 0 EKSAMEN 004 VÅR SENSORVEILEDNING Oppgaven består av 0 delspørsmål som anbefales å veie like mye. Kommentarer og tallsvar er skrevet inn mellom
Kapittel 3: Studieopplegg
 Oversikt over pensum Kapittel 1: Empirisk fordeling for en variabel o Begrepet fordeling o Mål for senter (gj.snitt, median) + persentiler/kvartiler o Mål for spredning (Standardavvik s, IQR) o Outliere
Oversikt over pensum Kapittel 1: Empirisk fordeling for en variabel o Begrepet fordeling o Mål for senter (gj.snitt, median) + persentiler/kvartiler o Mål for spredning (Standardavvik s, IQR) o Outliere
Øving 1 TMA4240 - Grunnleggende dataanalyse i Matlab
 Øving 1 TMA4240 - Grunnleggende dataanalyse i Matlab For grunnleggende introduksjon til Matlab, se kursets hjemmeside https://wiki.math.ntnu.no/tma4240/2015h/matlab. I denne øvingen skal vi analysere to
Øving 1 TMA4240 - Grunnleggende dataanalyse i Matlab For grunnleggende introduksjon til Matlab, se kursets hjemmeside https://wiki.math.ntnu.no/tma4240/2015h/matlab. I denne øvingen skal vi analysere to
Kapittel 6: Kontinuerlige sannsynlighetsfordelinger
 Kapittel 6: Kontinuerlige sannsynlighetsfordelinger TMA4240 Statistikk (F2 og E7) Foreleses 15. september, 2004. µ µ µ + Basert på slides av Mette Langås p.1/16 6.1 Kontinuerlig uniform fordeling Kontinuerlig
Kapittel 6: Kontinuerlige sannsynlighetsfordelinger TMA4240 Statistikk (F2 og E7) Foreleses 15. september, 2004. µ µ µ + Basert på slides av Mette Langås p.1/16 6.1 Kontinuerlig uniform fordeling Kontinuerlig
TMA4245 Statistikk Eksamen desember 2016
 Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag TMA4245 Statistikk Eksamen desember 2016 Oppgave 1 En bedrift produserer elektriske komponenter. Komponentene kan ha to typer
Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag TMA4245 Statistikk Eksamen desember 2016 Oppgave 1 En bedrift produserer elektriske komponenter. Komponentene kan ha to typer
1 Sec 3-2: Hvordan beskrive senteret i dataene. 2 Sec 3-3: Hvordan beskrive spredningen i dataene
 1 Sec 3-2: Hvordan beskrive senteret i dataene 2 Sec 3-3: Hvordan beskrive spredningen i dataene Todeling av statistikk Deskriptiv statistikk Oppsummering og beskrivelse av den stikkprøven du har. Statistisk
1 Sec 3-2: Hvordan beskrive senteret i dataene 2 Sec 3-3: Hvordan beskrive spredningen i dataene Todeling av statistikk Deskriptiv statistikk Oppsummering og beskrivelse av den stikkprøven du har. Statistisk
TMA4240 Statistikk H2017 [15]
![TMA4240 Statistikk H2017 [15]](/thumbs/104/162215320.jpg "TMA4240 Statistikk H2017 [15]") TMA4240 Statistikk H207 [5] Del 2: Statistisk inferens Populasjon og utvalg [8.] Observatorer og utvalgsfordelinger [8.2-8.3] Fordeling til gjennomsnittet og sentralgrenseteoremet [8.4] Normalplott [8.8]
TMA4240 Statistikk H207 [5] Del 2: Statistisk inferens Populasjon og utvalg [8.] Observatorer og utvalgsfordelinger [8.2-8.3] Fordeling til gjennomsnittet og sentralgrenseteoremet [8.4] Normalplott [8.8]
STK1100 våren Kontinuerlige stokastiske variabler Forventning og varians Momentgenererende funksjoner
 STK1100 våren 2017 Kontinuerlige stokastiske variabler Forventning og varians Momentgenererende funksjoner Svarer til avsnittene 4.1 og 4.2 i læreboka Ørnulf Borgan Matematisk institutt Universitetet i
STK1100 våren 2017 Kontinuerlige stokastiske variabler Forventning og varians Momentgenererende funksjoner Svarer til avsnittene 4.1 og 4.2 i læreboka Ørnulf Borgan Matematisk institutt Universitetet i
(Det tas forbehold om feil i løsningsforslaget.) Oppgave 1
 Oppgave 1") ÅMA1 Sannsylighetsregning og statistikk Løsningsforslag til eksamen vår 2011, s. 1 (Det tas forbehold om feil i løsningsforslaget.) Oppgave 1 a) Data: x 1, x 2, x 3, x 4, x 5 Gjennomsnitt: x = 1 5 (x 1
ÅMA1 Sannsylighetsregning og statistikk Løsningsforslag til eksamen vår 2011, s. 1 (Det tas forbehold om feil i løsningsforslaget.) Oppgave 1 a) Data: x 1, x 2, x 3, x 4, x 5 Gjennomsnitt: x = 1 5 (x 1
ST0202 Statistikk for samfunnsvitere. Bo Lindqvist Institutt for matematiske fag
 ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Lærebok Robert Johnson og Patricia Kuby: Elementary Statistics, 10. utgave 3 Pensumoversikt Kap. 2 Beskrivende statistikk,
ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Lærebok Robert Johnson og Patricia Kuby: Elementary Statistics, 10. utgave 3 Pensumoversikt Kap. 2 Beskrivende statistikk,
Snøtetthet. Institutt for matematiske fag, NTNU 15. august Notat for TMA4240/TMA4245 Statistikk
 Snøtetthet Notat for TMA424/TMA4245 Statistikk Institutt for matematiske fag, NTNU 5. august 22 I forbindelse med varsling av om, klimaforskning og særlig kraftproduksjon er det viktig å kunne anslå hvor
Snøtetthet Notat for TMA424/TMA4245 Statistikk Institutt for matematiske fag, NTNU 5. august 22 I forbindelse med varsling av om, klimaforskning og særlig kraftproduksjon er det viktig å kunne anslå hvor
ST0202 Statistikk for samfunnsvitere
 ST0202 Statistikk for samfunnsvitere Kapittel 2: Beskrivende analyse og presentasjon av data for én variabel Bo Lindqvist Institutt for matematiske fag http://wiki.math.ntnu.no/st0202/2012h/start 2 Grafisk
ST0202 Statistikk for samfunnsvitere Kapittel 2: Beskrivende analyse og presentasjon av data for én variabel Bo Lindqvist Institutt for matematiske fag http://wiki.math.ntnu.no/st0202/2012h/start 2 Grafisk
Medisinsk statistikk Del I høsten 2008:
 Medisinsk statistikk Del I høsten 2008: Kontinuerlige sannsynlighetsfordelinger Pål Romundstad Noen tips Boka Summary etter hvert kapittel forteller hvor dere har vært og hva som er sentralt Øvingene Overdriv
Medisinsk statistikk Del I høsten 2008: Kontinuerlige sannsynlighetsfordelinger Pål Romundstad Noen tips Boka Summary etter hvert kapittel forteller hvor dere har vært og hva som er sentralt Øvingene Overdriv
Lærebok Robert Johnson og Patricia Kuby: Elementary Statistics, 10. utgave. Pensumoversikt. Forelesninger og øvinger
 2 Lærebok Robert Johnson og Patricia Kuby: Elementary Statistics, 10. utgave ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 3 4 Pensumoversikt Forelesninger og øvinger
2 Lærebok Robert Johnson og Patricia Kuby: Elementary Statistics, 10. utgave ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 3 4 Pensumoversikt Forelesninger og øvinger
Ekstreme bølger. Geir Storvik Matematisk institutt, Universitetet i Oslo. 5. mars 2014
 Ekstreme bølger Geir Storvik Matematisk institutt, Universitetet i Oslo 5. mars 2014 Bølger Timesvise max-bølger ved bøye utenfor østkyst av USA (17/12/1991-23/2-1992) Størrelse på bølger varierer sterkt
Ekstreme bølger Geir Storvik Matematisk institutt, Universitetet i Oslo 5. mars 2014 Bølger Timesvise max-bølger ved bøye utenfor østkyst av USA (17/12/1991-23/2-1992) Størrelse på bølger varierer sterkt
Øving 1 TMA4245 - Grunnleggende dataanalyse i Matlab
 Øving 1 TMA4245 - Grunnleggende dataanalyse i Matlab For grunnleggende bruk av Matlab vises til slides fra basisintroduksjon til Matlab som finnes på kursets hjemmeside. I denne øvingen skal vi analysere
Øving 1 TMA4245 - Grunnleggende dataanalyse i Matlab For grunnleggende bruk av Matlab vises til slides fra basisintroduksjon til Matlab som finnes på kursets hjemmeside. I denne øvingen skal vi analysere
TMA4240 Statistikk Høst 2016
 Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag Anbefalt øving 9 Løsningsskisse Oppgave 1 a) Vi lar her Y være antall fugler som kolliderer med vindmølla i løpet av den gitte
Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag Anbefalt øving 9 Løsningsskisse Oppgave 1 a) Vi lar her Y være antall fugler som kolliderer med vindmølla i løpet av den gitte
Sted Gj.snitt Median St.avvik Varians Trondheim 6.86 7.50 6.52 42.49 Værnes 7.07 7.20 6.79 46.05 Oppdal 4.98 5.80 7.00 48.96
 Vår 213 Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag Øving nummer 8, blokk II Matlabøving Løsningsskisse Oppgave 1 a) Ingen løsningsskisse. b) Finn, for hvert datasett,
Vår 213 Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag Øving nummer 8, blokk II Matlabøving Løsningsskisse Oppgave 1 a) Ingen løsningsskisse. b) Finn, for hvert datasett,
Forelesning 7: Store talls lov, sentralgrenseteoremet. Jo Thori Lind
 Forelesning 7: Store talls lov, sentralgrenseteoremet Jo Thori Lind j.t.lind@econ.uio.no Oversikt 1. Estimering av variansen 2. Asymptotisk teori 3. Store talls lov 4. Sentralgrenseteoremet 1.Estimering
Forelesning 7: Store talls lov, sentralgrenseteoremet Jo Thori Lind j.t.lind@econ.uio.no Oversikt 1. Estimering av variansen 2. Asymptotisk teori 3. Store talls lov 4. Sentralgrenseteoremet 1.Estimering
TMA4240 Statistikk H2010
 TMA4240 Statistikk H2010 Statistisk inferens: 9.14: Sannsynlighetsmaksimeringsestimatoren 8.5: Fordeling til gjennomsnittet 9.4: Konfidensintervall for µ (σ kjent) Mette Langaas Foreleses mandag 11.oktober,
TMA4240 Statistikk H2010 Statistisk inferens: 9.14: Sannsynlighetsmaksimeringsestimatoren 8.5: Fordeling til gjennomsnittet 9.4: Konfidensintervall for µ (σ kjent) Mette Langaas Foreleses mandag 11.oktober,
UNIVERSITETET I OSLO Matematisk Institutt
 UNIVERSITETET I OSLO Matematisk Institutt Midtveiseksamen i: STK 1000: Innføring i anvendt statistikk Tid for eksamen: Onsdag 9. oktober 2013, 11:00 13:00 Hjelpemidler: Lærebok, ordliste for STK1000, godkjent
UNIVERSITETET I OSLO Matematisk Institutt Midtveiseksamen i: STK 1000: Innføring i anvendt statistikk Tid for eksamen: Onsdag 9. oktober 2013, 11:00 13:00 Hjelpemidler: Lærebok, ordliste for STK1000, godkjent
Forkurs i kvantitative metoder ILP 2019
 Forkurs i kvantitative metoder ILP 2019 Dag 2. Forkurs som arbeidskrav for kvantitativ deler av PED-3055 Gregor Maxwell og Bent-Cato Hustad Førsteamanuensis i spesialpedagogikk Hva lærte vi i går? Hva
Forkurs i kvantitative metoder ILP 2019 Dag 2. Forkurs som arbeidskrav for kvantitativ deler av PED-3055 Gregor Maxwell og Bent-Cato Hustad Førsteamanuensis i spesialpedagogikk Hva lærte vi i går? Hva
Kapittel 1: Data og fordelinger
 STK Innføring i anvendt statistikk Mandag 8. august 8 Ingrid K. lad I løpet av dette kurset skal dere bli fortrolig med statistisk tenkemåte forstå teori og metoder som ligger bak knappene/menyene i vanlige
STK Innføring i anvendt statistikk Mandag 8. august 8 Ingrid K. lad I løpet av dette kurset skal dere bli fortrolig med statistisk tenkemåte forstå teori og metoder som ligger bak knappene/menyene i vanlige
TMA4240/TMA4245 Statistikk: Oppsummering kontinuerlige sannsynlighetsfordelinger
 TMA4240/TMA4245 Statistikk: Oppsummering kontinuerlige sannsynlighetsfordelinger Kontinuerlig uniform fordeling f() = B A, A B. En kontinuerlig størrelse (vekt, lengde, tid), som aldri kan bli mindre enn
TMA4240/TMA4245 Statistikk: Oppsummering kontinuerlige sannsynlighetsfordelinger Kontinuerlig uniform fordeling f() = B A, A B. En kontinuerlig størrelse (vekt, lengde, tid), som aldri kan bli mindre enn
Statistisk inferens: 9.14: Sannsynlighetsmaksimeringsestimatoren 8.5: Fordeling til gjennomsnittet 9.4: Konfidensintervall for µ (σ kjent)
") TMA440 Statistikk H010 Statistisk inferens: 9.14: Sannsynlighetsmaksimeringsestimatoren 8.5: Fordeling til gjennomsnittet 9.4: Konfidensintervall for µ (σ kjent) Mette Langaas Foreleses mandag 11.oktober,
TMA440 Statistikk H010 Statistisk inferens: 9.14: Sannsynlighetsmaksimeringsestimatoren 8.5: Fordeling til gjennomsnittet 9.4: Konfidensintervall for µ (σ kjent) Mette Langaas Foreleses mandag 11.oktober,
OPPGAVEHEFTE I STK1000 TIL KAPITTEL 5 OG 6. a b
 OPPGAVEHEFTE I STK1000 TIL KAPITTEL 5 OG 6 1. Regneoppgaver til kapittel 5 6 Oppgave 1. Mange som kommer til STK1000 med dårlige erfaringer fra tidligere mattefag er livredd ulikheter, selv om man har
OPPGAVEHEFTE I STK1000 TIL KAPITTEL 5 OG 6 1. Regneoppgaver til kapittel 5 6 Oppgave 1. Mange som kommer til STK1000 med dårlige erfaringer fra tidligere mattefag er livredd ulikheter, selv om man har
ST0202 Statistikk for samfunnsvitere
 ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Kap. 10: Inferens om to populasjoner Situasjon: Vi ønsker å sammenligne to populasjoner med populasjonsgjennomsnitt henholdsvis
ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Kap. 10: Inferens om to populasjoner Situasjon: Vi ønsker å sammenligne to populasjoner med populasjonsgjennomsnitt henholdsvis
1 Section 6-2: Standard normalfordelingen. 2 Section 6-3: Anvendelser av normalfordelingen. 3 Section 6-4: Observator fordeling
 1 Section 6-2: Standard normalfordelingen 2 Section 6-3: Anvendelser av normalfordelingen 3 Section 6-4: Observator fordeling 4 Section 6-5: Sentralgrenseteoremet Oversikt Kapittel 6 Kontinuerlige tilfeldige
1 Section 6-2: Standard normalfordelingen 2 Section 6-3: Anvendelser av normalfordelingen 3 Section 6-4: Observator fordeling 4 Section 6-5: Sentralgrenseteoremet Oversikt Kapittel 6 Kontinuerlige tilfeldige
ST0103 Brukerkurs i statistikk Forelesning 26, 18. november 2016 Kapittel 8: Sammenligning av grupper
 ST0103 Brukerkurs i statistikk Forelesning 26, 18. november 2016 Kapittel 8: Sammenligning av grupper Bo Lindqvist Institutt for matematiske fag 2 Kapittel 8: Sammenligning av grupper Situasjon: Vi ønsker
ST0103 Brukerkurs i statistikk Forelesning 26, 18. november 2016 Kapittel 8: Sammenligning av grupper Bo Lindqvist Institutt for matematiske fag 2 Kapittel 8: Sammenligning av grupper Situasjon: Vi ønsker
Denne uken: kap : Introduksjon til statistisk inferens. - Konfidensintervall - Hypotesetesting - P-verdier - Statistisk signifikans
 Denne uken: kap. 6.1-6.2-6.3: Introduksjon til statistisk inferens - Konfidensintervall - Hypotesetesting - P-verdier - Statistisk signifikans VG 25/9 2011 Statistisk inferens Mål: Trekke konklusjoner
Denne uken: kap. 6.1-6.2-6.3: Introduksjon til statistisk inferens - Konfidensintervall - Hypotesetesting - P-verdier - Statistisk signifikans VG 25/9 2011 Statistisk inferens Mål: Trekke konklusjoner
Eksamensoppgave i TMA4240 Statistikk
 Institutt for matematiske fag Eksamensoppgave i TMA4240 Statistikk Faglig kontakt under eksamen: Mette Langaas a, Ingelin Steinsland b, Geir-Arne Fuglstad c Tlf: a 988 47 649, b 926 63 096, c 452 70 806
Institutt for matematiske fag Eksamensoppgave i TMA4240 Statistikk Faglig kontakt under eksamen: Mette Langaas a, Ingelin Steinsland b, Geir-Arne Fuglstad c Tlf: a 988 47 649, b 926 63 096, c 452 70 806
Formelsamling i medisinsk statistikk
 Formelsamling i medisinsk statistikk Versjon av 6. mai 208 Dette er en formelsamling til O. O. Aalen (red.): Statistiske metoder i medisin og helsefag, Gyldendal, 208. Gjennomsnitt x = n (x + x 2 + x 3
Formelsamling i medisinsk statistikk Versjon av 6. mai 208 Dette er en formelsamling til O. O. Aalen (red.): Statistiske metoder i medisin og helsefag, Gyldendal, 208. Gjennomsnitt x = n (x + x 2 + x 3
Forelening 1, kapittel 4 Stokastiske variable
 Forelening 1, kapittel 4 Stokastiske variable Eksempel X = "antall kron på kast med to mynter (før de er kastet)" Uniformt utfallsrom {MM, MK, KM, KK}. X = x beskriver hendelsen "antall kron på kast med
Forelening 1, kapittel 4 Stokastiske variable Eksempel X = "antall kron på kast med to mynter (før de er kastet)" Uniformt utfallsrom {MM, MK, KM, KK}. X = x beskriver hendelsen "antall kron på kast med
TMA4240 Statistikk H2015
 TMA4240 Statistikk H2015 Kapittel 6: Kontinuerlige sannsynlighetsfordelinger 6.1 Uniform fordeling 6.2-6.3 Normalfordeling Mette Langaas Institutt for matematiske fag, NTNU wiki.math.ntnu.no/emner/tma4240/2015h/start/
TMA4240 Statistikk H2015 Kapittel 6: Kontinuerlige sannsynlighetsfordelinger 6.1 Uniform fordeling 6.2-6.3 Normalfordeling Mette Langaas Institutt for matematiske fag, NTNU wiki.math.ntnu.no/emner/tma4240/2015h/start/
UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet
 UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Underveiseksamen i: STK1000 Innføring i anvendt statistikk. Eksamensdag: Onsdag 22/3, 2006. Tid for eksamen: Kl. 09.00 11.00. Tillatte hjelpemidler:
UNIVERSITETET I OSLO Det matematisk-naturvitenskapelige fakultet Underveiseksamen i: STK1000 Innføring i anvendt statistikk. Eksamensdag: Onsdag 22/3, 2006. Tid for eksamen: Kl. 09.00 11.00. Tillatte hjelpemidler:
Utvalgsfordelinger (Kapittel 5)
") Utvalgsfordelinger (Kapittel 5) Oversikt pensum, fortid og fremtid Eksplorativ data-analyse (Kap 1, 2) Hvordan produsere data (Kap 3) Sannsynlighetsteori (Kap 4) Utvalgsfordelinger til observatorer (Kap
Utvalgsfordelinger (Kapittel 5) Oversikt pensum, fortid og fremtid Eksplorativ data-analyse (Kap 1, 2) Hvordan produsere data (Kap 3) Sannsynlighetsteori (Kap 4) Utvalgsfordelinger til observatorer (Kap
TMA4240 Statistikk Høst 2007
 TMA4240 Statistikk Høst 2007 Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag Øving nummer b4 Løsningsskisse Oppgave 1 Eksamen juni 1999, oppgave 3 av 3 a) µ populasjonsgjennomsnitt,
TMA4240 Statistikk Høst 2007 Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag Øving nummer b4 Løsningsskisse Oppgave 1 Eksamen juni 1999, oppgave 3 av 3 a) µ populasjonsgjennomsnitt,
ST0202 Statistikk for samfunnsvitere. Bo Lindqvist Institutt for matematiske fag
 ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Lærebok Robert Johnson og Patricia Kuby: Elementary Statistics, 10. utgave 3 Pensumoversikt Kap. 2 Beskrivende statistikk,
ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Lærebok Robert Johnson og Patricia Kuby: Elementary Statistics, 10. utgave 3 Pensumoversikt Kap. 2 Beskrivende statistikk,
Løsningsforslag Eksamen i Statistikk SIF5060 Aug 2002
 Løsningsforslag Eksamen i Statistikk SIF5060 Aug 2002 Oppgave 1 a) En god estimator er forventningsrett og har liten varians. Vi tester forventningsretthet: E[ˆµ] E[Y ] µ E[ µ] E[ 1 2 X + 1 2 Y ] 1 2 E[X]
Løsningsforslag Eksamen i Statistikk SIF5060 Aug 2002 Oppgave 1 a) En god estimator er forventningsrett og har liten varians. Vi tester forventningsretthet: E[ˆµ] E[Y ] µ E[ µ] E[ 1 2 X + 1 2 Y ] 1 2 E[X]
ST0202 Statistikk for samfunnsvitere Kapittel 9: Inferens om én populasjon
 ST0202 Statistikk for samfunnsvitere Kapittel 9: Inferens om én populasjon Bo Lindqvist Institutt for matematiske fag 2 Kap. 9: Inferens om én populasjon Statistisk inferens har som mål å tolke/analysere
ST0202 Statistikk for samfunnsvitere Kapittel 9: Inferens om én populasjon Bo Lindqvist Institutt for matematiske fag 2 Kap. 9: Inferens om én populasjon Statistisk inferens har som mål å tolke/analysere
TMA4240 Statistikk H2010
 TMA4240 Statistikk H2010 Statistisk inferens: 8.1: Tilfeldig utvalg 9.1-9.3: Estimering Mette Langaas Foreleses uke 40, 2010 2 Utfordring Ved en bedrift produseres en elektrisk komponent. Komponenten må
TMA4240 Statistikk H2010 Statistisk inferens: 8.1: Tilfeldig utvalg 9.1-9.3: Estimering Mette Langaas Foreleses uke 40, 2010 2 Utfordring Ved en bedrift produseres en elektrisk komponent. Komponenten må
Utfordring. TMA4240 Statistikk H2010. Mette Langaas. Foreleses uke 40, 2010
 TMA4240 Statistikk H2010 Statistisk inferens: 8.1: Tilfeldig utvalg 9.1-9.3: Estimering Mette Langaas Foreleses uke 40, 2010 2 Utfordring Ved en bedrift produseres en elektrisk komponent. Komponenten må
TMA4240 Statistikk H2010 Statistisk inferens: 8.1: Tilfeldig utvalg 9.1-9.3: Estimering Mette Langaas Foreleses uke 40, 2010 2 Utfordring Ved en bedrift produseres en elektrisk komponent. Komponenten må
Estimat og konfidensintervall for andel pasientopphold med minst én pasientskade
 Estimat og konfidensintervall for andel pasient Gjennomsnitt, standardavvik, minimum og maksimum for andel med minst én er beregnet på samme måte som i Tabell 1 på side 20 i «Rapport for Nasjonal Journalundersøkelse
Estimat og konfidensintervall for andel pasient Gjennomsnitt, standardavvik, minimum og maksimum for andel med minst én er beregnet på samme måte som i Tabell 1 på side 20 i «Rapport for Nasjonal Journalundersøkelse
ting å gjøre å prøve å oppsummere informasjonen i Hva som er hensiktsmessig måter å beskrive dataene på en hensiktsmessig måte.
 Kapittel : Beskrivende statistikk Etter at vi har samlet inn data er en naturlig første ting å gjøre å prøve å oppsummere informasjonen i dataene på en hensiktsmessig måte. Hva som er hensiktsmessig måter
Kapittel : Beskrivende statistikk Etter at vi har samlet inn data er en naturlig første ting å gjøre å prøve å oppsummere informasjonen i dataene på en hensiktsmessig måte. Hva som er hensiktsmessig måter
Løsningsforslag til obligatorisk oppgave i ECON 2130
 Andreas Mhre April 15 Løsningsforslag til obligatorisk oppgave i ECON 13 Oppgave 1: E(XY) = E(X(Z X)) Setter inn Y = Z - X E(XY) = E(XZ X ) E(XY) = E(XZ) E(X ) E(XY) = - E(X ) X og Z er uavhengige, så
Andreas Mhre April 15 Løsningsforslag til obligatorisk oppgave i ECON 13 Oppgave 1: E(XY) = E(X(Z X)) Setter inn Y = Z - X E(XY) = E(XZ X ) E(XY) = E(XZ) E(X ) E(XY) = - E(X ) X og Z er uavhengige, så
Sannsynlighetsregning og Statistikk.
 Sannsynlighetsregning og Statistikk. Leksjon Velkommen til dette kurset i sannsynlighetsregning og statistikk! Vi vil som lærebok benytte Gunnar G. Løvås:Statistikk for universiteter og høyskoler. I den
Sannsynlighetsregning og Statistikk. Leksjon Velkommen til dette kurset i sannsynlighetsregning og statistikk! Vi vil som lærebok benytte Gunnar G. Løvås:Statistikk for universiteter og høyskoler. I den
Gammafordelingen og χ 2 -fordelingen
 Gammafordelingen og χ 2 -fordelingen Gammafunksjonen Gammafunksjonen er en funksjon som brukes ofte i sannsynlighetsregning. I mange fordelinger dukker den opp i konstantleddet. Hvis man plotter n-fakultet
Gammafordelingen og χ 2 -fordelingen Gammafunksjonen Gammafunksjonen er en funksjon som brukes ofte i sannsynlighetsregning. I mange fordelinger dukker den opp i konstantleddet. Hvis man plotter n-fakultet
Estimatorar. Torstein Fjeldstad Institutt for matematiske fag, NTNU
 Estimatorar Torstein Fjeldstad Institutt for matematiske fag, NTNU 11.10.2018 I dag Repetisjon Er dataa mine normalfordelt? Estimatorar Eigenskapar til S 2 Kahoot 2 Repetisjon Obervator Ein observator
Estimatorar Torstein Fjeldstad Institutt for matematiske fag, NTNU 11.10.2018 I dag Repetisjon Er dataa mine normalfordelt? Estimatorar Eigenskapar til S 2 Kahoot 2 Repetisjon Obervator Ein observator
Deskriptiv statistikk., Introduksjon til dataanalyse
 Introduksjon til dataanalyse Deskriptiv statistikk 2 Kapittel 1 Denne timen og delvis forrige time er inspirert av Kapittel 1, men vi kommer ikke til å gå igjennom alt fra dette kapittelet i forelesning.
Introduksjon til dataanalyse Deskriptiv statistikk 2 Kapittel 1 Denne timen og delvis forrige time er inspirert av Kapittel 1, men vi kommer ikke til å gå igjennom alt fra dette kapittelet i forelesning.
Utvalgsfordelinger. Utvalg er en tilfeldig mekanisme. Sannsynlighetsregning dreier seg om tilfeldige mekanismer.
 Utvalgsfordelinger Vi har sett at utvalgsfordelinger til en statistikk (observator) er fordelingen av verdiene statistikken tar ved mange gjenttatte utvalg av samme størrelse fra samme populasjon. Utvalg
Utvalgsfordelinger Vi har sett at utvalgsfordelinger til en statistikk (observator) er fordelingen av verdiene statistikken tar ved mange gjenttatte utvalg av samme størrelse fra samme populasjon. Utvalg
Eksamensoppgave i TMA4245 Statistikk
 Institutt for matematiske fag Eksamensoppgave i TMA4245 Statistikk Faglig kontakt under eksamen: Ingelin Steinsland a, Øyvind Bakke b Tlf: a 73 59 02 39, 926 63 096, b 73 59 81 26, 990 41 673 Eksamensdato:
Institutt for matematiske fag Eksamensoppgave i TMA4245 Statistikk Faglig kontakt under eksamen: Ingelin Steinsland a, Øyvind Bakke b Tlf: a 73 59 02 39, 926 63 096, b 73 59 81 26, 990 41 673 Eksamensdato:
Deskriptiv statistikk., Introduksjon til dataanalyse
 Introduksjon til dataanalyse Deskriptiv statistikk 2 Kapittel 1 Denne timen og delvis forrige time er inspirert av Kapittel 1, men vi kommer ikke til å gå igjennom alt fra dette kapittelet i forelesning.
Introduksjon til dataanalyse Deskriptiv statistikk 2 Kapittel 1 Denne timen og delvis forrige time er inspirert av Kapittel 1, men vi kommer ikke til å gå igjennom alt fra dette kapittelet i forelesning.
Illustrasjon av regel 5.19 om sentralgrenseteoremet og litt om heltallskorreksjon (som i eksempel 5.20).
.") Econ 130 HG mars 017 Supplement til forelesningen 7. februar Illustrasjon av regel 5.19 om sentralgrenseteoremet og litt om heltallskorreksjon (som i eksempel 5.0). Regel 5.19 sier at summer, Y X1 X X
Econ 130 HG mars 017 Supplement til forelesningen 7. februar Illustrasjon av regel 5.19 om sentralgrenseteoremet og litt om heltallskorreksjon (som i eksempel 5.0). Regel 5.19 sier at summer, Y X1 X X
ST0202 Statistikk for samfunnsvitere
 ST0202 Statistikk for samfunnsvitere Kapittel 7: Utvalgsfordeling Bo Lindqvist Institutt for matematiske fag 2 Fra kapittel 1: Populasjon Den mengden av individer/objekter som vi ønsker å analysere. Utvalg
ST0202 Statistikk for samfunnsvitere Kapittel 7: Utvalgsfordeling Bo Lindqvist Institutt for matematiske fag 2 Fra kapittel 1: Populasjon Den mengden av individer/objekter som vi ønsker å analysere. Utvalg
ST0202 Statistikk for samfunnsvitere
 ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Kap. 10: Inferens om to populasjoner Situasjon: Det er to populasjoner som vi ønsker å sammenligne. Vi trekker da et utvalg
ST0202 Statistikk for samfunnsvitere Bo Lindqvist Institutt for matematiske fag 2 Kap. 10: Inferens om to populasjoner Situasjon: Det er to populasjoner som vi ønsker å sammenligne. Vi trekker da et utvalg
ÅMA110 Sannsynlighetsregning med statistikk, våren
 ÅMA110 Sannsynlighetsregning med statistikk, våren 2006 Oppsummering Bjørn H. Auestad Institutt for matematikk og naturvitenskap Universitetet i Stavanger 24. april Bjørn H. Auestad Oppsummering våren
ÅMA110 Sannsynlighetsregning med statistikk, våren 2006 Oppsummering Bjørn H. Auestad Institutt for matematikk og naturvitenskap Universitetet i Stavanger 24. april Bjørn H. Auestad Oppsummering våren
LØSNINGSFORSLAG ) = Dvs
 = Dvs") LØSNINGSFORSLAG 12 OPPGAVE 1 D j er differansen mellom måling j med metode A og metode B. D j N(µ D, 0.1 2 ). H 0 : µ D = 0 mot alternativet H 1 : µ D > 0. Vi forkaster om ˆµ D > k Under H 0 er ˆµ D =
LØSNINGSFORSLAG 12 OPPGAVE 1 D j er differansen mellom måling j med metode A og metode B. D j N(µ D, 0.1 2 ). H 0 : µ D = 0 mot alternativet H 1 : µ D > 0. Vi forkaster om ˆµ D > k Under H 0 er ˆµ D =
Simulering med Applet fra boken, av z og t basert på en rekke utvalg av en gitt størrelse n fra N(μ,σ). Illustrerer hvordan estimering av variansen
. Illustrerer hvordan estimering av variansen") Simulering med Applet fra boken, av z og t basert på en rekke utvalg av en gitt størrelse n fra N(μ,σ). Illustrerer hvordan estimering av variansen gir testobservatoren t mer spredning enn testobservatoren
Simulering med Applet fra boken, av z og t basert på en rekke utvalg av en gitt størrelse n fra N(μ,σ). Illustrerer hvordan estimering av variansen gir testobservatoren t mer spredning enn testobservatoren
Oppfriskning av blokk 1 i TMA4240
 Oppfriskning av blokk 1 i TMA4240 Geir-Arne Fuglstad November 21, 2016 2 Hva har vi gjort i dette kurset? Vi har studert to sterkt relaterte grener av matematikk Sannsynlighetsteori: matematisk teori for
Oppfriskning av blokk 1 i TMA4240 Geir-Arne Fuglstad November 21, 2016 2 Hva har vi gjort i dette kurset? Vi har studert to sterkt relaterte grener av matematikk Sannsynlighetsteori: matematisk teori for
TMA4240 Statistikk 2014
 Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag Øving nummer 9, blokk II Løsningsskisse Oppgave Scriptet run confds.m simulerer n data x,..., x n fra en normalfordeling med
Norges teknisk-naturvitenskapelige universitet Institutt for matematiske fag Øving nummer 9, blokk II Løsningsskisse Oppgave Scriptet run confds.m simulerer n data x,..., x n fra en normalfordeling med
Tilfeldige variabler. MAT0100V Sannsynlighetsregning og kombinatorikk
 MAT0100V Sannsynlighetsregning og kombinatorikk Forventning, varians og standardavvik Tilnærming av binomiske sannsynligheter Konfidensintervall Ørnulf Borgan Matematisk institutt Universitetet i Oslo
MAT0100V Sannsynlighetsregning og kombinatorikk Forventning, varians og standardavvik Tilnærming av binomiske sannsynligheter Konfidensintervall Ørnulf Borgan Matematisk institutt Universitetet i Oslo
Løsningsforslag Eksamen S2, våren 2014 Laget av Tommy O. Sist oppdatert: 1. september 2018 Antall sider: 11
 Løsningsforslag Eksamen S, våren 014 Laget av Tommy O. Sist oppdatert: 1. september 018 Antall sider: 11 Finner du matematiske feil, skrivefeil, eller andre typer feil? Dette dokumentet er open-source,
Løsningsforslag Eksamen S, våren 014 Laget av Tommy O. Sist oppdatert: 1. september 018 Antall sider: 11 Finner du matematiske feil, skrivefeil, eller andre typer feil? Dette dokumentet er open-source,
Utvalgsfordelinger (Kapittel 5)
") Utvalgsfordelinger (Kapittel 5) Observator En observator er en funksjon av data for mange individer, for eksempel Gjennomsnitt Andel Stigningstall i regresjonslinje En observator er en tilfeldig variabel
Utvalgsfordelinger (Kapittel 5) Observator En observator er en funksjon av data for mange individer, for eksempel Gjennomsnitt Andel Stigningstall i regresjonslinje En observator er en tilfeldig variabel